
Simple and Multiple Linear Regression
Simple and Multiple Linear Regression
You might also like
- Probability of Corporal Punishment Lack of Resources and Vulnerable StudentsDocument12 pagesProbability of Corporal Punishment Lack of Resources and Vulnerable StudentsYasmine MustafaNo ratings yet
- Linear Model LassoDocument25 pagesLinear Model Lassoneelam sanjeev kumarNo ratings yet
- Module 3 - Regression and Correlation AnalysisDocument54 pagesModule 3 - Regression and Correlation AnalysisAirra Mhae IlaganNo ratings yet
- Machine LearningDocument92 pagesMachine LearningRakesh DwivediNo ratings yet
- Subset Selection and Shrinkage MethodsDocument25 pagesSubset Selection and Shrinkage MethodsLoera619No ratings yet
- Regression AnalysisDocument54 pagesRegression Analysisavirajput1230987No ratings yet
- CH 14Document12 pagesCH 14Piyush rajNo ratings yet
- Normal Distribution and Regression NotesDocument71 pagesNormal Distribution and Regression Notescassandraolson.kya07No ratings yet
- Unit2-Regression NGPDocument81 pagesUnit2-Regression NGPanimehv5500No ratings yet
- Linear Regression-Part 2Document26 pagesLinear Regression-Part 2fathiahNo ratings yet
- Fiches Machine LearningDocument21 pagesFiches Machine LearningRhysand ReNo ratings yet
- Advanced Statistis Ppt1Document29 pagesAdvanced Statistis Ppt1isaganiNo ratings yet
- Linear Regression Analysis For Survey DataDocument28 pagesLinear Regression Analysis For Survey DataMalav ShahNo ratings yet
- Simple Linear RegressionDocument29 pagesSimple Linear RegressionshishirNo ratings yet
- Accuracy Assessment and Confusion MatrixDocument23 pagesAccuracy Assessment and Confusion Matrixamrutamhetre9No ratings yet
- 3 RegressionDocument23 pages3 RegressionJOJO100% (1)
- Chapter 6Document33 pagesChapter 6bashatigabuNo ratings yet
- Lasso and Ridge RegressionDocument30 pagesLasso and Ridge RegressionAartiNo ratings yet
- Regression PDFDocument33 pagesRegression PDF波唐No ratings yet
- UNIT II RegressionDocument59 pagesUNIT II RegressionAshish ChaudharyNo ratings yet
- A2 Physics Error Propagation 001Document14 pagesA2 Physics Error Propagation 001fresh9129No ratings yet
- Calculation of VIFDocument24 pagesCalculation of VIFnikhilmohanrao.ft243032No ratings yet
- Simple Linear RegressionDocument28 pagesSimple Linear Regressionlajwanti jethwaniNo ratings yet
- Inferential StatisticsDocument42 pagesInferential Statisticscw03309133No ratings yet
- Chapter 2 EconometricDocument28 pagesChapter 2 EconometricmukeshNo ratings yet
- Measures of VariabilityDocument71 pagesMeasures of VariabilityRinna Legaspi100% (1)
- HhghiikkkDocument29 pagesHhghiikkkSamarth SharmaNo ratings yet
- Unit 2linear Regression Bayesian LearningDocument49 pagesUnit 2linear Regression Bayesian LearningiamutkarshdubeNo ratings yet
- Linear Regression: Poonam SinghDocument23 pagesLinear Regression: Poonam Singhakhil sharmaNo ratings yet
- RegressionDocument14 pagesRegressionlovesh kumarNo ratings yet
- EDA 4th ModuleDocument26 pagesEDA 4th Module205Abhishek KotagiNo ratings yet
- Dimensionality ReductionDocument19 pagesDimensionality ReductionAtul PatilNo ratings yet
- ADM2304 Multiple Regression Dr. Suren PhansalkerDocument12 pagesADM2304 Multiple Regression Dr. Suren PhansalkerAndrew WatsonNo ratings yet
- ML - Unit 2Document155 pagesML - Unit 2cabhi7789No ratings yet
- Regression AnalysisDocument49 pagesRegression Analysisharshitad1272No ratings yet
- SVM RegressorDocument13 pagesSVM Regressorsrir93616No ratings yet
- SpssDocument26 pagesSpssMaham Durrani100% (1)
- Measures of DispersionDocument17 pagesMeasures of DispersionAthar AslamNo ratings yet
- Model Selection-Handout PDFDocument57 pagesModel Selection-Handout PDFRuixi LinNo ratings yet
- Linear RegressionDocument25 pagesLinear RegressionAlinaNo ratings yet
- Chapter 3 EconometricDocument23 pagesChapter 3 EconometricmukeshNo ratings yet
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
- Concepts - Regression OverviewDocument14 pagesConcepts - Regression Overviewmtemp7489No ratings yet
- Module 4: Regression Shrinkage MethodsDocument5 pagesModule 4: Regression Shrinkage Methods205Abhishek KotagiNo ratings yet
- Logistic RegressionDocument42 pagesLogistic RegressionmaniNo ratings yet
- Week2 Class3Document19 pagesWeek2 Class3Mayra MartinezNo ratings yet
- Unit VDocument27 pagesUnit V05Bala SaatvikNo ratings yet
- Unit - 3 Machine LearningDocument30 pagesUnit - 3 Machine LearningAbhishekNo ratings yet
- SPSS 3 9 23 14Document82 pagesSPSS 3 9 23 14Bader ZawahrehNo ratings yet
- Measures of DispersionDocument51 pagesMeasures of DispersionbapparoyNo ratings yet
- Guideline For Final Year Project - Research Supervision: Faculty of Business, Accountancy and ManagementDocument71 pagesGuideline For Final Year Project - Research Supervision: Faculty of Business, Accountancy and ManagementhudaNo ratings yet
- Week11-Lecture 11ML Algorithms Metrics - UpdatedDocument29 pagesWeek11-Lecture 11ML Algorithms Metrics - UpdatedfgfdgfdgfdNo ratings yet
- Ch.5 Errors During The Measuremen T ProcessDocument82 pagesCh.5 Errors During The Measuremen T ProcessD7ooM_612No ratings yet
- Regression in M.LDocument13 pagesRegression in M.LSaif JuttNo ratings yet
- 4-Accuracy in Forecasting PDFDocument43 pages4-Accuracy in Forecasting PDFAmber KiranNo ratings yet
- Lazy LearningClassification Using Nearest NeighborsDocument36 pagesLazy LearningClassification Using Nearest NeighborsBlue WhaleNo ratings yet
- Lecture 2: MRA and Inference: Dr. Yundan GongDocument52 pagesLecture 2: MRA and Inference: Dr. Yundan GongVIKTORIIANo ratings yet
- To Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityDocument36 pagesTo Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityZeeshan AkhtarNo ratings yet
- CH 03 Wooldridge 6e PPT UpdatedDocument36 pagesCH 03 Wooldridge 6e PPT UpdatednuttawatvNo ratings yet
- Linear ModelsDocument50 pagesLinear ModelsPriyadarshini ChavanNo ratings yet
- Sess03 Dimension Reduction MethodsDocument36 pagesSess03 Dimension Reduction MethodsKriti SinhaNo ratings yet
- Sess02 DataDocument96 pagesSess02 DataKriti SinhaNo ratings yet
- Brand Love and Family PDFDocument15 pagesBrand Love and Family PDFKriti SinhaNo ratings yet
- Brand Love and Family PDFDocument15 pagesBrand Love and Family PDFKriti SinhaNo ratings yet
- CRM at Make My Trip: Jainisha KumawatDocument12 pagesCRM at Make My Trip: Jainisha KumawatKriti SinhaNo ratings yet
- SCBA Chennai MetroDocument13 pagesSCBA Chennai MetroKriti Sinha100% (1)
- (记) ECON6001 F2021 Topic3 1 updatedDocument92 pages(记) ECON6001 F2021 Topic3 1 updatedcqqNo ratings yet
- Manipulating Data With STATADocument7 pagesManipulating Data With STATAVitor HadadNo ratings yet
- JMP SohyunanDocument40 pagesJMP SohyunanpjNo ratings yet
- Chapter 5 ECON NOTESDocument6 pagesChapter 5 ECON NOTESMarkNo ratings yet
- National Culture Impact On Earnings ManagementDocument38 pagesNational Culture Impact On Earnings ManagementtreatrraNo ratings yet
- Interpretation in Multiple RegressionDocument4 pagesInterpretation in Multiple Regressionmekonnenmuez11No ratings yet
- Ecotrix Ecotrix: B.A. Economics (Hons.) (University of Delhi) B.A. Economics (Hons.) (University of Delhi)Document18 pagesEcotrix Ecotrix: B.A. Economics (Hons.) (University of Delhi) B.A. Economics (Hons.) (University of Delhi)Taruna BajajNo ratings yet
- CHapter 5 AcctDocument8 pagesCHapter 5 Accthaile ethioNo ratings yet
- EBE Dummy VariablesDocument9 pagesEBE Dummy VariablesHarsha DuttaNo ratings yet
- Corporate Governance Ratings and Firm PerformanceDocument36 pagesCorporate Governance Ratings and Firm PerformanceBaigalmaa NyamtserenNo ratings yet
- Econometrics For FinanceDocument6 pagesEconometrics For FinanceAksheta GajinkarNo ratings yet
- Chapter IIDocument31 pagesChapter IIAnmut YeshuNo ratings yet
- Lukas Mazal ThesisDocument33 pagesLukas Mazal ThesisAkshay RawatNo ratings yet
- Assignment 5 (Dummy Variable) : Group 1Document28 pagesAssignment 5 (Dummy Variable) : Group 1cleopetra54No ratings yet
- Dummy VariablesDocument2 pagesDummy Variablessaeedawais47No ratings yet
- Marriage Happiness PDFDocument30 pagesMarriage Happiness PDFgae_dNo ratings yet
- PanelDocument93 pagesPaneljjanggu100% (1)
- Regression Models For Quantitative (Numeric) and Qualitative (Categorical) PredictorsDocument12 pagesRegression Models For Quantitative (Numeric) and Qualitative (Categorical) Predictorsram suriNo ratings yet
- Cotter Glass CeilingDocument27 pagesCotter Glass CeilingPau Santa CruzNo ratings yet
- WWW Social Research Methods Net KB Statdesc PHPDocument87 pagesWWW Social Research Methods Net KB Statdesc PHPNexBengson100% (1)
- Kao Chiang Chen (1999) International R&D Spillovers An Application of Estimation and Inference in Panel CointegrationDocument19 pagesKao Chiang Chen (1999) International R&D Spillovers An Application of Estimation and Inference in Panel CointegrationAlejandro Granda SandovalNo ratings yet
- Elton, Gruber, RentzlerDocument12 pagesElton, Gruber, RentzlerTom QuilleNo ratings yet
- A Smart Guide To Dummy VariablesDocument10 pagesA Smart Guide To Dummy VariablesjtthNo ratings yet
- Wage Discrimination: Reduced Form and Structural EstimatesDocument20 pagesWage Discrimination: Reduced Form and Structural EstimatesDonatien FotioNo ratings yet
- Chap 9 Dummy Variable Regression ModelDocument66 pagesChap 9 Dummy Variable Regression ModelSamina AhmeddinNo ratings yet
- Chapter 2 - Quantitative AnalysisDocument244 pagesChapter 2 - Quantitative AnalysisCHAN StephenieNo ratings yet
- Effectiveness of Talent Management StrategiesDocument21 pagesEffectiveness of Talent Management StrategiesYMA StudioNo ratings yet
- The Effect of Tick Size On Volatility, Trader Behavior, and Market QualityDocument37 pagesThe Effect of Tick Size On Volatility, Trader Behavior, and Market QualityKovacs ImreNo ratings yet
- Tutorial Dummy VariablesDocument47 pagesTutorial Dummy VariablesFernandita MirandaNo ratings yet









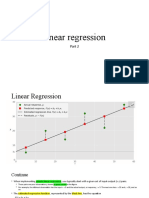





















































































Download as pptx, pdf, or txt
You might also like
- Probability of Corporal Punishment Lack of Resources and Vulnerable StudentsDocument12 pagesProbability of Corporal Punishment Lack of Resources and Vulnerable StudentsYasmine MustafaNo ratings yet
- Linear Model LassoDocument25 pagesLinear Model Lassoneelam sanjeev kumarNo ratings yet
- Module 3 - Regression and Correlation AnalysisDocument54 pagesModule 3 - Regression and Correlation AnalysisAirra Mhae IlaganNo ratings yet
- Machine LearningDocument92 pagesMachine LearningRakesh DwivediNo ratings yet
- Subset Selection and Shrinkage MethodsDocument25 pagesSubset Selection and Shrinkage MethodsLoera619No ratings yet
- Regression AnalysisDocument54 pagesRegression Analysisavirajput1230987No ratings yet
- CH 14Document12 pagesCH 14Piyush rajNo ratings yet
- Normal Distribution and Regression NotesDocument71 pagesNormal Distribution and Regression Notescassandraolson.kya07No ratings yet
- Unit2-Regression NGPDocument81 pagesUnit2-Regression NGPanimehv5500No ratings yet
- Linear Regression-Part 2Document26 pagesLinear Regression-Part 2fathiahNo ratings yet
- Fiches Machine LearningDocument21 pagesFiches Machine LearningRhysand ReNo ratings yet
- Advanced Statistis Ppt1Document29 pagesAdvanced Statistis Ppt1isaganiNo ratings yet
- Linear Regression Analysis For Survey DataDocument28 pagesLinear Regression Analysis For Survey DataMalav ShahNo ratings yet
- Simple Linear RegressionDocument29 pagesSimple Linear RegressionshishirNo ratings yet
- Accuracy Assessment and Confusion MatrixDocument23 pagesAccuracy Assessment and Confusion Matrixamrutamhetre9No ratings yet
- 3 RegressionDocument23 pages3 RegressionJOJO100% (1)
- Chapter 6Document33 pagesChapter 6bashatigabuNo ratings yet
- Lasso and Ridge RegressionDocument30 pagesLasso and Ridge RegressionAartiNo ratings yet
- Regression PDFDocument33 pagesRegression PDF波唐No ratings yet
- UNIT II RegressionDocument59 pagesUNIT II RegressionAshish ChaudharyNo ratings yet
- A2 Physics Error Propagation 001Document14 pagesA2 Physics Error Propagation 001fresh9129No ratings yet
- Calculation of VIFDocument24 pagesCalculation of VIFnikhilmohanrao.ft243032No ratings yet
- Simple Linear RegressionDocument28 pagesSimple Linear Regressionlajwanti jethwaniNo ratings yet
- Inferential StatisticsDocument42 pagesInferential Statisticscw03309133No ratings yet
- Chapter 2 EconometricDocument28 pagesChapter 2 EconometricmukeshNo ratings yet
- Measures of VariabilityDocument71 pagesMeasures of VariabilityRinna Legaspi100% (1)
- HhghiikkkDocument29 pagesHhghiikkkSamarth SharmaNo ratings yet
- Unit 2linear Regression Bayesian LearningDocument49 pagesUnit 2linear Regression Bayesian LearningiamutkarshdubeNo ratings yet
- Linear Regression: Poonam SinghDocument23 pagesLinear Regression: Poonam Singhakhil sharmaNo ratings yet
- RegressionDocument14 pagesRegressionlovesh kumarNo ratings yet
- EDA 4th ModuleDocument26 pagesEDA 4th Module205Abhishek KotagiNo ratings yet
- Dimensionality ReductionDocument19 pagesDimensionality ReductionAtul PatilNo ratings yet
- ADM2304 Multiple Regression Dr. Suren PhansalkerDocument12 pagesADM2304 Multiple Regression Dr. Suren PhansalkerAndrew WatsonNo ratings yet
- ML - Unit 2Document155 pagesML - Unit 2cabhi7789No ratings yet
- Regression AnalysisDocument49 pagesRegression Analysisharshitad1272No ratings yet
- SVM RegressorDocument13 pagesSVM Regressorsrir93616No ratings yet
- SpssDocument26 pagesSpssMaham Durrani100% (1)
- Measures of DispersionDocument17 pagesMeasures of DispersionAthar AslamNo ratings yet
- Model Selection-Handout PDFDocument57 pagesModel Selection-Handout PDFRuixi LinNo ratings yet
- Linear RegressionDocument25 pagesLinear RegressionAlinaNo ratings yet
- Chapter 3 EconometricDocument23 pagesChapter 3 EconometricmukeshNo ratings yet
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
- Concepts - Regression OverviewDocument14 pagesConcepts - Regression Overviewmtemp7489No ratings yet
- Module 4: Regression Shrinkage MethodsDocument5 pagesModule 4: Regression Shrinkage Methods205Abhishek KotagiNo ratings yet
- Logistic RegressionDocument42 pagesLogistic RegressionmaniNo ratings yet
- Week2 Class3Document19 pagesWeek2 Class3Mayra MartinezNo ratings yet
- Unit VDocument27 pagesUnit V05Bala SaatvikNo ratings yet
- Unit - 3 Machine LearningDocument30 pagesUnit - 3 Machine LearningAbhishekNo ratings yet
- SPSS 3 9 23 14Document82 pagesSPSS 3 9 23 14Bader ZawahrehNo ratings yet
- Measures of DispersionDocument51 pagesMeasures of DispersionbapparoyNo ratings yet
- Guideline For Final Year Project - Research Supervision: Faculty of Business, Accountancy and ManagementDocument71 pagesGuideline For Final Year Project - Research Supervision: Faculty of Business, Accountancy and ManagementhudaNo ratings yet
- Week11-Lecture 11ML Algorithms Metrics - UpdatedDocument29 pagesWeek11-Lecture 11ML Algorithms Metrics - UpdatedfgfdgfdgfdNo ratings yet
- Ch.5 Errors During The Measuremen T ProcessDocument82 pagesCh.5 Errors During The Measuremen T ProcessD7ooM_612No ratings yet
- Regression in M.LDocument13 pagesRegression in M.LSaif JuttNo ratings yet
- 4-Accuracy in Forecasting PDFDocument43 pages4-Accuracy in Forecasting PDFAmber KiranNo ratings yet
- Lazy LearningClassification Using Nearest NeighborsDocument36 pagesLazy LearningClassification Using Nearest NeighborsBlue WhaleNo ratings yet
- Lecture 2: MRA and Inference: Dr. Yundan GongDocument52 pagesLecture 2: MRA and Inference: Dr. Yundan GongVIKTORIIANo ratings yet
- To Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityDocument36 pagesTo Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityZeeshan AkhtarNo ratings yet
- CH 03 Wooldridge 6e PPT UpdatedDocument36 pagesCH 03 Wooldridge 6e PPT UpdatednuttawatvNo ratings yet
- Linear ModelsDocument50 pagesLinear ModelsPriyadarshini ChavanNo ratings yet
- Sess03 Dimension Reduction MethodsDocument36 pagesSess03 Dimension Reduction MethodsKriti SinhaNo ratings yet
- Sess02 DataDocument96 pagesSess02 DataKriti SinhaNo ratings yet
- Brand Love and Family PDFDocument15 pagesBrand Love and Family PDFKriti SinhaNo ratings yet
- Brand Love and Family PDFDocument15 pagesBrand Love and Family PDFKriti SinhaNo ratings yet
- CRM at Make My Trip: Jainisha KumawatDocument12 pagesCRM at Make My Trip: Jainisha KumawatKriti SinhaNo ratings yet
- SCBA Chennai MetroDocument13 pagesSCBA Chennai MetroKriti Sinha100% (1)
- (记) ECON6001 F2021 Topic3 1 updatedDocument92 pages(记) ECON6001 F2021 Topic3 1 updatedcqqNo ratings yet
- Manipulating Data With STATADocument7 pagesManipulating Data With STATAVitor HadadNo ratings yet
- JMP SohyunanDocument40 pagesJMP SohyunanpjNo ratings yet
- Chapter 5 ECON NOTESDocument6 pagesChapter 5 ECON NOTESMarkNo ratings yet
- National Culture Impact On Earnings ManagementDocument38 pagesNational Culture Impact On Earnings ManagementtreatrraNo ratings yet
- Interpretation in Multiple RegressionDocument4 pagesInterpretation in Multiple Regressionmekonnenmuez11No ratings yet
- Ecotrix Ecotrix: B.A. Economics (Hons.) (University of Delhi) B.A. Economics (Hons.) (University of Delhi)Document18 pagesEcotrix Ecotrix: B.A. Economics (Hons.) (University of Delhi) B.A. Economics (Hons.) (University of Delhi)Taruna BajajNo ratings yet
- CHapter 5 AcctDocument8 pagesCHapter 5 Accthaile ethioNo ratings yet
- EBE Dummy VariablesDocument9 pagesEBE Dummy VariablesHarsha DuttaNo ratings yet
- Corporate Governance Ratings and Firm PerformanceDocument36 pagesCorporate Governance Ratings and Firm PerformanceBaigalmaa NyamtserenNo ratings yet
- Econometrics For FinanceDocument6 pagesEconometrics For FinanceAksheta GajinkarNo ratings yet
- Chapter IIDocument31 pagesChapter IIAnmut YeshuNo ratings yet
- Lukas Mazal ThesisDocument33 pagesLukas Mazal ThesisAkshay RawatNo ratings yet
- Assignment 5 (Dummy Variable) : Group 1Document28 pagesAssignment 5 (Dummy Variable) : Group 1cleopetra54No ratings yet
- Dummy VariablesDocument2 pagesDummy Variablessaeedawais47No ratings yet
- Marriage Happiness PDFDocument30 pagesMarriage Happiness PDFgae_dNo ratings yet
- PanelDocument93 pagesPaneljjanggu100% (1)
- Regression Models For Quantitative (Numeric) and Qualitative (Categorical) PredictorsDocument12 pagesRegression Models For Quantitative (Numeric) and Qualitative (Categorical) Predictorsram suriNo ratings yet
- Cotter Glass CeilingDocument27 pagesCotter Glass CeilingPau Santa CruzNo ratings yet
- WWW Social Research Methods Net KB Statdesc PHPDocument87 pagesWWW Social Research Methods Net KB Statdesc PHPNexBengson100% (1)
- Kao Chiang Chen (1999) International R&D Spillovers An Application of Estimation and Inference in Panel CointegrationDocument19 pagesKao Chiang Chen (1999) International R&D Spillovers An Application of Estimation and Inference in Panel CointegrationAlejandro Granda SandovalNo ratings yet
- Elton, Gruber, RentzlerDocument12 pagesElton, Gruber, RentzlerTom QuilleNo ratings yet
- A Smart Guide To Dummy VariablesDocument10 pagesA Smart Guide To Dummy VariablesjtthNo ratings yet
- Wage Discrimination: Reduced Form and Structural EstimatesDocument20 pagesWage Discrimination: Reduced Form and Structural EstimatesDonatien FotioNo ratings yet
- Chap 9 Dummy Variable Regression ModelDocument66 pagesChap 9 Dummy Variable Regression ModelSamina AhmeddinNo ratings yet
- Chapter 2 - Quantitative AnalysisDocument244 pagesChapter 2 - Quantitative AnalysisCHAN StephenieNo ratings yet
- Effectiveness of Talent Management StrategiesDocument21 pagesEffectiveness of Talent Management StrategiesYMA StudioNo ratings yet
- The Effect of Tick Size On Volatility, Trader Behavior, and Market QualityDocument37 pagesThe Effect of Tick Size On Volatility, Trader Behavior, and Market QualityKovacs ImreNo ratings yet
- Tutorial Dummy VariablesDocument47 pagesTutorial Dummy VariablesFernandita MirandaNo ratings yet