Download as pptx, pdf, or txt
You might also like
- ISYE6501 HW1 KevinDocument7 pagesISYE6501 HW1 KevinKevin FongNo ratings yet
- Delivery Problems at Arrow Electronics, Inc - Group 5 - SectionbDocument17 pagesDelivery Problems at Arrow Electronics, Inc - Group 5 - SectionbJayant BahelNo ratings yet
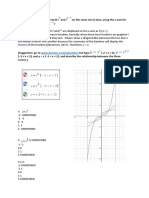
- What Happens If We Graph Both F and F On The Same Set of Axes, Using The X-Axis For The Input Tobothfandf ?Document2 pagesWhat Happens If We Graph Both F and F On The Same Set of Axes, Using The X-Axis For The Input Tobothfandf ?Jakhongir0% (2)
- MACHINE LEARNING Assignment 2Document4 pagesMACHINE LEARNING Assignment 2hadiNo ratings yet
- Unit 4 DA Math 1201Document4 pagesUnit 4 DA Math 1201Jakhongir100% (1)
- Logistic Regression: Prof. Andy FieldDocument34 pagesLogistic Regression: Prof. Andy FieldSyedNo ratings yet
- Lect03 COCOMOIIDocument2 pagesLect03 COCOMOIIFabrisio Nathaniel100% (1)
- Gas Sampling System ManualDocument85 pagesGas Sampling System Manualalexander67% (3)
- SAP - Project WorkDocument63 pagesSAP - Project Workjay_kb100% (3)
- Little Angels' College of Management: Q. Long Question Answer: (25 X 4 100)Document3 pagesLittle Angels' College of Management: Q. Long Question Answer: (25 X 4 100)Suman ChaudharyNo ratings yet
- MEMBA 2017 March 10 Competing On Analytics Part IDocument33 pagesMEMBA 2017 March 10 Competing On Analytics Part IgamallofNo ratings yet
- BIDM Session 07-08Document44 pagesBIDM Session 07-08Ajit chowdaryNo ratings yet
- Chapter 05 Performance - NDocument27 pagesChapter 05 Performance - NHumair NoorNo ratings yet
- 6 EvaluationDocument57 pages6 EvaluationironchefffNo ratings yet
- Logistic Ver 2Document20 pagesLogistic Ver 2Anuj GuptaNo ratings yet
- Classification Problems: - Outcome Is Categorical - E.G. Customer Responds or NotDocument10 pagesClassification Problems: - Outcome Is Categorical - E.G. Customer Responds or NotSiddharth GuptaNo ratings yet
- ML3 Evaluating ModelsDocument40 pagesML3 Evaluating ModelsGonzalo ContrerasNo ratings yet
- Example 1: Hand-Written Digit Recognition: X R X XDocument21 pagesExample 1: Hand-Written Digit Recognition: X R X XAbdul Salam (F-Name: AmanullahNo ratings yet
- FRA Business ReportDocument21 pagesFRA Business ReportSurabhi Kulkarni100% (1)
- Model Answers For Chapter 7: Classification and Regression TreesDocument5 pagesModel Answers For Chapter 7: Classification and Regression TreesTest TestNo ratings yet
- Assignment 6 - Jaime LievanoDocument7 pagesAssignment 6 - Jaime LievanoJaime LievanoNo ratings yet
- 2023-24 AIML ML Mid-Semester Regular QP Anwer-KeysDocument4 pages2023-24 AIML ML Mid-Semester Regular QP Anwer-KeysSabariMurugan SivakumarNo ratings yet
- Pareto Analysis-Inventory ABC Simplified 20160511Document23 pagesPareto Analysis-Inventory ABC Simplified 20160511Yohannes TesfayeNo ratings yet
- MSCI570 - Lecture 8 - Advanced Regression Analysis 2022 Part 2Document26 pagesMSCI570 - Lecture 8 - Advanced Regression Analysis 2022 Part 2Việt Trịnh ĐứcNo ratings yet
- Principal Components Analysis: Hal Whitehead BIOL4062/5062Document29 pagesPrincipal Components Analysis: Hal Whitehead BIOL4062/5062Zahrah_KNo ratings yet
- Unit 4 FMDocument47 pagesUnit 4 FMAlexis ParrisNo ratings yet
- CapstoneDocument785 pagesCapstonenitinbansal321100% (1)
- SlidesDocument13 pagesSlidesanas ejazNo ratings yet
- Pert 4 - Issues of ClassificationDocument53 pagesPert 4 - Issues of ClassificationPenta Al AnsyahNo ratings yet
- Introduction To Numerical AnalysisDocument27 pagesIntroduction To Numerical AnalysisEm ReyesNo ratings yet
- Overview: Production and Cost II: - Opportunity Costs in Practice - Example: Valuing A 1998 Boeing 737-700Document12 pagesOverview: Production and Cost II: - Opportunity Costs in Practice - Example: Valuing A 1998 Boeing 737-700venuputtamrajuNo ratings yet
- CrosstabsDocument10 pagesCrosstabsquynhhuong22102006No ratings yet
- OutputDocument7 pagesOutputJaideep KadianNo ratings yet
- AnswerDocument5 pagesAnswersonali Pradhan100% (3)
- Statistics QuizDocument20 pagesStatistics QuizMohan KoppulaNo ratings yet
- Descriptive Statistics and Probability Distributions: Session 1Document34 pagesDescriptive Statistics and Probability Distributions: Session 1Anyone SomeoneNo ratings yet
- CF 10e Chapter 11 Excel Master StudentDocument32 pagesCF 10e Chapter 11 Excel Master StudentWalter CostaNo ratings yet
- Multiple RegressionDocument25 pagesMultiple RegressionWaseem Javaid SoomroNo ratings yet
- L06 FeaturesDocument44 pagesL06 FeaturesPaulo SantosNo ratings yet
- Anova 1 Jalan OutputDocument14 pagesAnova 1 Jalan OutputRisah AdellaNo ratings yet
- Chi Square of MuthuDocument23 pagesChi Square of MuthuMuthu SelvanNo ratings yet
- Uji Normalitas Data (Ibu)Document6 pagesUji Normalitas Data (Ibu)ardhiNo ratings yet
- HW 14 220Document2 pagesHW 14 220jeff2729608300No ratings yet
- Joins and Cardinality Rmcug May 2013 PresentationDocument20 pagesJoins and Cardinality Rmcug May 2013 PresentationAmit RaiNo ratings yet
- FNCE 370v10: Assignment 1Document15 pagesFNCE 370v10: Assignment 1smaNo ratings yet
- Normal SATA SMART Attrib BehaviourDocument5 pagesNormal SATA SMART Attrib Behaviouraa999666aaaNo ratings yet
- Rcbdexampleslides PDFDocument6 pagesRcbdexampleslides PDFJoan DeLa Cruz VelascoNo ratings yet
- Naive Bayes Model With Python 1684166563Document9 pagesNaive Bayes Model With Python 1684166563mohit c-35No ratings yet
- LAB1NN Group10Document9 pagesLAB1NN Group10Zy AnNo ratings yet
- Macro For The Breaking Point MethodDocument40 pagesMacro For The Breaking Point Methodbing mirandaNo ratings yet
- Spss Terbaru VikaDocument19 pagesSpss Terbaru VikadennyNo ratings yet
- OM Lab CH 17Document29 pagesOM Lab CH 17FLAVIAN BIMAHNo ratings yet
- Case Study - ClassifierDocument5 pagesCase Study - ClassifierStuti SinghNo ratings yet
- FT Mba Section 4b Probability SvaDocument26 pagesFT Mba Section 4b Probability Svacons theNo ratings yet
- CSO504 Machine Learning: Evaluation and Error Analysis Validation and Regularization Koustav Rudra 22/08/2022Document28 pagesCSO504 Machine Learning: Evaluation and Error Analysis Validation and Regularization Koustav Rudra 22/08/2022Being IITianNo ratings yet
- 14 Desember - 127Document16 pages14 Desember - 127ANJALIANTI EKA PITRIYANTI HURNI ADELA UBPNo ratings yet
- L4 - Logistic Regression - BDocument45 pagesL4 - Logistic Regression - BBùi Tấn PhátNo ratings yet
- Tugas Statistik KORELASIDocument20 pagesTugas Statistik KORELASIDenyraNo ratings yet
- Test 101: Testing and DFT Tutorial: Jeff Rearick DFT CoeDocument42 pagesTest 101: Testing and DFT Tutorial: Jeff Rearick DFT CoeBrijesh S DNo ratings yet
- Principles of Corporate Finance 10th Edition Brealey Solutions ManualDocument14 pagesPrinciples of Corporate Finance 10th Edition Brealey Solutions Manualbrainykabassoullw100% (25)
- Tutorial Set 9 SolutionsDocument8 pagesTutorial Set 9 SolutionsRabinNo ratings yet
- Problem Set Ii Finanzas CorporativasDocument19 pagesProblem Set Ii Finanzas CorporativasDamian MamaniNo ratings yet
- FersonDocument48 pagesFersonIrenataNo ratings yet
- Relational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.From EverandRelational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.Rating: 5 out of 5 stars5/5 (1)
- Overview of Data Mining ProcessDocument43 pagesOverview of Data Mining ProcessJakhongirNo ratings yet
- Chap10 Logistic RegressionDocument36 pagesChap10 Logistic RegressionJakhongirNo ratings yet
- Chap15 Cluster AnalysisDocument55 pagesChap15 Cluster AnalysisJakhongirNo ratings yet
- DiscussionDocument2 pagesDiscussionJakhongirNo ratings yet
- Unit4 Discussion Assignment Unit 4 AlgebraDocument3 pagesUnit4 Discussion Assignment Unit 4 AlgebraJakhongirNo ratings yet
- What Happens If We Graph Both and On The Same Set of Axes, Using The X-Axis For The Input To Both and ?Document3 pagesWhat Happens If We Graph Both and On The Same Set of Axes, Using The X-Axis For The Input To Both and ?JakhongirNo ratings yet
- Question: What Happens If We Graph Both And: Composition of Function and Inverse FunctionDocument3 pagesQuestion: What Happens If We Graph Both And: Composition of Function and Inverse FunctionJakhongirNo ratings yet
- DiscussionDocument2 pagesDiscussionJakhongirNo ratings yet
- DF Unit4 Math1201Document3 pagesDF Unit4 Math1201JakhongirNo ratings yet
- Importance of Computerised Accounting in The Effective Management of The Organisation: Case Study Aziccul Credit UnionDocument52 pagesImportance of Computerised Accounting in The Effective Management of The Organisation: Case Study Aziccul Credit UnionPelah Wowen Daniel86% (7)
- enteliWEB 4.20 Operator GuideDocument244 pagesenteliWEB 4.20 Operator GuideGerry GrandboisNo ratings yet
- Public ConventionDocument47 pagesPublic ConventionEduardo CorreiaNo ratings yet
- Time Table Final RevisedDocument6 pagesTime Table Final RevisedSadiq ChiromaNo ratings yet
- User's Guide: GoldcrestDocument13 pagesUser's Guide: GoldcrestErick Garlobo HidalgoNo ratings yet
- Computational Thinking and Tinkering PDFDocument13 pagesComputational Thinking and Tinkering PDFJaime Lozano BNo ratings yet
- 1.1-3 Computer System DesignDocument13 pages1.1-3 Computer System Designsherryll robrigadoNo ratings yet
- Top - Niunaijun.blackboxa33 LogcatDocument3 pagesTop - Niunaijun.blackboxa33 LogcatKssmmxkccn JsbsbdixbddNo ratings yet
- The Operator Breaching and SWAT Edition 2022 PDFDocument84 pagesThe Operator Breaching and SWAT Edition 2022 PDFoMAR100% (2)
- Zte ExchangeDocument15 pagesZte Exchangenaing aung khinNo ratings yet
- Digital System Design: Implementation of Arithmetic Logic UnitDocument9 pagesDigital System Design: Implementation of Arithmetic Logic UnitAL RIZWANNo ratings yet
- Tutorial2 Heavy SupportDocument15 pagesTutorial2 Heavy Supporttarun kumarNo ratings yet
- An Efficient SRAM-based Reconfigurable Architecture For EmbeddedDocument13 pagesAn Efficient SRAM-based Reconfigurable Architecture For EmbeddedDr. Ruqaiya KhanamNo ratings yet
- Algorithms and Flowcharts: A Typical Programming Task Can Be Divided Into Two Phases: - Problem Solving PhaseDocument89 pagesAlgorithms and Flowcharts: A Typical Programming Task Can Be Divided Into Two Phases: - Problem Solving PhaseËnírëhtäc Säntös BälïtëNo ratings yet
- Maps e - TextDocument3 pagesMaps e - TextSutisna RistandiNo ratings yet
- Solar Enclosure System Troubleshooting GuideDocument1 pageSolar Enclosure System Troubleshooting GuideTabishNo ratings yet
- Installation Ima Builder On CpanelDocument4 pagesInstallation Ima Builder On Cpaneldeepakarya1982No ratings yet
- Diagnostic Overview DOC V10 enDocument43 pagesDiagnostic Overview DOC V10 enmichaelNo ratings yet
- Powerpoint Presentation AssignmentDocument3 pagesPowerpoint Presentation AssignmentfalkbgNo ratings yet
- PowerFactory - Software Editions and Licence TypesDocument4 pagesPowerFactory - Software Editions and Licence TypesKishoreNo ratings yet
- Mystic Light Software Development KitDocument8 pagesMystic Light Software Development KitJOSERECON BONILLANo ratings yet
- Nutanix™ Enterprise Cloud With Hpe® Proliant® DX Systems: Use CasesDocument2 pagesNutanix™ Enterprise Cloud With Hpe® Proliant® DX Systems: Use CasesAdi YusupNo ratings yet
- scxx04 scxx07 Spare Parts GuideDocument16 pagesscxx04 scxx07 Spare Parts Guidemink jumperNo ratings yet
- Network Security Research PaperDocument7 pagesNetwork Security Research PaperPankaj Kumar Jha67% (6)
- Ais Chapter 2Document20 pagesAis Chapter 2MC San AntonioNo ratings yet
- CZ4032 Data Analytics & Mining NotesDocument16 pagesCZ4032 Data Analytics & Mining NotesFeng ChengxuanNo ratings yet