
Algorithm Homework Help
Algorithm Homework Help
You might also like
- Final 12Document11 pagesFinal 12heltaherNo ratings yet
- CS 170, Spring 2020 HW 12 A. Chiesa & J. NelsonDocument7 pagesCS 170, Spring 2020 HW 12 A. Chiesa & J. NelsonKarin AngelisNo ratings yet
- Algorithm Exam HelpDocument10 pagesAlgorithm Exam HelpProgramming Exam HelpNo ratings yet
- Algorithms Exam HelpDocument22 pagesAlgorithms Exam HelpProgramming Exam HelpNo ratings yet
- Algorithms Homework HelpDocument22 pagesAlgorithms Homework HelpProgramming Homework HelpNo ratings yet
- Pairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Document14 pagesPairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Hoang Van MinhNo ratings yet
- Competitive Programming: Bfs and DfsDocument8 pagesCompetitive Programming: Bfs and DfsMudit KumarNo ratings yet
- Mca-4 MC0080 IDocument15 pagesMca-4 MC0080 ISriram ChakrapaniNo ratings yet
- Algorithm Homework HelpDocument11 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Introduction To IntegrationDocument7 pagesIntroduction To IntegrationJorge Vega RodríguezNo ratings yet
- Algorithms Exam HelpDocument11 pagesAlgorithms Exam HelpProgramming Exam HelpNo ratings yet
- HW 1Document7 pagesHW 1Lakhdari AbdelhalimNo ratings yet
- Quiz 1 SolutionsDocument19 pagesQuiz 1 SolutionsSheikh RizwanNo ratings yet
- The Proof of Collatz Conjecture: NtroductionDocument20 pagesThe Proof of Collatz Conjecture: NtroductionThiago SilvaNo ratings yet
- AVLTreesDocument13 pagesAVLTreesGirlscoutcookie100% (1)
- XX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Document9 pagesXX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Roberto FrancoNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsKasapaNo ratings yet
- Problem Set Sample: InstructionsDocument4 pagesProblem Set Sample: InstructionsballechaseNo ratings yet
- Data Structures SampleDocument8 pagesData Structures SampleHebrew JohnsonNo ratings yet
- 14 1 Integrtn As Limit of SumDocument9 pages14 1 Integrtn As Limit of SumEbookcrazeNo ratings yet
- cs221 hw5Document3 pagescs221 hw5tony1337No ratings yet
- Lecture Notes Nonlinear Equations and RootsDocument9 pagesLecture Notes Nonlinear Equations and RootsAmbreen KhanNo ratings yet
- HW3Document3 pagesHW3dudewaNo ratings yet
- Treaps: Justin Zhang 16 February 2018Document3 pagesTreaps: Justin Zhang 16 February 2018Kartick GuptaNo ratings yet
- Lecture 5Document6 pagesLecture 5Amanifadia GarroudjiNo ratings yet
- Week 017 Calculus I - Definition of The Definite IntegralDocument7 pagesWeek 017 Calculus I - Definition of The Definite Integralvit.chinnajiginisaNo ratings yet
- Omkar Maths.5docxDocument46 pagesOmkar Maths.5docxaditya nimbalkarNo ratings yet
- CMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat TreesDocument5 pagesCMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat Treesrashed44No ratings yet
- Computer Science Textbook Solutions - 9Document30 pagesComputer Science Textbook Solutions - 9acc-expertNo ratings yet
- 3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationDocument4 pages3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationVinay GuptaNo ratings yet
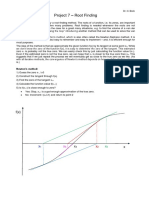
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- HW 10 202H SolutionsDocument4 pagesHW 10 202H SolutionsronaldhaiatNo ratings yet
- CBS - DsaDocument13 pagesCBS - Dsavengai marbhanNo ratings yet
- SolutionsDocument5 pagesSolutionsShironn ĐâyyNo ratings yet
- 2 SolDocument3 pages2 SolAditya MishraNo ratings yet
- Improper IntegralsDocument13 pagesImproper IntegralsQuice1969No ratings yet
- AsymptoticDocument27 pagesAsymptoticshobhanrockstarNo ratings yet
- Optimization I: Brute Force and Greedy Strategy: 3.1 Heuristic Search ApproachesDocument13 pagesOptimization I: Brute Force and Greedy Strategy: 3.1 Heuristic Search ApproachesRavi KumarNo ratings yet
- Solving Equations (Finding Zeros)Document20 pagesSolving Equations (Finding Zeros)nguyendaibkaNo ratings yet
- Lecture 4: Union-Find and Amortization: 0 1 2 DLG NeDocument8 pagesLecture 4: Union-Find and Amortization: 0 1 2 DLG NeSerena DoNo ratings yet
- Practice 1Document2 pagesPractice 1Matthew HowNo ratings yet
- SpeedMath ShortCutsVol2Document15 pagesSpeedMath ShortCutsVol2Karan KakkarNo ratings yet
- Help With Tough Programming AssignmentsDocument2 pagesHelp With Tough Programming AssignmentsJoe WayneNo ratings yet
- EditorialDocument3 pagesEditorialLaura Guo (Han)No ratings yet
- hw1 ClrsDocument4 pageshw1 ClrsRonakNo ratings yet
- EditorialDocument12 pagesEditorialSara ArracheraNo ratings yet
- Dynamic Programming 3Document20 pagesDynamic Programming 3Aakansh ShrivastavaNo ratings yet
- Algorithms Question PaperDocument3 pagesAlgorithms Question PaperSushantNo ratings yet
- Differential Equations: 12.1 What Is A Differential Equation?Document10 pagesDifferential Equations: 12.1 What Is A Differential Equation?imran hameerNo ratings yet
- Week One Presentation LaffDocument33 pagesWeek One Presentation LaffAisha GurungNo ratings yet
- Maths108 ExamReview 2021Document40 pagesMaths108 ExamReview 2021Aditya SijjuNo ratings yet
- S Ccs AnswersDocument192 pagesS Ccs AnswersnoshinNo ratings yet
- Csci 231 Homework 6 - Solutions: Binary Search Trees and Hashing Clrs Chapter 11.1-11.3 and 12.1-12.3Document2 pagesCsci 231 Homework 6 - Solutions: Binary Search Trees and Hashing Clrs Chapter 11.1-11.3 and 12.1-12.3Diponegoro Muhammad KhanNo ratings yet
- R 2 CalculationsDocument30 pagesR 2 Calculationss8nd11d UNINo ratings yet
- 4 Iterative Methods: 4.1 What A Two Year Old Child Can DoDocument15 pages4 Iterative Methods: 4.1 What A Two Year Old Child Can DoNicky WarburtonNo ratings yet
- Simplifying Expressions With Integral Exponents in This Section We Learn Some Important Laws of ExponentsDocument7 pagesSimplifying Expressions With Integral Exponents in This Section We Learn Some Important Laws of ExponentsbaihernNo ratings yet
- Calculus 223017512Document13 pagesCalculus 223017512nahianrahman0011No ratings yet
- ECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadaDocument23 pagesECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadatveldhuiNo ratings yet
- 3-Divide and Conquer ApproachDocument140 pages3-Divide and Conquer ApproachRaju YadavNo ratings yet
- Best Algorithms Design Assignment HelpDocument17 pagesBest Algorithms Design Assignment HelpProgramming Homework HelpNo ratings yet
- Online Algorithms Homework HelpDocument25 pagesOnline Algorithms Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument33 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Advanced Algorithms Homework HelpDocument9 pagesAdvanced Algorithms Homework HelpProgramming Homework HelpNo ratings yet
- Best Algorithm Homework HelpDocument15 pagesBest Algorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument9 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithms Assignment HelpDocument19 pagesAlgorithms Assignment HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument11 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithms Homework HelpDocument22 pagesAlgorithms Homework HelpProgramming Homework HelpNo ratings yet
- C Homework HelpDocument39 pagesC Homework HelpProgramming Homework HelpNo ratings yet
- Design and Analysis of Algorithms: © 2022 All Rights ReservedDocument5 pagesDesign and Analysis of Algorithms: © 2022 All Rights ReservedProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument9 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Linked List Using C Homework Help: The Problems: PS3.0: Node and ListDocument13 pagesLinked List Using C Homework Help: The Problems: PS3.0: Node and ListProgramming Homework HelpNo ratings yet
- Programming Homework HelpDocument9 pagesProgramming Homework HelpProgramming Homework HelpNo ratings yet
- Computer Science Homework HelpDocument5 pagesComputer Science Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument17 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- NMM Gold TutorialDocument7 pagesNMM Gold TutorialTane67No ratings yet
- IAS 36 Impairment of Assets (2021)Document12 pagesIAS 36 Impairment of Assets (2021)Tawanda Tatenda HerbertNo ratings yet
- Shirdi TicketDocument2 pagesShirdi TicketPOORVA GURAVNo ratings yet
- IRS Questions QbankDocument2 pagesIRS Questions Qbanktest1qaz100% (1)
- Lethe Bear Varimixer RN10 VL2 MANDocument21 pagesLethe Bear Varimixer RN10 VL2 MANGolden OdyesseyNo ratings yet
- Detecting Gross Leaks in Medical Packaging by Internal Pressurization (Bubble Test)Document5 pagesDetecting Gross Leaks in Medical Packaging by Internal Pressurization (Bubble Test)Hernan MartNo ratings yet
- LTE801 Group Hopping For UL Reference SignalDocument10 pagesLTE801 Group Hopping For UL Reference Signalmoustafa.aymanNo ratings yet
- High Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Document6 pagesHigh Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Alain DefoeNo ratings yet
- Doh HFSRB Qop01form 2 Rev2 6172022Document1 pageDoh HFSRB Qop01form 2 Rev2 6172022Araceli TiuNo ratings yet
- Autonomous Systems: Inertial SystemsDocument50 pagesAutonomous Systems: Inertial SystemsSara Nieves Matheu GarciaNo ratings yet
- THC124 - Lesson 1. The Impacts of TourismDocument50 pagesTHC124 - Lesson 1. The Impacts of TourismAnne Letrondo BajariasNo ratings yet
- Enerpac WMC Series CatalogDocument1 pageEnerpac WMC Series CatalogTitanplyNo ratings yet
- Fuses and FusingDocument3 pagesFuses and FusingDiego García MedinaNo ratings yet
- Body Paragraph 2Document3 pagesBody Paragraph 2Helen SabuquelNo ratings yet
- Zuckerberg Responses To Commerce Committee QFRs1Document229 pagesZuckerberg Responses To Commerce Committee QFRs1TechCrunch100% (2)
- On Generalized Entropy Measures and Non-Extensive Statistical MechanicsDocument26 pagesOn Generalized Entropy Measures and Non-Extensive Statistical MechanicsZahid BhatNo ratings yet
- 9 9 21 367 PDFDocument7 pages9 9 21 367 PDFaihuutran51No ratings yet
- Classification of Imbalanced Malaria Disease UsingDocument5 pagesClassification of Imbalanced Malaria Disease Usinglubna gemaaNo ratings yet
- The Haryana Value Added Tax ACT, 2003Document83 pagesThe Haryana Value Added Tax ACT, 2003adwiteya groverNo ratings yet
- HotSpotWeb User ManualDocument34 pagesHotSpotWeb User ManualmemedelarosaNo ratings yet
- Sinha and Dhiman Text BookDocument394 pagesSinha and Dhiman Text BooksindhujaNo ratings yet
- Week 45-PtMP-WiConnect-2021Document82 pagesWeek 45-PtMP-WiConnect-2021mogahedNo ratings yet
- QB Ch13 EngDocument69 pagesQB Ch13 EngsssNo ratings yet
- 1000 Manual 0407Document60 pages1000 Manual 0407Dharmesh patelNo ratings yet
- Forklift Safety Manual PolicyDocument6 pagesForklift Safety Manual PolicyHIGH REACH EQUIPMENTNo ratings yet
- PT - Science 6 - Q2Document9 pagesPT - Science 6 - Q2CYRUS ANDREA AGCONOLNo ratings yet
- Macro Analysis - Me Before YouDocument3 pagesMacro Analysis - Me Before YouJack DreyerNo ratings yet
- Industrial Training ReportDocument33 pagesIndustrial Training ReportVivek SharmaNo ratings yet
- Anatomy & Physiology - 2013annualDocument6 pagesAnatomy & Physiology - 2013annualdileepkumar.duhs4817No ratings yet
- Partitura Moliendo Cafe ScoreDocument12 pagesPartitura Moliendo Cafe ScoreDavid100% (1)






































































































Download as pptx, pdf, or txt
You might also like
- Final 12Document11 pagesFinal 12heltaherNo ratings yet
- CS 170, Spring 2020 HW 12 A. Chiesa & J. NelsonDocument7 pagesCS 170, Spring 2020 HW 12 A. Chiesa & J. NelsonKarin AngelisNo ratings yet
- Algorithm Exam HelpDocument10 pagesAlgorithm Exam HelpProgramming Exam HelpNo ratings yet
- Algorithms Exam HelpDocument22 pagesAlgorithms Exam HelpProgramming Exam HelpNo ratings yet
- Algorithms Homework HelpDocument22 pagesAlgorithms Homework HelpProgramming Homework HelpNo ratings yet
- Pairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Document14 pagesPairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Hoang Van MinhNo ratings yet
- Competitive Programming: Bfs and DfsDocument8 pagesCompetitive Programming: Bfs and DfsMudit KumarNo ratings yet
- Mca-4 MC0080 IDocument15 pagesMca-4 MC0080 ISriram ChakrapaniNo ratings yet
- Algorithm Homework HelpDocument11 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Introduction To IntegrationDocument7 pagesIntroduction To IntegrationJorge Vega RodríguezNo ratings yet
- Algorithms Exam HelpDocument11 pagesAlgorithms Exam HelpProgramming Exam HelpNo ratings yet
- HW 1Document7 pagesHW 1Lakhdari AbdelhalimNo ratings yet
- Quiz 1 SolutionsDocument19 pagesQuiz 1 SolutionsSheikh RizwanNo ratings yet
- The Proof of Collatz Conjecture: NtroductionDocument20 pagesThe Proof of Collatz Conjecture: NtroductionThiago SilvaNo ratings yet
- AVLTreesDocument13 pagesAVLTreesGirlscoutcookie100% (1)
- XX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Document9 pagesXX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Roberto FrancoNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsKasapaNo ratings yet
- Problem Set Sample: InstructionsDocument4 pagesProblem Set Sample: InstructionsballechaseNo ratings yet
- Data Structures SampleDocument8 pagesData Structures SampleHebrew JohnsonNo ratings yet
- 14 1 Integrtn As Limit of SumDocument9 pages14 1 Integrtn As Limit of SumEbookcrazeNo ratings yet
- cs221 hw5Document3 pagescs221 hw5tony1337No ratings yet
- Lecture Notes Nonlinear Equations and RootsDocument9 pagesLecture Notes Nonlinear Equations and RootsAmbreen KhanNo ratings yet
- HW3Document3 pagesHW3dudewaNo ratings yet
- Treaps: Justin Zhang 16 February 2018Document3 pagesTreaps: Justin Zhang 16 February 2018Kartick GuptaNo ratings yet
- Lecture 5Document6 pagesLecture 5Amanifadia GarroudjiNo ratings yet
- Week 017 Calculus I - Definition of The Definite IntegralDocument7 pagesWeek 017 Calculus I - Definition of The Definite Integralvit.chinnajiginisaNo ratings yet
- Omkar Maths.5docxDocument46 pagesOmkar Maths.5docxaditya nimbalkarNo ratings yet
- CMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat TreesDocument5 pagesCMSC 420: Lecture 12 Balancing by Rebuilding - Scapegoat Treesrashed44No ratings yet
- Computer Science Textbook Solutions - 9Document30 pagesComputer Science Textbook Solutions - 9acc-expertNo ratings yet
- 3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationDocument4 pages3.5 Coefficients of The Interpolating Polynomial: Interpolation and ExtrapolationVinay GuptaNo ratings yet
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- HW 10 202H SolutionsDocument4 pagesHW 10 202H SolutionsronaldhaiatNo ratings yet
- CBS - DsaDocument13 pagesCBS - Dsavengai marbhanNo ratings yet
- SolutionsDocument5 pagesSolutionsShironn ĐâyyNo ratings yet
- 2 SolDocument3 pages2 SolAditya MishraNo ratings yet
- Improper IntegralsDocument13 pagesImproper IntegralsQuice1969No ratings yet
- AsymptoticDocument27 pagesAsymptoticshobhanrockstarNo ratings yet
- Optimization I: Brute Force and Greedy Strategy: 3.1 Heuristic Search ApproachesDocument13 pagesOptimization I: Brute Force and Greedy Strategy: 3.1 Heuristic Search ApproachesRavi KumarNo ratings yet
- Solving Equations (Finding Zeros)Document20 pagesSolving Equations (Finding Zeros)nguyendaibkaNo ratings yet
- Lecture 4: Union-Find and Amortization: 0 1 2 DLG NeDocument8 pagesLecture 4: Union-Find and Amortization: 0 1 2 DLG NeSerena DoNo ratings yet
- Practice 1Document2 pagesPractice 1Matthew HowNo ratings yet
- SpeedMath ShortCutsVol2Document15 pagesSpeedMath ShortCutsVol2Karan KakkarNo ratings yet
- Help With Tough Programming AssignmentsDocument2 pagesHelp With Tough Programming AssignmentsJoe WayneNo ratings yet
- EditorialDocument3 pagesEditorialLaura Guo (Han)No ratings yet
- hw1 ClrsDocument4 pageshw1 ClrsRonakNo ratings yet
- EditorialDocument12 pagesEditorialSara ArracheraNo ratings yet
- Dynamic Programming 3Document20 pagesDynamic Programming 3Aakansh ShrivastavaNo ratings yet
- Algorithms Question PaperDocument3 pagesAlgorithms Question PaperSushantNo ratings yet
- Differential Equations: 12.1 What Is A Differential Equation?Document10 pagesDifferential Equations: 12.1 What Is A Differential Equation?imran hameerNo ratings yet
- Week One Presentation LaffDocument33 pagesWeek One Presentation LaffAisha GurungNo ratings yet
- Maths108 ExamReview 2021Document40 pagesMaths108 ExamReview 2021Aditya SijjuNo ratings yet
- S Ccs AnswersDocument192 pagesS Ccs AnswersnoshinNo ratings yet
- Csci 231 Homework 6 - Solutions: Binary Search Trees and Hashing Clrs Chapter 11.1-11.3 and 12.1-12.3Document2 pagesCsci 231 Homework 6 - Solutions: Binary Search Trees and Hashing Clrs Chapter 11.1-11.3 and 12.1-12.3Diponegoro Muhammad KhanNo ratings yet
- R 2 CalculationsDocument30 pagesR 2 Calculationss8nd11d UNINo ratings yet
- 4 Iterative Methods: 4.1 What A Two Year Old Child Can DoDocument15 pages4 Iterative Methods: 4.1 What A Two Year Old Child Can DoNicky WarburtonNo ratings yet
- Simplifying Expressions With Integral Exponents in This Section We Learn Some Important Laws of ExponentsDocument7 pagesSimplifying Expressions With Integral Exponents in This Section We Learn Some Important Laws of ExponentsbaihernNo ratings yet
- Calculus 223017512Document13 pagesCalculus 223017512nahianrahman0011No ratings yet
- ECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadaDocument23 pagesECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadatveldhuiNo ratings yet
- 3-Divide and Conquer ApproachDocument140 pages3-Divide and Conquer ApproachRaju YadavNo ratings yet
- Best Algorithms Design Assignment HelpDocument17 pagesBest Algorithms Design Assignment HelpProgramming Homework HelpNo ratings yet
- Online Algorithms Homework HelpDocument25 pagesOnline Algorithms Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument33 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Advanced Algorithms Homework HelpDocument9 pagesAdvanced Algorithms Homework HelpProgramming Homework HelpNo ratings yet
- Best Algorithm Homework HelpDocument15 pagesBest Algorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument9 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithms Assignment HelpDocument19 pagesAlgorithms Assignment HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument11 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Algorithms Homework HelpDocument22 pagesAlgorithms Homework HelpProgramming Homework HelpNo ratings yet
- C Homework HelpDocument39 pagesC Homework HelpProgramming Homework HelpNo ratings yet
- Design and Analysis of Algorithms: © 2022 All Rights ReservedDocument5 pagesDesign and Analysis of Algorithms: © 2022 All Rights ReservedProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument9 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- Linked List Using C Homework Help: The Problems: PS3.0: Node and ListDocument13 pagesLinked List Using C Homework Help: The Problems: PS3.0: Node and ListProgramming Homework HelpNo ratings yet
- Programming Homework HelpDocument9 pagesProgramming Homework HelpProgramming Homework HelpNo ratings yet
- Computer Science Homework HelpDocument5 pagesComputer Science Homework HelpProgramming Homework HelpNo ratings yet
- Algorithm Homework HelpDocument17 pagesAlgorithm Homework HelpProgramming Homework HelpNo ratings yet
- NMM Gold TutorialDocument7 pagesNMM Gold TutorialTane67No ratings yet
- IAS 36 Impairment of Assets (2021)Document12 pagesIAS 36 Impairment of Assets (2021)Tawanda Tatenda HerbertNo ratings yet
- Shirdi TicketDocument2 pagesShirdi TicketPOORVA GURAVNo ratings yet
- IRS Questions QbankDocument2 pagesIRS Questions Qbanktest1qaz100% (1)
- Lethe Bear Varimixer RN10 VL2 MANDocument21 pagesLethe Bear Varimixer RN10 VL2 MANGolden OdyesseyNo ratings yet
- Detecting Gross Leaks in Medical Packaging by Internal Pressurization (Bubble Test)Document5 pagesDetecting Gross Leaks in Medical Packaging by Internal Pressurization (Bubble Test)Hernan MartNo ratings yet
- LTE801 Group Hopping For UL Reference SignalDocument10 pagesLTE801 Group Hopping For UL Reference Signalmoustafa.aymanNo ratings yet
- High Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Document6 pagesHigh Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Alain DefoeNo ratings yet
- Doh HFSRB Qop01form 2 Rev2 6172022Document1 pageDoh HFSRB Qop01form 2 Rev2 6172022Araceli TiuNo ratings yet
- Autonomous Systems: Inertial SystemsDocument50 pagesAutonomous Systems: Inertial SystemsSara Nieves Matheu GarciaNo ratings yet
- THC124 - Lesson 1. The Impacts of TourismDocument50 pagesTHC124 - Lesson 1. The Impacts of TourismAnne Letrondo BajariasNo ratings yet
- Enerpac WMC Series CatalogDocument1 pageEnerpac WMC Series CatalogTitanplyNo ratings yet
- Fuses and FusingDocument3 pagesFuses and FusingDiego García MedinaNo ratings yet
- Body Paragraph 2Document3 pagesBody Paragraph 2Helen SabuquelNo ratings yet
- Zuckerberg Responses To Commerce Committee QFRs1Document229 pagesZuckerberg Responses To Commerce Committee QFRs1TechCrunch100% (2)
- On Generalized Entropy Measures and Non-Extensive Statistical MechanicsDocument26 pagesOn Generalized Entropy Measures and Non-Extensive Statistical MechanicsZahid BhatNo ratings yet
- 9 9 21 367 PDFDocument7 pages9 9 21 367 PDFaihuutran51No ratings yet
- Classification of Imbalanced Malaria Disease UsingDocument5 pagesClassification of Imbalanced Malaria Disease Usinglubna gemaaNo ratings yet
- The Haryana Value Added Tax ACT, 2003Document83 pagesThe Haryana Value Added Tax ACT, 2003adwiteya groverNo ratings yet
- HotSpotWeb User ManualDocument34 pagesHotSpotWeb User ManualmemedelarosaNo ratings yet
- Sinha and Dhiman Text BookDocument394 pagesSinha and Dhiman Text BooksindhujaNo ratings yet
- Week 45-PtMP-WiConnect-2021Document82 pagesWeek 45-PtMP-WiConnect-2021mogahedNo ratings yet
- QB Ch13 EngDocument69 pagesQB Ch13 EngsssNo ratings yet
- 1000 Manual 0407Document60 pages1000 Manual 0407Dharmesh patelNo ratings yet
- Forklift Safety Manual PolicyDocument6 pagesForklift Safety Manual PolicyHIGH REACH EQUIPMENTNo ratings yet
- PT - Science 6 - Q2Document9 pagesPT - Science 6 - Q2CYRUS ANDREA AGCONOLNo ratings yet
- Macro Analysis - Me Before YouDocument3 pagesMacro Analysis - Me Before YouJack DreyerNo ratings yet
- Industrial Training ReportDocument33 pagesIndustrial Training ReportVivek SharmaNo ratings yet
- Anatomy & Physiology - 2013annualDocument6 pagesAnatomy & Physiology - 2013annualdileepkumar.duhs4817No ratings yet
- Partitura Moliendo Cafe ScoreDocument12 pagesPartitura Moliendo Cafe ScoreDavid100% (1)