Download as pptx, pdf, or txt
You might also like
- 57 Pages - Thesis About Prediction of Cricket Match OutcomeDocument57 pages57 Pages - Thesis About Prediction of Cricket Match OutcomeJehanNo ratings yet
- Prediction of Metabolic Syndrome Using Machine Learning ApproachDocument4 pagesPrediction of Metabolic Syndrome Using Machine Learning ApproachMd Mehedi Hasan RifatNo ratings yet
- E1039207009 21119 1218595455594Document23 pagesE1039207009 21119 1218595455594Ayush TiwariNo ratings yet
- SWE485 - Assignment 2 - 45-2Document2 pagesSWE485 - Assignment 2 - 45-2lay22nNo ratings yet
- Out GameDocument1 pageOut Gamemateuszpopek1234No ratings yet
- 4 Bn-EnDocument25 pages4 Bn-EnhạnhNo ratings yet
- First Rule - Major RuleDocument3 pagesFirst Rule - Major RuleErik LampeNo ratings yet
- An Overview of Decision Tree LearningDocument34 pagesAn Overview of Decision Tree LearningBenazirNo ratings yet
- Module 4 Question Bank: Big Data AnalyticsDocument2 pagesModule 4 Question Bank: Big Data AnalyticsKaushik KapsNo ratings yet
- Decision Trees Example ProblemDocument1 pageDecision Trees Example ProblemMuneeb ButtNo ratings yet
- Datos Jugar TenisDocument1 pageDatos Jugar TenisBrayan RoseroNo ratings yet
- VENUS - Exercise 2Document2 pagesVENUS - Exercise 2Stella Mariz VenusNo ratings yet
- Part Five - Extra PDFDocument27 pagesPart Five - Extra PDFNashowan100% (1)
- A Step by Step ID3 Decision Tree Example by Niranjan Kumar DasDocument8 pagesA Step by Step ID3 Decision Tree Example by Niranjan Kumar DasNiranjan Kumar DasNo ratings yet
- Dataset 1 and 2Document1 pageDataset 1 and 2shirisha gowdaNo ratings yet
- MLA NLP Lecture2Document76 pagesMLA NLP Lecture2shubham choudharyNo ratings yet
- Decision Tree - ID3Document11 pagesDecision Tree - ID3Eman NaeemNo ratings yet
- I 24 Nov 2023 Lab Exam Questions MaterialDocument2 pagesI 24 Nov 2023 Lab Exam Questions Materialthirdmail2021No ratings yet
- Lec5 ActivitiesDocument1 pageLec5 Activitiestin nguyenNo ratings yet
- GolfDocument3 pagesGolfSlamet AchwandiNo ratings yet
- Id 3Document1 pageId 3vuhp1000No ratings yet
- 05 ZeroR OneR Bayes KNNDocument76 pages05 ZeroR OneR Bayes KNNsidra shafiqNo ratings yet
- Bayes Algorithm: Ex1Document8 pagesBayes Algorithm: Ex1Thao PhamNo ratings yet
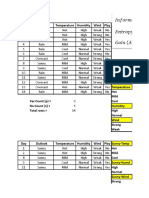
- Outlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoDocument1 pageOutlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoHarshali PatilNo ratings yet
- Aiml Assignment 2Document2 pagesAiml Assignment 2Gem StonesNo ratings yet
- Data Mining: Practical Machine Learning Tools and TechniquesDocument57 pagesData Mining: Practical Machine Learning Tools and TechniquesArvindNo ratings yet
- Naive BayesDocument4 pagesNaive Bayesbhavya.purohit81No ratings yet
- Decision TreeDocument6 pagesDecision TreeshubhNo ratings yet
- Decision TreesDocument28 pagesDecision TreesVijay kumar Gupta .C100% (6)
- Decision Tree Calculation For Play ExampleDocument10 pagesDecision Tree Calculation For Play ExampleParthraj SolankiNo ratings yet
- L4Document19 pagesL4ebrahimsarhan13No ratings yet
- Laboratory 1 Intro To Machine Learning 1Document3 pagesLaboratory 1 Intro To Machine Learning 1Emmanuel AncenoNo ratings yet
- L10 AnnDocument15 pagesL10 AnnNo OneNo ratings yet
- Machine LearningDocument52 pagesMachine LearningaimahsiddNo ratings yet
- Data Mining and Warehousing: Arijit SenguptaDocument60 pagesData Mining and Warehousing: Arijit Senguptaエバン スミドNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument10 pagesNaïve Bayes Classifier Algorithmbhavana vashishthaNo ratings yet
- Basic 06Document14 pagesBasic 06Claudio P. SalvadorNo ratings yet
- Session XIVDocument30 pagesSession XIVRupaliVajpayeeNo ratings yet
- Decision Trees For Classification - A Machine Learning Algorithm - XoriantDocument4 pagesDecision Trees For Classification - A Machine Learning Algorithm - Xoriantmaanav8098No ratings yet
- 1.clase02 Review Weather + SeasonsDocument32 pages1.clase02 Review Weather + SeasonsCatherine HerreraNo ratings yet
- Classification Models-IntuitionDocument17 pagesClassification Models-IntuitionAninda DuttaNo ratings yet
- Decision Tree.10.11Document31 pagesDecision Tree.10.11Oindrila SanyalNo ratings yet
- Data Mining All SlidesDocument206 pagesData Mining All SlidesAmanat ConstructionNo ratings yet
- Decision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmDocument7 pagesDecision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmMohammad SharifNo ratings yet
- MLT NotesDocument66 pagesMLT NotesAryan RajNo ratings yet
- Naive BayesDocument7 pagesNaive BayesfirozNo ratings yet
- Naive BayesDocument10 pagesNaive BayesAbirami NarayananNo ratings yet
- AssignmentDocument1 pageAssignmentProf. Dinesh K VishwakarmaNo ratings yet
- Association Rules L3Document5 pagesAssociation Rules L3u- m-No ratings yet
- NaiveDocument10 pagesNaiveNashowanNo ratings yet
- ML LabDocument9 pagesML Labvgovinda36No ratings yet
- Using Verbs To Describe The WeatherDocument6 pagesUsing Verbs To Describe The WeatherDiana MihaiilovaNo ratings yet
- Rec08 Oct21Document46 pagesRec08 Oct21Grace GaoNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument3 pagesNaïve Bayes Classifier AlgorithmHead Of Department Computer Science and EngineeringNo ratings yet
- Machine Learning 10601 Recitation 8 Oct 21, 2009: Oznur TastanDocument46 pagesMachine Learning 10601 Recitation 8 Oct 21, 2009: Oznur TastanS AswinNo ratings yet
- Play Tennis Example: Outlook Temperature Humidity WindyDocument29 pagesPlay Tennis Example: Outlook Temperature Humidity Windyioi123No ratings yet
- HAI C-06 Jueves 15-10-2020Document34 pagesHAI C-06 Jueves 15-10-2020lizandro verdugo viegasNo ratings yet
- Vocab Pre Unit 7-8Document2 pagesVocab Pre Unit 7-8thutrantranthu99No ratings yet
- 7-Decision Trees LearningDocument51 pages7-Decision Trees Learningyshu1No ratings yet
- MCA3 (DS) Unit 4 MLDocument29 pagesMCA3 (DS) Unit 4 MLRuparel Education Pvt. Ltd.No ratings yet
- LINFO2262: Decision Trees + Random Forests: Pierre DupontDocument43 pagesLINFO2262: Decision Trees + Random Forests: Pierre DupontQuentin LambotteNo ratings yet
- Machine LearningDocument37 pagesMachine LearningPrince RajNo ratings yet
- A Kid's Guide to Weather Forecasting - Weather for Kids | Children's Earth Sciences BooksFrom EverandA Kid's Guide to Weather Forecasting - Weather for Kids | Children's Earth Sciences BooksNo ratings yet
- Cart: Classification and Regression TreeDocument45 pagesCart: Classification and Regression Treecahyadi adityaNo ratings yet
- Text Based Information Retrieval - Document MiningDocument37 pagesText Based Information Retrieval - Document MiningRusli TaherNo ratings yet
- MACHINE LEARNING 1-5 (Ai &DS)Document60 pagesMACHINE LEARNING 1-5 (Ai &DS)Amani yar Khan100% (1)
- Concepts and Techniques: - Chapter 8Document81 pagesConcepts and Techniques: - Chapter 8TotuNo ratings yet
- Machine LearningDocument4 pagesMachine LearningANURAG KUMARNo ratings yet
- PGP-Data Science - Course Module With Internship ModuleDocument17 pagesPGP-Data Science - Course Module With Internship ModuleMehulkumar HireNo ratings yet
- Prediction of Hospital Admission Using Machine LearningDocument9 pagesPrediction of Hospital Admission Using Machine LearningTRIAD TECHNO SERVICESNo ratings yet
- FlightdelayDocument53 pagesFlightdelayabdul rahmanNo ratings yet
- Data Mining - Docx GhhdocxDocument6 pagesData Mining - Docx GhhdocxSiddharth JainNo ratings yet
- Ms. Mehroz Sadiq: 11/23/2020 Bahria University Islamabad 1Document75 pagesMs. Mehroz Sadiq: 11/23/2020 Bahria University Islamabad 1uxamaNo ratings yet
- Assignments TheoryDocument9 pagesAssignments TheoryDragon Ball SuperNo ratings yet
- Machine Learning 4CO250Document2 pagesMachine Learning 4CO250tanujsoniNo ratings yet
- A Cost-Sensitive Decision Tree Approach For Fraud DetectionDocument8 pagesA Cost-Sensitive Decision Tree Approach For Fraud DetectionRodolfo Castro MirandaNo ratings yet
- Chap9 Decision TreeDocument51 pagesChap9 Decision TreeJakhongirNo ratings yet
- Phishing Attacks Detection Using Machine Learning ApproachDocument7 pagesPhishing Attacks Detection Using Machine Learning ApproachPradeep KhaitanNo ratings yet
- Detecting and Classifying Fetal Brain Abnormalities Using Decision Tree AlgorithmDocument6 pagesDetecting and Classifying Fetal Brain Abnormalities Using Decision Tree AlgorithmAttah FrancisNo ratings yet
- Machine Learning BitsDocument28 pagesMachine Learning Bitsvyshnavi100% (2)
- A Study of Machine Learning Algorithms For DDoS DetectionDocument7 pagesA Study of Machine Learning Algorithms For DDoS DetectionIJRASETPublicationsNo ratings yet
- Data Science Training in Naresh I TechnologiesDocument18 pagesData Science Training in Naresh I TechnologiesSANTHAN KUMAR100% (3)
- Machine Learning Super Cheatsheet (Prof. Pedram Jahangiry)Document2 pagesMachine Learning Super Cheatsheet (Prof. Pedram Jahangiry)Adan Nicolas Vasquez SmithNo ratings yet
- The Implementation of Decision Tree Algorithm C4.5 Using Rapidminer in Analyzing Dropout StudentsDocument6 pagesThe Implementation of Decision Tree Algorithm C4.5 Using Rapidminer in Analyzing Dropout StudentsFadhil AsyrafNo ratings yet
- Heart Disease Prediction Model With K-Nearest Neighbor AlgorithmDocument6 pagesHeart Disease Prediction Model With K-Nearest Neighbor AlgorithmIJICT JournalNo ratings yet
- Decision TreeDocument18 pagesDecision TreeMo ShahNo ratings yet
- Data Analysis and Price Prediction of Black Friday Sales Using Machine Learning Techniques IJERTV10IS070271Document8 pagesData Analysis and Price Prediction of Black Friday Sales Using Machine Learning Techniques IJERTV10IS070271Prateek beheraNo ratings yet
- Human Activity RecognizationDocument80 pagesHuman Activity Recognizationbishesh905No ratings yet
- Analysis of Impact of Principal Component Analysis and Feature Selection For Detection of Breast Cancer Using Machine Learning AlgorithmsDocument26 pagesAnalysis of Impact of Principal Component Analysis and Feature Selection For Detection of Breast Cancer Using Machine Learning AlgorithmsMuzungu Hirwa SylvainNo ratings yet
- Pratapa P Evidence of Learning 4Document2 pagesPratapa P Evidence of Learning 4api-532338241No ratings yet