
CH 13
CH 13
You might also like
- Peaps: Heaps Implemented Without ArraysDocument12 pagesPeaps: Heaps Implemented Without ArraysHIMYM FangirlNo ratings yet
- Indexing and HashingDocument20 pagesIndexing and HashingMukul DilwariaNo ratings yet
- Chapter 4 IndexingDocument37 pagesChapter 4 IndexingPiyumi SandarekaNo ratings yet
- Database Management System (CSC631) : B+ TreeDocument5 pagesDatabase Management System (CSC631) : B+ Treebharath rajNo ratings yet
- B - TreeDocument46 pagesB - TreeDevinder KumarNo ratings yet
- BCS304-DSA Notes M-4Document25 pagesBCS304-DSA Notes M-4sagar2024kNo ratings yet
- Lec24. Binary Search Tree (BST)Document46 pagesLec24. Binary Search Tree (BST)Majd AL KawaasNo ratings yet
- Trab 1Document22 pagesTrab 1AndréHirosakiNo ratings yet
- B+ Trees: What Are B+ Trees Used For Whatisabtree What Is A B+ Tree Searching Insertion DeletionDocument30 pagesB+ Trees: What Are B+ Trees Used For Whatisabtree What Is A B+ Tree Searching Insertion DeletionAvsec CseNo ratings yet
- DSA MK Lect2 PDFDocument92 pagesDSA MK Lect2 PDFAnkit PriyarupNo ratings yet
- B TreesDocument31 pagesB TreesSathish KumarNo ratings yet
- Binary Search TreesDocument21 pagesBinary Search TreesKing KhanNo ratings yet
- Solution Manual For Introduction To Algorithms, Third Edition by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford SteinDocument31 pagesSolution Manual For Introduction To Algorithms, Third Edition by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Steinbeadleungida100% (6)
- DS Trees Short NotesDocument12 pagesDS Trees Short Notessathvikag001No ratings yet
- CMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat TreesDocument5 pagesCMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat Treesrashed44No ratings yet
- Linked List StructureDocument6 pagesLinked List StructureLuis PinedaNo ratings yet
- Pairing HeapsDocument31 pagesPairing Heapsmanishbhardwaj81310% (1)
- UNIT-5: Indexing and HashingDocument78 pagesUNIT-5: Indexing and HashingcnpnrajaNo ratings yet
- Lect0208 PDFDocument7 pagesLect0208 PDFrandomrandom221No ratings yet
- B-Tree DocumentationDocument12 pagesB-Tree Documentationjiljungjuk737No ratings yet
- LEC 4,5 Linked ListDocument50 pagesLEC 4,5 Linked Listdemro channelNo ratings yet
- PPT6 - Binary Search TreeDocument33 pagesPPT6 - Binary Search TreeRapik HardiantoNo ratings yet
- The B-Tree Index: Prof. Sin-Min Lee Department of Computer Science San Jose State UniversityDocument56 pagesThe B-Tree Index: Prof. Sin-Min Lee Department of Computer Science San Jose State Universitystudyhardgr10No ratings yet
- Binary Search TreesDocument26 pagesBinary Search TreesTomas GenNo ratings yet
- Binary Search Trees-1Document44 pagesBinary Search Trees-1Zuhan MuhammedNo ratings yet
- Splay Tree Splay Trees: Splay of The RootDocument10 pagesSplay Tree Splay Trees: Splay of The RootSimon SylevesNo ratings yet
- A125576137 - 16870 - 20 - 2018 - Searching and SortingDocument167 pagesA125576137 - 16870 - 20 - 2018 - Searching and SortingSri SriNo ratings yet
- XL FiboheapDocument8 pagesXL FiboheapPayal KarolNo ratings yet
- CS 133 - Data Structures and File Organization: Binary TreeDocument66 pagesCS 133 - Data Structures and File Organization: Binary TreeAndrea CatalanNo ratings yet
- Unit06 3 TreesDocument36 pagesUnit06 3 TreesHeera KarimNo ratings yet
- Exam Notes COADocument36 pagesExam Notes COANini P SureshNo ratings yet
- Data Structure Lecture 7 TreeDocument49 pagesData Structure Lecture 7 TreeSweetMainaNo ratings yet
- Unit-2 (Btree InsertionDelection)Document4 pagesUnit-2 (Btree InsertionDelection)Aa ANo ratings yet
- Binary Search Trees and Red-Black TreesDocument55 pagesBinary Search Trees and Red-Black TreesMustafa Alper KÖSENo ratings yet
- Problem Set 4 Solutions: Introduction To AlgorithmsDocument5 pagesProblem Set 4 Solutions: Introduction To Algorithmsrully1234No ratings yet
- Math g4 m5 Topic C Lesson 14Document21 pagesMath g4 m5 Topic C Lesson 14serkan özelNo ratings yet
- CSCI 3100: Algorithms: Homework 0Document2 pagesCSCI 3100: Algorithms: Homework 0Akash FuryNo ratings yet
- Tutorial 2Document5 pagesTutorial 2Miguel DiraneNo ratings yet
- Software Design Using C++: An Online BookDocument11 pagesSoftware Design Using C++: An Online BookNamish MohanNo ratings yet
- Problem Statement For B-Tree: Functionalities: InsertionDocument7 pagesProblem Statement For B-Tree: Functionalities: Insertionprek012_686865590No ratings yet
- Solution Manual For Introduction To Algorithms Third Edition by Thomas H Cormen Charles e Leiserson Ronald L Rivest and Clifford SteinDocument36 pagesSolution Manual For Introduction To Algorithms Third Edition by Thomas H Cormen Charles e Leiserson Ronald L Rivest and Clifford Steinthionineredeyeao9j100% (50)
- Indexing in DBMSDocument12 pagesIndexing in DBMSSravanti BagchiNo ratings yet
- Indexing and Hashing: (Emphasis On B+ Trees)Document23 pagesIndexing and Hashing: (Emphasis On B+ Trees)Goutham TvsNo ratings yet
- Singly Linked ListDocument25 pagesSingly Linked ListJatin DadlaniNo ratings yet
- EscDocument54 pagesEscMohit NagarajNo ratings yet
- 2-3-4 Trees: 2-3-4 Tree (2,4) TreeDocument27 pages2-3-4 Trees: 2-3-4 Tree (2,4) TreeAnonymous Hurq9VKNo ratings yet
- HeapDocument56 pagesHeapAmrinderpal SinghNo ratings yet
- Lecture 3 Python Multivalue Data Types Functions - Hadi - UpdatedDocument52 pagesLecture 3 Python Multivalue Data Types Functions - Hadi - Updatedwael.shaabo61No ratings yet
- Data Structures: 2-3 Trees, B Trees, TRIE TreesDocument41 pagesData Structures: 2-3 Trees, B Trees, TRIE TreesCojocaru IonutNo ratings yet
- IndexingDocument88 pagesIndexingTanisha RathodNo ratings yet
- Solution Manual for Introduction to Algorithms, third edition By Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein download pdf full chapterDocument32 pagesSolution Manual for Introduction to Algorithms, third edition By Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein download pdf full chaptervanchohaget31100% (2)
- Software Design Using C++: An Online BookDocument15 pagesSoftware Design Using C++: An Online BookSaqiba NoushinNo ratings yet
- Dsa24 10Document34 pagesDsa24 10parmarnupur44No ratings yet
- TreeDocument39 pagesTreebirukmes2309No ratings yet
- CS29003 Algorithms Laboratory, Autumn 2013-14: X K y K ZDocument2 pagesCS29003 Algorithms Laboratory, Autumn 2013-14: X K y K ZpiyankNo ratings yet
- Linked ListDocument51 pagesLinked ListTasbiul Hasan Towsif 2131741042No ratings yet
- Binary Search Trees: Welcome To CS221: Programming & Data StructuresDocument37 pagesBinary Search Trees: Welcome To CS221: Programming & Data StructuresPRITAM RAJNo ratings yet
- Data and File Structures: Multi-Level Indexing and B-TreesDocument33 pagesData and File Structures: Multi-Level Indexing and B-TreesVinutha MohanNo ratings yet
- ADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)From EverandADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)No ratings yet
- DBMS LAB Reference ManualDocument105 pagesDBMS LAB Reference ManualSindhu PNo ratings yet
- BALIWANANDocument11 pagesBALIWANANCarol Fernandez Rivera AbellaNo ratings yet
- DBMS SyllabusDocument4 pagesDBMS SyllabusExam helperNo ratings yet
- Thesis Electronic Document Management SystemDocument8 pagesThesis Electronic Document Management Systemtkxajlhld100% (2)
- Oracle: Group Members: Hamza AhmadDocument28 pagesOracle: Group Members: Hamza AhmadUsama QaziNo ratings yet
- Situation Room Information ModelDocument1 pageSituation Room Information Modelssomerville2No ratings yet
- Emebet Bekele 2019Document77 pagesEmebet Bekele 2019amanuel etafaNo ratings yet
- Data Warehouse DesignDocument32 pagesData Warehouse DesignComércio de PortugalNo ratings yet
- Application Programming Interfaces PDFDocument3 pagesApplication Programming Interfaces PDFLUIS GIRALDONo ratings yet
- Data Warehouse/Data Mart: Components Concepts CharacteristicsDocument24 pagesData Warehouse/Data Mart: Components Concepts Characteristicsjkpt1880% (1)
- Omo Sebi Web Based Housing Management SystemDocument12 pagesOmo Sebi Web Based Housing Management SystemAnushi PumbhadiyaNo ratings yet
- Dhuha Rizky Ramadhan DBDDocument6 pagesDhuha Rizky Ramadhan DBDdhuharizkyNo ratings yet
- Dominos PULSE System Module1chapter2Document17 pagesDominos PULSE System Module1chapter2AkhilNo ratings yet
- Ruang Kelas Virtual: Pembelajaran Dengan Pemanfaatan Permainan Online HagoDocument7 pagesRuang Kelas Virtual: Pembelajaran Dengan Pemanfaatan Permainan Online HagoAstiarini ArifinNo ratings yet
- Meta DataDocument42 pagesMeta DataRohan KulkarniNo ratings yet
- Library Management SystemDocument15 pagesLibrary Management SystemarakaviNo ratings yet
- Debahuti Mishra Asst - Prof. Dept - of Computer Sc. & Engg. ITER, SOA University BhubaneswarDocument37 pagesDebahuti Mishra Asst - Prof. Dept - of Computer Sc. & Engg. ITER, SOA University BhubaneswarsarbeswarahotaNo ratings yet
- Sadwika Bobba: Work ExperienceDocument2 pagesSadwika Bobba: Work ExperiencesadwikaNo ratings yet
- Data Management With SASDocument88 pagesData Management With SASmanish_1100% (1)
- INDEXINGABSTRACTINGDocument103 pagesINDEXINGABSTRACTINGJeric CamayaNo ratings yet
- Decision Support SystemsDocument71 pagesDecision Support Systemsmotz71% (7)
- Chapter 2: Introduction To Transaction Processing NotesDocument7 pagesChapter 2: Introduction To Transaction Processing NotesGLECYL BACULIO JAQUILMACNo ratings yet
- COBIT 2019 Design Toolkit With Description - Group X.XLSX - DF9Document8 pagesCOBIT 2019 Design Toolkit With Description - Group X.XLSX - DF9Aulia NisaNo ratings yet
- Aryandono Purwinto /IDN/SEA/CCADocument2 pagesAryandono Purwinto /IDN/SEA/CCAArio WibisonoNo ratings yet
- Azure Hands On TrainingDocument28 pagesAzure Hands On TrainingCharly Tony100% (1)
- Big Data and Analytics: Vincenzo MorabitoDocument202 pagesBig Data and Analytics: Vincenzo MorabitoBhavik SangharNo ratings yet
- Introduction To Database: A A U - AAUDocument15 pagesIntroduction To Database: A A U - AAUthe deanNo ratings yet
- Dbms Lab Set-QpDocument4 pagesDbms Lab Set-QpNithyasri ArumugamNo ratings yet
- Archives and Reference Services: An Annotated Bibliography 1Document11 pagesArchives and Reference Services: An Annotated Bibliography 1Kelly BrooksNo ratings yet
- DAV Practical 7Document3 pagesDAV Practical 7potake7704No ratings yet


















































































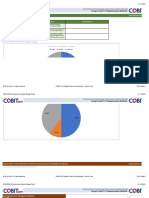






Download as ppt, pdf, or txt
You might also like
- Peaps: Heaps Implemented Without ArraysDocument12 pagesPeaps: Heaps Implemented Without ArraysHIMYM FangirlNo ratings yet
- Indexing and HashingDocument20 pagesIndexing and HashingMukul DilwariaNo ratings yet
- Chapter 4 IndexingDocument37 pagesChapter 4 IndexingPiyumi SandarekaNo ratings yet
- Database Management System (CSC631) : B+ TreeDocument5 pagesDatabase Management System (CSC631) : B+ Treebharath rajNo ratings yet
- B - TreeDocument46 pagesB - TreeDevinder KumarNo ratings yet
- BCS304-DSA Notes M-4Document25 pagesBCS304-DSA Notes M-4sagar2024kNo ratings yet
- Lec24. Binary Search Tree (BST)Document46 pagesLec24. Binary Search Tree (BST)Majd AL KawaasNo ratings yet
- Trab 1Document22 pagesTrab 1AndréHirosakiNo ratings yet
- B+ Trees: What Are B+ Trees Used For Whatisabtree What Is A B+ Tree Searching Insertion DeletionDocument30 pagesB+ Trees: What Are B+ Trees Used For Whatisabtree What Is A B+ Tree Searching Insertion DeletionAvsec CseNo ratings yet
- DSA MK Lect2 PDFDocument92 pagesDSA MK Lect2 PDFAnkit PriyarupNo ratings yet
- B TreesDocument31 pagesB TreesSathish KumarNo ratings yet
- Binary Search TreesDocument21 pagesBinary Search TreesKing KhanNo ratings yet
- Solution Manual For Introduction To Algorithms, Third Edition by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford SteinDocument31 pagesSolution Manual For Introduction To Algorithms, Third Edition by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Steinbeadleungida100% (6)
- DS Trees Short NotesDocument12 pagesDS Trees Short Notessathvikag001No ratings yet
- CMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat TreesDocument5 pagesCMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat Treesrashed44No ratings yet
- Linked List StructureDocument6 pagesLinked List StructureLuis PinedaNo ratings yet
- Pairing HeapsDocument31 pagesPairing Heapsmanishbhardwaj81310% (1)
- UNIT-5: Indexing and HashingDocument78 pagesUNIT-5: Indexing and HashingcnpnrajaNo ratings yet
- Lect0208 PDFDocument7 pagesLect0208 PDFrandomrandom221No ratings yet
- B-Tree DocumentationDocument12 pagesB-Tree Documentationjiljungjuk737No ratings yet
- LEC 4,5 Linked ListDocument50 pagesLEC 4,5 Linked Listdemro channelNo ratings yet
- PPT6 - Binary Search TreeDocument33 pagesPPT6 - Binary Search TreeRapik HardiantoNo ratings yet
- The B-Tree Index: Prof. Sin-Min Lee Department of Computer Science San Jose State UniversityDocument56 pagesThe B-Tree Index: Prof. Sin-Min Lee Department of Computer Science San Jose State Universitystudyhardgr10No ratings yet
- Binary Search TreesDocument26 pagesBinary Search TreesTomas GenNo ratings yet
- Binary Search Trees-1Document44 pagesBinary Search Trees-1Zuhan MuhammedNo ratings yet
- Splay Tree Splay Trees: Splay of The RootDocument10 pagesSplay Tree Splay Trees: Splay of The RootSimon SylevesNo ratings yet
- A125576137 - 16870 - 20 - 2018 - Searching and SortingDocument167 pagesA125576137 - 16870 - 20 - 2018 - Searching and SortingSri SriNo ratings yet
- XL FiboheapDocument8 pagesXL FiboheapPayal KarolNo ratings yet
- CS 133 - Data Structures and File Organization: Binary TreeDocument66 pagesCS 133 - Data Structures and File Organization: Binary TreeAndrea CatalanNo ratings yet
- Unit06 3 TreesDocument36 pagesUnit06 3 TreesHeera KarimNo ratings yet
- Exam Notes COADocument36 pagesExam Notes COANini P SureshNo ratings yet
- Data Structure Lecture 7 TreeDocument49 pagesData Structure Lecture 7 TreeSweetMainaNo ratings yet
- Unit-2 (Btree InsertionDelection)Document4 pagesUnit-2 (Btree InsertionDelection)Aa ANo ratings yet
- Binary Search Trees and Red-Black TreesDocument55 pagesBinary Search Trees and Red-Black TreesMustafa Alper KÖSENo ratings yet
- Problem Set 4 Solutions: Introduction To AlgorithmsDocument5 pagesProblem Set 4 Solutions: Introduction To Algorithmsrully1234No ratings yet
- Math g4 m5 Topic C Lesson 14Document21 pagesMath g4 m5 Topic C Lesson 14serkan özelNo ratings yet
- CSCI 3100: Algorithms: Homework 0Document2 pagesCSCI 3100: Algorithms: Homework 0Akash FuryNo ratings yet
- Tutorial 2Document5 pagesTutorial 2Miguel DiraneNo ratings yet
- Software Design Using C++: An Online BookDocument11 pagesSoftware Design Using C++: An Online BookNamish MohanNo ratings yet
- Problem Statement For B-Tree: Functionalities: InsertionDocument7 pagesProblem Statement For B-Tree: Functionalities: Insertionprek012_686865590No ratings yet
- Solution Manual For Introduction To Algorithms Third Edition by Thomas H Cormen Charles e Leiserson Ronald L Rivest and Clifford SteinDocument36 pagesSolution Manual For Introduction To Algorithms Third Edition by Thomas H Cormen Charles e Leiserson Ronald L Rivest and Clifford Steinthionineredeyeao9j100% (50)
- Indexing in DBMSDocument12 pagesIndexing in DBMSSravanti BagchiNo ratings yet
- Indexing and Hashing: (Emphasis On B+ Trees)Document23 pagesIndexing and Hashing: (Emphasis On B+ Trees)Goutham TvsNo ratings yet
- Singly Linked ListDocument25 pagesSingly Linked ListJatin DadlaniNo ratings yet
- EscDocument54 pagesEscMohit NagarajNo ratings yet
- 2-3-4 Trees: 2-3-4 Tree (2,4) TreeDocument27 pages2-3-4 Trees: 2-3-4 Tree (2,4) TreeAnonymous Hurq9VKNo ratings yet
- HeapDocument56 pagesHeapAmrinderpal SinghNo ratings yet
- Lecture 3 Python Multivalue Data Types Functions - Hadi - UpdatedDocument52 pagesLecture 3 Python Multivalue Data Types Functions - Hadi - Updatedwael.shaabo61No ratings yet
- Data Structures: 2-3 Trees, B Trees, TRIE TreesDocument41 pagesData Structures: 2-3 Trees, B Trees, TRIE TreesCojocaru IonutNo ratings yet
- IndexingDocument88 pagesIndexingTanisha RathodNo ratings yet
- Solution Manual for Introduction to Algorithms, third edition By Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein download pdf full chapterDocument32 pagesSolution Manual for Introduction to Algorithms, third edition By Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein download pdf full chaptervanchohaget31100% (2)
- Software Design Using C++: An Online BookDocument15 pagesSoftware Design Using C++: An Online BookSaqiba NoushinNo ratings yet
- Dsa24 10Document34 pagesDsa24 10parmarnupur44No ratings yet
- TreeDocument39 pagesTreebirukmes2309No ratings yet
- CS29003 Algorithms Laboratory, Autumn 2013-14: X K y K ZDocument2 pagesCS29003 Algorithms Laboratory, Autumn 2013-14: X K y K ZpiyankNo ratings yet
- Linked ListDocument51 pagesLinked ListTasbiul Hasan Towsif 2131741042No ratings yet
- Binary Search Trees: Welcome To CS221: Programming & Data StructuresDocument37 pagesBinary Search Trees: Welcome To CS221: Programming & Data StructuresPRITAM RAJNo ratings yet
- Data and File Structures: Multi-Level Indexing and B-TreesDocument33 pagesData and File Structures: Multi-Level Indexing and B-TreesVinutha MohanNo ratings yet
- ADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)From EverandADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)No ratings yet
- DBMS LAB Reference ManualDocument105 pagesDBMS LAB Reference ManualSindhu PNo ratings yet
- BALIWANANDocument11 pagesBALIWANANCarol Fernandez Rivera AbellaNo ratings yet
- DBMS SyllabusDocument4 pagesDBMS SyllabusExam helperNo ratings yet
- Thesis Electronic Document Management SystemDocument8 pagesThesis Electronic Document Management Systemtkxajlhld100% (2)
- Oracle: Group Members: Hamza AhmadDocument28 pagesOracle: Group Members: Hamza AhmadUsama QaziNo ratings yet
- Situation Room Information ModelDocument1 pageSituation Room Information Modelssomerville2No ratings yet
- Emebet Bekele 2019Document77 pagesEmebet Bekele 2019amanuel etafaNo ratings yet
- Data Warehouse DesignDocument32 pagesData Warehouse DesignComércio de PortugalNo ratings yet
- Application Programming Interfaces PDFDocument3 pagesApplication Programming Interfaces PDFLUIS GIRALDONo ratings yet
- Data Warehouse/Data Mart: Components Concepts CharacteristicsDocument24 pagesData Warehouse/Data Mart: Components Concepts Characteristicsjkpt1880% (1)
- Omo Sebi Web Based Housing Management SystemDocument12 pagesOmo Sebi Web Based Housing Management SystemAnushi PumbhadiyaNo ratings yet
- Dhuha Rizky Ramadhan DBDDocument6 pagesDhuha Rizky Ramadhan DBDdhuharizkyNo ratings yet
- Dominos PULSE System Module1chapter2Document17 pagesDominos PULSE System Module1chapter2AkhilNo ratings yet
- Ruang Kelas Virtual: Pembelajaran Dengan Pemanfaatan Permainan Online HagoDocument7 pagesRuang Kelas Virtual: Pembelajaran Dengan Pemanfaatan Permainan Online HagoAstiarini ArifinNo ratings yet
- Meta DataDocument42 pagesMeta DataRohan KulkarniNo ratings yet
- Library Management SystemDocument15 pagesLibrary Management SystemarakaviNo ratings yet
- Debahuti Mishra Asst - Prof. Dept - of Computer Sc. & Engg. ITER, SOA University BhubaneswarDocument37 pagesDebahuti Mishra Asst - Prof. Dept - of Computer Sc. & Engg. ITER, SOA University BhubaneswarsarbeswarahotaNo ratings yet
- Sadwika Bobba: Work ExperienceDocument2 pagesSadwika Bobba: Work ExperiencesadwikaNo ratings yet
- Data Management With SASDocument88 pagesData Management With SASmanish_1100% (1)
- INDEXINGABSTRACTINGDocument103 pagesINDEXINGABSTRACTINGJeric CamayaNo ratings yet
- Decision Support SystemsDocument71 pagesDecision Support Systemsmotz71% (7)
- Chapter 2: Introduction To Transaction Processing NotesDocument7 pagesChapter 2: Introduction To Transaction Processing NotesGLECYL BACULIO JAQUILMACNo ratings yet
- COBIT 2019 Design Toolkit With Description - Group X.XLSX - DF9Document8 pagesCOBIT 2019 Design Toolkit With Description - Group X.XLSX - DF9Aulia NisaNo ratings yet
- Aryandono Purwinto /IDN/SEA/CCADocument2 pagesAryandono Purwinto /IDN/SEA/CCAArio WibisonoNo ratings yet
- Azure Hands On TrainingDocument28 pagesAzure Hands On TrainingCharly Tony100% (1)
- Big Data and Analytics: Vincenzo MorabitoDocument202 pagesBig Data and Analytics: Vincenzo MorabitoBhavik SangharNo ratings yet
- Introduction To Database: A A U - AAUDocument15 pagesIntroduction To Database: A A U - AAUthe deanNo ratings yet
- Dbms Lab Set-QpDocument4 pagesDbms Lab Set-QpNithyasri ArumugamNo ratings yet
- Archives and Reference Services: An Annotated Bibliography 1Document11 pagesArchives and Reference Services: An Annotated Bibliography 1Kelly BrooksNo ratings yet
- DAV Practical 7Document3 pagesDAV Practical 7potake7704No ratings yet