Download as pptx, pdf, or txt
You might also like
- K-NN (Nearest Neighbor)Document17 pagesK-NN (Nearest Neighbor)Shisir Ahmed100% (1)
- 0.1 Guilherme Marthe - Boston House Pricing ChallengeDocument15 pages0.1 Guilherme Marthe - Boston House Pricing ChallengeGuilherme Marthe100% (1)
- Sheet 1Document3 pagesSheet 1Menna Elsaoudy100% (1)
- Unit-5 Decision Trees and Ensemble LearningDocument162 pagesUnit-5 Decision Trees and Ensemble LearningRahul Vashistha100% (1)
- Classification, PredictionDocument67 pagesClassification, Predictionsindhu gayathri100% (1)
- Unit - 4 Machine LearningDocument84 pagesUnit - 4 Machine LearningRamandeep kaur100% (1)
- Kami Export - 13. Model EvaluationDocument25 pagesKami Export - 13. Model EvaluationYENI SRI MAHARANI -100% (1)
- ML Unit1 PDFDocument36 pagesML Unit1 PDFMohanraj Pramanathan100% (1)
- Fnal+Report Advance+StatisticsDocument44 pagesFnal+Report Advance+StatisticsPranav Viswanathan100% (1)
- CSE 473 Pattern Recognition: Instructor: Dr. Md. Monirul IslamDocument57 pagesCSE 473 Pattern Recognition: Instructor: Dr. Md. Monirul IslamNadia Anjum100% (1)
- PR01Document41 pagesPR01এ.এস. সাকিব100% (1)
- A) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsDocument6 pagesA) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsHassan Saddiqui100% (1)
- IntroductionDocument49 pagesIntroductionEbrahim Daneshifar100% (1)
- Lec 18Document34 pagesLec 18ABHIRAJ E100% (1)
- Handout9 Trees Bagging BoostingDocument23 pagesHandout9 Trees Bagging Boostingmatthiaskoerner19100% (1)
- WINSEM2021-22 CSE4020 ETH VL2021220502460 Reference Material I 02-03-2022 Ensemble Classifier Intro 22Document37 pagesWINSEM2021-22 CSE4020 ETH VL2021220502460 Reference Material I 02-03-2022 Ensemble Classifier Intro 22STYX100% (1)
- ClassificationDocument37 pagesClassificationKingslin Rm100% (1)
- Ensemble ClassifiersDocument37 pagesEnsemble Classifierstwinkz7100% (1)
- An Introduction of Ensemble LearningDocument40 pagesAn Introduction of Ensemble LearningFriday Jones100% (1)
- Everything You Need To Know About Linear RegressionDocument19 pagesEverything You Need To Know About Linear RegressionRohit Umbare100% (1)
- Jntuk R20 ML Unit-IiiDocument21 pagesJntuk R20 ML Unit-IiiMahesh100% (1)
- Classification and PredictionDocument31 pagesClassification and PredictionSharmila Saravanan100% (1)
- ML Lect1Document51 pagesML Lect1physics lover100% (1)
- CS464 Ch9 LinearRegressionDocument43 pagesCS464 Ch9 LinearRegressionOnur Asım İlhan100% (1)
- Presentation GPT 4Document25 pagesPresentation GPT 4Francisco García100% (1)
- Introduction To Scikit LearnDocument108 pagesIntroduction To Scikit LearnRaiyan Zannat100% (1)
- XG Boost PDFDocument3 pagesXG Boost PDFIVAN ALVARO TORRES ROBLES100% (1)
- Pattern ClassificationDocument42 pagesPattern ClassificationTridip Sharma100% (1)
- CS550 Regression Aug12Document63 pagesCS550 Regression Aug12dipsresearch100% (1)
- Outlines: Statements of Problems Objectives Bagging Random Forest Boosting AdaboostDocument14 pagesOutlines: Statements of Problems Objectives Bagging Random Forest Boosting Adaboostendale100% (1)
- To Pattern Recognition: CSE555, Fall 2021 Chapter 1, DHSDocument39 pagesTo Pattern Recognition: CSE555, Fall 2021 Chapter 1, DHSNikhil Gupta100% (1)
- Ensemble MethodsDocument15 pagesEnsemble Methodsbrm1shubha100% (1)
- Bagging and BoostingDocument19 pagesBagging and BoostingAna-Cosmina Popescu100% (1)
- HW1Document8 pagesHW1Anonymous fXSlye100% (1)
- VineeDocument28 pagesVineevineesha28100% (1)
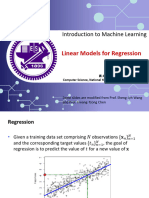
- Chapter-3-Linear Models For RegressionDocument61 pagesChapter-3-Linear Models For Regressionlongfei zhang100% (1)
- Unit V - Classification and Prediction 2020-21Document68 pagesUnit V - Classification and Prediction 2020-21rambabudugyani100% (1)
- Linear - RegressionDocument39 pagesLinear - Regressionhowgibaa100% (1)
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Data ScienceDocument38 pagesData ScienceSiwo Honkai100% (1)
- Basic Ensemble Learning (Random Forest, AdaBoost, Gradient Boosting) - Step by Step ExplainedDocument8 pagesBasic Ensemble Learning (Random Forest, AdaBoost, Gradient Boosting) - Step by Step ExplainedLuciano100% (1)
- Decision and Regression Tree LearningDocument51 pagesDecision and Regression Tree LearningMOOKAMBIGA A100% (1)
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- Linear RegressionDocument27 pagesLinear RegressionJohn Roncoroni100% (1)
- Chapter 2Document25 pagesChapter 2Rajachandra Voodiga100% (1)
- 9 RegressionDocument14 pages9 RegressionAkash Srivastava100% (1)
- WeatherforecastingDocument10 pagesWeatherforecastingLoser To Winner100% (1)
- Univariate and Bivariate Data Analysis + ProbabilityDocument5 pagesUnivariate and Bivariate Data Analysis + ProbabilityBasoko_Leaks100% (1)
- 0.1 Stock DataDocument4 pages0.1 Stock Datayogesh patil100% (1)
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- Hypothesis and Hypothesis TestingDocument59 pagesHypothesis and Hypothesis TestingAreej AlGhamdi100% (1)
- Modelling and EvaluationDocument70 pagesModelling and EvaluationANIMESH KUMARNo ratings yet
- Charmi Shah 20bcp299 Lab2Document7 pagesCharmi Shah 20bcp299 Lab2Princy100% (1)
- SQL Cheat SheetDocument44 pagesSQL Cheat Sheetviany lepro100% (1)
- Project 1 - Radio Link Failure PredictionDocument8 pagesProject 1 - Radio Link Failure PredictionAhmed Belhadj100% (1)
- IRIS BPNN - Ipynb - ColaboratoryDocument4 pagesIRIS BPNN - Ipynb - Colaboratoryrwn data100% (1)
- Lab7.ipynb - ColaboratoryDocument5 pagesLab7.ipynb - ColaboratoryPRAGASM PROG100% (1)
- Python3 CheatsheetDocument6 pagesPython3 CheatsheetLiwj100% (1)
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Decision TreesDocument9 pagesDecision TreesGleny SequiraNo ratings yet
- Formula SheetDocument5 pagesFormula SheetJonelle Morris-DawkinsNo ratings yet
- Astm G16-95Document13 pagesAstm G16-95Bogdan CăpățînăNo ratings yet
- Indomie 2022Document18 pagesIndomie 2022neli zakiyyatun nufusNo ratings yet
- Analisis Deret Waktu SarimaDocument11 pagesAnalisis Deret Waktu SarimaAjeng Jasmine FirdausyNo ratings yet
- 4073Q2 Specimen StatisticsDocument20 pages4073Q2 Specimen StatisticsdvynmashNo ratings yet
- Inferential StaticsDocument33 pagesInferential StaticsJanhavi GuptaNo ratings yet
- Lesson 9. Correlation CoefficientDocument18 pagesLesson 9. Correlation CoefficientDaniela CaguioaNo ratings yet
- Econonometrics Module-1Document160 pagesEcononometrics Module-1Firanbek Bg100% (3)
- Probability and Statistics Symbols TableDocument3 pagesProbability and Statistics Symbols TableChindieyciiEy Lebaiey CwekZrdoghNo ratings yet
- Stat For Business Sem Sum 1516 Final Exam PSUTDocument7 pagesStat For Business Sem Sum 1516 Final Exam PSUTZaina RameNo ratings yet
- Ch.2 The Simple Regression ModelDocument6 pagesCh.2 The Simple Regression ModelRRHMMNo ratings yet
- Lec4 Inferential - Stats - Sampling - Distribution - CorrectDocument28 pagesLec4 Inferential - Stats - Sampling - Distribution - CorrectChrystal RhoneNo ratings yet
- RegresionDocument5 pagesRegresionoscar80% (5)
- MGT601 FormulasDocument8 pagesMGT601 FormulasMuhammad AzamNo ratings yet
- STAT721 Test1 2022 SolutionsDocument5 pagesSTAT721 Test1 2022 SolutionsJacquiline IsaacNo ratings yet
- Practice MC Questions Solutions-Statistics PDFDocument7 pagesPractice MC Questions Solutions-Statistics PDFFarzad TouhidNo ratings yet
- Chapter-4-Simple Linear Regression & CorrelationDocument9 pagesChapter-4-Simple Linear Regression & CorrelationLeni Aug100% (2)
- Artikel - Ni Putu Novita Verdyana PutriDocument19 pagesArtikel - Ni Putu Novita Verdyana PutriNi Putu Novita Verdyana PutriNo ratings yet
- Mean, Median and Mode Grouped DataDocument9 pagesMean, Median and Mode Grouped DataTheo ParrottNo ratings yet
- Ks CorrectDocument13 pagesKs CorrectPriscila GuayasaminNo ratings yet
- Stat QusDocument3 pagesStat QuskarandwaiNo ratings yet
- Lecture 9 - Marketing Mix ModellingDocument62 pagesLecture 9 - Marketing Mix Modellinggagan4790100% (1)
- Ebook Introduction To Behavioral Research Methods 7Th Edition Mark R Leary Online PDF All ChapterDocument69 pagesEbook Introduction To Behavioral Research Methods 7Th Edition Mark R Leary Online PDF All Chapterjames.hackworth412100% (7)
- 15XD25Document3 pages15XD2520PW02 - AKASH ANo ratings yet
- Lecture 3 - Forecasting(s)Document96 pagesLecture 3 - Forecasting(s)Vicaria McDowellNo ratings yet
- MixomicsDocument100 pagesMixomicsmikhaelNo ratings yet
- Problem Set 2Document2 pagesProblem Set 2SOPHIA BEATRIZ UYNo ratings yet
- RegressionDocument25 pagesRegressionABY MOTTY RMCAA20-23No ratings yet
- Naïve Bayes Classifier AlgorithmDocument14 pagesNaïve Bayes Classifier Algorithmshreya sarkarNo ratings yet