Download as pptx, pdf, or txt
You might also like
- Full Download Test Bank For Introductory Econometrics A Modern Approach 7th Edition Jeffrey M Wooldridge PDF Full ChapterDocument36 pagesFull Download Test Bank For Introductory Econometrics A Modern Approach 7th Edition Jeffrey M Wooldridge PDF Full Chaptersuzannejohnsonncpgitzjyb100% (21)
- Chapter5 - Machine LearningDocument37 pagesChapter5 - Machine Learninguttkarsh singhNo ratings yet
- Module 3Document79 pagesModule 3beebeefathimabagum435No ratings yet
- Unit 3Document41 pagesUnit 3Venkatesh SharmaNo ratings yet
- 3.popular Machine Learning AlgorithmDocument11 pages3.popular Machine Learning AlgorithmMuhammad ShoaibNo ratings yet
- Machine Learning PptsDocument38 pagesMachine Learning PptsSrujana PrasadiNo ratings yet
- 2B Naive BayesDocument90 pages2B Naive Bayesanimehv5500No ratings yet
- Week 1Document24 pagesWeek 1Priyesh SakreNo ratings yet
- Primer On Major Data Mining AlgorithmsDocument86 pagesPrimer On Major Data Mining AlgorithmsVikram SankhalaNo ratings yet
- Unit 5Document28 pagesUnit 5Prathmesh Mane DeshmukhNo ratings yet
- Recommendation SystemsDocument27 pagesRecommendation SystemsRexline S JNo ratings yet
- Ensemble Learning MethodsDocument24 pagesEnsemble Learning Methodskhatri81100% (1)
- Chap2 SupervisedLearningDocument24 pagesChap2 SupervisedLearningNguyễn Phương NamNo ratings yet
- Unit1 6thsemCSDocument22 pagesUnit1 6thsemCSsaloniNo ratings yet
- Data Science Intervieew QuestionsDocument16 pagesData Science Intervieew QuestionsSatyam Anand100% (1)
- svm unit3Document23 pagessvm unit3aarclguse25No ratings yet
- UNIT 2 - NotesDocument31 pagesUNIT 2 - Notes126Monish BNo ratings yet
- ML Assignment 2 PDFDocument9 pagesML Assignment 2 PDFAnubhav MongaNo ratings yet
- Machine Learning: 1. Write Shorts Notes On: Bernoulli Naivebayes. (Unit 4)Document17 pagesMachine Learning: 1. Write Shorts Notes On: Bernoulli Naivebayes. (Unit 4)Ananya SwaminathanNo ratings yet
- SVM Using PythonDocument24 pagesSVM Using PythonRavindra AmbilwadeNo ratings yet
- AlgorithmsDocument5 pagesAlgorithmsmattmck0813No ratings yet
- 11 Most Common Machine Learning Algorithms Explained in A Nutshell by Soner Yıldırım Towards Data ScienceDocument16 pages11 Most Common Machine Learning Algorithms Explained in A Nutshell by Soner Yıldırım Towards Data ScienceDheeraj SonkhlaNo ratings yet
- Unit 2Document37 pagesUnit 2PoornaNo ratings yet
- A Preliminary Idea On Machine LearningDocument40 pagesA Preliminary Idea On Machine LearningAvijit BoseNo ratings yet
- Data Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Document32 pagesData Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Rule2No ratings yet
- SVM PresentationDocument27 pagesSVM Presentationneeraj12121No ratings yet
- Asign-3 DWDMDocument27 pagesAsign-3 DWDMRohilla JatinNo ratings yet
- Clustering (Unit 3)Document71 pagesClustering (Unit 3)vedang maheshwari100% (1)
- Module III - Simulation Scenarios - C1Document179 pagesModule III - Simulation Scenarios - C1LalithkumarNo ratings yet
- Unit - 4 Machine LearningDocument84 pagesUnit - 4 Machine LearningRamandeep kaur100% (1)
- Data Science Vijay1Document88 pagesData Science Vijay1chathuryaphotos07No ratings yet
- ML Unit-2Document16 pagesML Unit-2Somaraju AkkimsettiNo ratings yet
- Essentials of Machine Learning AlgorithmsDocument15 pagesEssentials of Machine Learning AlgorithmsAndres ValenciaNo ratings yet
- Machine Learning TheoryDocument12 pagesMachine Learning TheoryairplaneunderwaterNo ratings yet
- AlgorithmDocument27 pagesAlgorithmVipin RajputNo ratings yet
- DWDMDocument20 pagesDWDMRavindra KumarNo ratings yet
- Machine Learning Algorithms For Breast Cancer PredictionDocument8 pagesMachine Learning Algorithms For Breast Cancer PredictionVartika AnandNo ratings yet
- On Unit-3Document30 pagesOn Unit-3Nihar Ranjan Prusty 92No ratings yet
- Inductive Learning and Machine LearningDocument321 pagesInductive Learning and Machine Learningj100% (1)
- Unit 2Document89 pagesUnit 2luckyqwe764No ratings yet
- Top 10 Machine Learning Algorithms With Their UseDocument12 pagesTop 10 Machine Learning Algorithms With Their Useirma komariahNo ratings yet
- DuongToGiangSon 517H0162 HW2 Nov-26Document17 pagesDuongToGiangSon 517H0162 HW2 Nov-26Son TranNo ratings yet
- UNIT2SVMKNNDocument31 pagesUNIT2SVMKNNAditya SharmaNo ratings yet
- Unit-2: Logistic RegressionDocument30 pagesUnit-2: Logistic Regressionjas deepNo ratings yet
- MLunit 2 MynotesDocument15 pagesMLunit 2 MynotesVali BhashaNo ratings yet
- Machine Learning QNADocument1 pageMachine Learning QNApratikmovie999No ratings yet
- Ds Module 5Document49 pagesDs Module 5Prathik SrinivasNo ratings yet
- Unit 4 - Machine Learning PDFDocument49 pagesUnit 4 - Machine Learning PDFtest testNo ratings yet
- Machine Learning Fundamentals (Updated)Document42 pagesMachine Learning Fundamentals (Updated)slowkimoNo ratings yet
- Machine Learning TypesDocument30 pagesMachine Learning Typesmalikhaid3raliNo ratings yet
- Data Science Technical Interview QuestionsDocument24 pagesData Science Technical Interview Questionspablo.villegas.millsNo ratings yet
- Machine Learning With Real Life Project: by - Rishabh GaurDocument26 pagesMachine Learning With Real Life Project: by - Rishabh GaurRishab Gaur100% (2)
- Unit 4 Supervised LearningDocument75 pagesUnit 4 Supervised LearningSoumya MishraNo ratings yet
- 1.1 Proposed Algorithms 1.1.1 Random Forest Algorithm: Ensemble LearningDocument81 pages1.1 Proposed Algorithms 1.1.1 Random Forest Algorithm: Ensemble LearningVijay ReddyNo ratings yet
- Inductive Learning and Machine LearningDocument321 pagesInductive Learning and Machine LearningjNo ratings yet
- Classification and Prediction Lecture-22,23,24,25,26,27, 28: Dr. Sudhir Sharma Manipal University JaipurDocument43 pagesClassification and Prediction Lecture-22,23,24,25,26,27, 28: Dr. Sudhir Sharma Manipal University JaipurAatmaj SalunkeNo ratings yet
- Machine Learning: Dr. Windhya Rankothge (PHD - Upf, Barcelona)Document44 pagesMachine Learning: Dr. Windhya Rankothge (PHD - Upf, Barcelona)Ayola JayamahaNo ratings yet
- Unit 3Document99 pagesUnit 3Sai ManasaNo ratings yet
- DWM Exp 5,219Document12 pagesDWM Exp 5,219Mayur PawadeNo ratings yet
- Introduction To StatisticsDocument42 pagesIntroduction To StatisticsGeetu SodhiNo ratings yet
- Fast Sequential Monte Carlo Methods for Counting and OptimizationFrom EverandFast Sequential Monte Carlo Methods for Counting and OptimizationNo ratings yet
- Trend Line, Volume, Supports & ResistancesDocument6 pagesTrend Line, Volume, Supports & ResistancesDilip SinghNo ratings yet
- Stock Market Chart Technical AnalysisDocument8 pagesStock Market Chart Technical AnalysisDilip SinghNo ratings yet
- Foundations of Machine LearningDocument15 pagesFoundations of Machine LearningDilip SinghNo ratings yet
- Basics of Machine LearningDocument47 pagesBasics of Machine LearningDilip SinghNo ratings yet
- RPS Paragraph WritingDocument5 pagesRPS Paragraph WritingNurul FitriNo ratings yet
- Mme 8201-4-Linear Regression ModelsDocument24 pagesMme 8201-4-Linear Regression ModelsJosephat KalanziNo ratings yet
- #HW2 - Tran Thi Thanh HoaDocument7 pages#HW2 - Tran Thi Thanh HoaThanh Hoa TrầnNo ratings yet
- Measurement Scales For ResearchDocument28 pagesMeasurement Scales For ResearchNavjot PannuNo ratings yet
- Presentation 4Document22 pagesPresentation 4Shuvo DattaNo ratings yet
- Types of Data AnalyticsDocument3 pagesTypes of Data AnalyticsSHIVANI S MNo ratings yet
- Ferraro, Nakamoto, Brown - 2003 - Introductory Raman Spectroscopy Second EditionDocument4 pagesFerraro, Nakamoto, Brown - 2003 - Introductory Raman Spectroscopy Second EditionMax Jordan DooleyNo ratings yet
- Data Analysis Stats 2Document13 pagesData Analysis Stats 2Sagar GichkiNo ratings yet
- Elementary Statistics ReviewerDocument12 pagesElementary Statistics ReviewerChristian ChavezNo ratings yet
- Variable SamplingDocument35 pagesVariable SamplingJonathan VidarNo ratings yet
- Minitab Randomized Block DesignsDocument2 pagesMinitab Randomized Block DesignsAZ NdingwanNo ratings yet
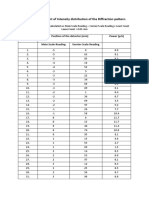
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- SGU 2922 Methodology: Faculty of Geoinformation and Real Estate Universiti Teknologi MalaysiaDocument25 pagesSGU 2922 Methodology: Faculty of Geoinformation and Real Estate Universiti Teknologi MalaysiaCaley Jousie AminNo ratings yet
- Om 1 Special Topics in Operations Management/ Operations Management Chapter 10: Quality ControlDocument2 pagesOm 1 Special Topics in Operations Management/ Operations Management Chapter 10: Quality ControlRoseanne Binayao LontianNo ratings yet
- Assignment BRMDocument6 pagesAssignment BRMMuhammad Adnan KhurshidNo ratings yet
- Edexcel GCE: Statistics S4Document24 pagesEdexcel GCE: Statistics S4yvg95No ratings yet
- Research Unit 4Document53 pagesResearch Unit 4Balamuralikrishna RNo ratings yet
- MPA-II Assignment Reflections On The Methodology (Ies) Adopted in Case Study 2Document2 pagesMPA-II Assignment Reflections On The Methodology (Ies) Adopted in Case Study 2Vungrhonthung PattonNo ratings yet
- CSS 112 - 0 PDFDocument197 pagesCSS 112 - 0 PDFWilliams EmmanuelNo ratings yet
- Experimentul Stanford/ Stanford Prison Experiment: Forensic Science Forum / Forum CriminalisticDocument6 pagesExperimentul Stanford/ Stanford Prison Experiment: Forensic Science Forum / Forum CriminalisticBiancaRusuNo ratings yet
- T Test PaperDocument16 pagesT Test PaperSanya GoelNo ratings yet
- Fineng 508 hw1Document7 pagesFineng 508 hw1Rutviz ParekhNo ratings yet
- Distribution Channel Management BirlaDocument60 pagesDistribution Channel Management BirlaAbhay JainNo ratings yet
- Zahra Ratu Audia - (17821107) - Praktikum 4Document6 pagesZahra Ratu Audia - (17821107) - Praktikum 4INFIRES MANNo ratings yet
- 1639 GCS190753 PhamCongMinh Assignment2Document28 pages1639 GCS190753 PhamCongMinh Assignment2Pham Cong Minh (FGW HCM)No ratings yet
- Course Outline - AABR-EMBADocument4 pagesCourse Outline - AABR-EMBAMuhammad NbNo ratings yet
- Chapter 17Document19 pagesChapter 17mehdiNo ratings yet
- First Quarter Examination: Caritas Don Bosco School Biñan City, LagunaDocument6 pagesFirst Quarter Examination: Caritas Don Bosco School Biñan City, LagunaYna DimaculanganNo ratings yet
- Teaching Strategies, Approaches, and MethodsDocument47 pagesTeaching Strategies, Approaches, and MethodsMegs Mads100% (4)