Download as pptx, pdf, or txt
You might also like
- Chapter 11 ProblemsDocument3 pagesChapter 11 ProblemsIna LinnyNo ratings yet
- Practice Problems - Set 2Document2 pagesPractice Problems - Set 2ashwinagrawal198231No ratings yet
- Unit IDocument38 pagesUnit IVeena SNo ratings yet
- Quantitative ResearchDocument10 pagesQuantitative ResearchKristamia Bosaing PalangyosNo ratings yet
- Parallelism of Statistics and Machine Learning & Logistic Regression Versus Random ForestDocument72 pagesParallelism of Statistics and Machine Learning & Logistic Regression Versus Random Forestvdjohn100% (1)
- PSY417 Week10Document58 pagesPSY417 Week10Ellisha McCNo ratings yet
- Applied Structural Equation Modeling For Dummies, by DummiesDocument28 pagesApplied Structural Equation Modeling For Dummies, by DummiesAnonymous rWn3ZVARLgNo ratings yet
- Parametric and Nonparametric Machine Learning AlgorithmsDocument18 pagesParametric and Nonparametric Machine Learning Algorithmsadarsh.tripathiNo ratings yet
- Design and Analysis in Educational Research Using Jamovi ANOVA DesignsDocument302 pagesDesign and Analysis in Educational Research Using Jamovi ANOVA Designsfasantos11No ratings yet
- Intro - JASPDocument30 pagesIntro - JASPInês MendesNo ratings yet
- Nathaniel SlidesCarnivalDocument9 pagesNathaniel SlidesCarnivalDanicaMae NinoNo ratings yet
- 10 1 1 579 2969 PDFDocument11 pages10 1 1 579 2969 PDFGokushimakNo ratings yet
- Research Methods: PH.D in NursingDocument63 pagesResearch Methods: PH.D in NursingsusilaNo ratings yet
- Structural Equation Modelling: Slide 1Document22 pagesStructural Equation Modelling: Slide 1Raúl AraqueNo ratings yet
- D2Document2 pagesD2Ra BaNo ratings yet
- Análisis de DatosDocument36 pagesAnálisis de DatosrusoNo ratings yet
- Research Methods For Engineering EducatorsDocument39 pagesResearch Methods For Engineering EducatorsYogesh NangareNo ratings yet
- All Statistical Tests and Their Applications Updated Latest Latest Latest LatestDocument14 pagesAll Statistical Tests and Their Applications Updated Latest Latest Latest LatestAquinas JosiahNo ratings yet
- Unit 1 Nature of Inquiry and ResearchDocument11 pagesUnit 1 Nature of Inquiry and ResearchBrent FabialaNo ratings yet
- ML - 1Document37 pagesML - 1Snehargha SahaNo ratings yet
- Multivariate Data Analysis: Setia PramanaDocument46 pagesMultivariate Data Analysis: Setia PramanaG Nathan JdNo ratings yet
- Sta630 Assignment No 1 2024Document8 pagesSta630 Assignment No 1 2024shahbaz shahidNo ratings yet
- Quantitative Research DesignsDocument22 pagesQuantitative Research DesignsKaren PangilinanNo ratings yet
- 1464253023PSY P2 M33 E-TextDocument8 pages1464253023PSY P2 M33 E-TextNIHUGBH KOLKATANo ratings yet
- Quantitative Research Uses Scientifically Collected and Statistically Analyzed Data To Investigate Observable PhenomenaDocument2 pagesQuantitative Research Uses Scientifically Collected and Statistically Analyzed Data To Investigate Observable PhenomenaMark Galvez BuenavistaNo ratings yet
- Quantitati VE ResearchDocument30 pagesQuantitati VE ResearchJhayr NatividadNo ratings yet
- Lecture Notes: MSE 601 Engineering StatisticsDocument7 pagesLecture Notes: MSE 601 Engineering StatisticshalilpashaNo ratings yet
- 5 Days Online ProgremDocument4 pages5 Days Online ProgremShivendraNo ratings yet
- Lecture-4: Introduction To Data ScienceDocument41 pagesLecture-4: Introduction To Data ScienceSaif Ali KhanNo ratings yet
- Research ProblemsDocument32 pagesResearch ProblemsS Kumaresan KumaresNo ratings yet
- MPC 006 PDFDocument313 pagesMPC 006 PDFAkanksha ParasharNo ratings yet
- Measuring Cognitive Performance On Programming Knowledge - Classical Test Theory Versus Item Response TheoryDocument5 pagesMeasuring Cognitive Performance On Programming Knowledge - Classical Test Theory Versus Item Response TheoryLeandro GalvãoNo ratings yet
- Research Group 1Document11 pagesResearch Group 1RICHARD DINGALNo ratings yet
- Unit I Predictive AnalyticsDocument39 pagesUnit I Predictive AnalyticsNarendranGRevathiNo ratings yet
- Note - Unit-5Document19 pagesNote - Unit-5YaseenNo ratings yet
- Research Methods: RES711: CLA2Document8 pagesResearch Methods: RES711: CLA2Sha SibayanNo ratings yet
- Practical Research 2: Senior High School Applied SubjectDocument45 pagesPractical Research 2: Senior High School Applied SubjectDebbie HidalgoNo ratings yet
- Vriables OnwardsDocument141 pagesVriables OnwardsTurko ReparejoNo ratings yet
- PR2 Week1Document10 pagesPR2 Week1Maureen EncaboNo ratings yet
- Practical Research 2 - Q1 - Wk1 - 2 - Introduction To Quantitative Research - EvaluatedDocument14 pagesPractical Research 2 - Q1 - Wk1 - 2 - Introduction To Quantitative Research - EvaluatedTracy John CredoNo ratings yet
- PR2 Introduction Characteristics Strengths and Weaknesses and Kinds of Research DesignDocument48 pagesPR2 Introduction Characteristics Strengths and Weaknesses and Kinds of Research DesigncarylldavidNo ratings yet
- Quantitative Research Design and MethodDocument54 pagesQuantitative Research Design and MethodRonald LucasiaNo ratings yet
- UntitledDocument45 pagesUntitledVanessa Marbida BiasNo ratings yet
- Game HexDocument1 pageGame Hexgetek25273No ratings yet
- Udd Med Filipino Summer Midterm ExamDocument6 pagesUdd Med Filipino Summer Midterm Exambryl john lawrence villamarNo ratings yet
- Jss Science and Technology University MYSURU-570006 Department of Information Science and EngineeringDocument4 pagesJss Science and Technology University MYSURU-570006 Department of Information Science and Engineeringanirudh devarajNo ratings yet
- ResearchMethods Poster A4 en Ver 1.0Document1 pageResearchMethods Poster A4 en Ver 1.0Gitarja SandiNo ratings yet
- KCU 200-Statistics For Agriculture-Notes.Document115 pagesKCU 200-Statistics For Agriculture-Notes.treazeragutu365No ratings yet
- Observational Studies and Bias in EpidemiologyDocument36 pagesObservational Studies and Bias in EpidemiologyAndre LanzerNo ratings yet
- Dr. SK Ahammad Basha Non Parametric Tests 1Document37 pagesDr. SK Ahammad Basha Non Parametric Tests 1shruti pachareNo ratings yet
- First WeekDocument80 pagesFirst WeekZian Lantiz SorianoNo ratings yet
- Characteristics, Strenghts, Weaknesses, Importance and Kinds of Quantitative ResearchDocument28 pagesCharacteristics, Strenghts, Weaknesses, Importance and Kinds of Quantitative ResearchJerome Santander AquinoNo ratings yet
- Quantitative ResearchDocument12 pagesQuantitative ResearchMarchin AlfredoNo ratings yet
- Inferential StatisticsDocument19 pagesInferential StatisticsJandy CastilloNo ratings yet
- Practical - Research - 2 - Nature - of - Research - PPTX Filename - UTF-8''Practical Research 2 - Nature of ResearchDocument13 pagesPractical - Research - 2 - Nature - of - Research - PPTX Filename - UTF-8''Practical Research 2 - Nature of ResearchCris VillarNo ratings yet
- Market ResearchDocument29 pagesMarket Researchgaurisha singhNo ratings yet
- Overview of Quantitative ResearchDocument2 pagesOverview of Quantitative ResearchLei Yunice NorberteNo ratings yet
- Research Design - KomalDocument13 pagesResearch Design - KomalNAKSH 5ANo ratings yet
- Teaching and Learning in Medicine: An International JournalDocument11 pagesTeaching and Learning in Medicine: An International JournalCáliz NitrosoNo ratings yet
- 1 Prepared by Drashti JasaniDocument60 pages1 Prepared by Drashti JasaniBHAVIK RATHODNo ratings yet
- Credible Research Made Easy: A Step by Step Path to Formulating Testable HypothesesFrom EverandCredible Research Made Easy: A Step by Step Path to Formulating Testable HypothesesNo ratings yet
- Uncertainty in Data Envelopment Analysis: Fuzzy and Belief Degree-Based UncertaintiesFrom EverandUncertainty in Data Envelopment Analysis: Fuzzy and Belief Degree-Based UncertaintiesNo ratings yet
- K-Means and PCADocument69 pagesK-Means and PCAvdjohnNo ratings yet
- Parallelism of Statistics and Machine Learning & Logistic Regression Versus Random ForestDocument72 pagesParallelism of Statistics and Machine Learning & Logistic Regression Versus Random Forestvdjohn100% (1)
- KNN and Naive BayesDocument61 pagesKNN and Naive BayesvdjohnNo ratings yet
- Support Vector Machines and Artificial Neural Networks: Dr.S.Veena, Associate Professor/CSEDocument78 pagesSupport Vector Machines and Artificial Neural Networks: Dr.S.Veena, Associate Professor/CSEvdjohnNo ratings yet
- Classes and ObjectsDocument20 pagesClasses and Objectsvdjohn100% (1)
- Operator Overloading: Dr.S.Veena, Associate Professor/CSEDocument13 pagesOperator Overloading: Dr.S.Veena, Associate Professor/CSEvdjohnNo ratings yet
- Unit - I-Object Oriented Programming ConceptsDocument22 pagesUnit - I-Object Oriented Programming ConceptsvdjohnNo ratings yet
- OODP - Unit - I - UML DiagramDocument64 pagesOODP - Unit - I - UML DiagramvdjohnNo ratings yet
- Bootstrap T TestDocument19 pagesBootstrap T Testpink_golemNo ratings yet
- 08 Factorial2 PDFDocument40 pages08 Factorial2 PDFOtono ExtranoNo ratings yet
- Statistics For Business and Economics (13e) : John LoucksDocument41 pagesStatistics For Business and Economics (13e) : John LoucksSusti ClausNo ratings yet
- Example: 1: Discrete Probability Distribution and HistogramDocument5 pagesExample: 1: Discrete Probability Distribution and HistogramSEAN LEONARD SALCEDONo ratings yet
- Interval EstimationDocument42 pagesInterval EstimationAntariksha GangulyNo ratings yet
- Lesson3 ShsDocument8 pagesLesson3 ShsCristy Balubayan NazarenoNo ratings yet
- Student Data Chapter A4 Sampling Distributions r3Document18 pagesStudent Data Chapter A4 Sampling Distributions r3khaled mohamedNo ratings yet
- Lesson 6 Measures of Relative Dispersion Power PointDocument8 pagesLesson 6 Measures of Relative Dispersion Power PointJoyce Laru-anNo ratings yet
- (2003) Testing For Serial Correlation in Linear Panel-Data Models - STATADocument12 pages(2003) Testing For Serial Correlation in Linear Panel-Data Models - STATALeonel Ferreira100% (1)
- Chapter18 Econometrics SUREModelsDocument7 pagesChapter18 Econometrics SUREModelsArka DasNo ratings yet
- Probability and Statistics For Engineers FinalExam - 2007-1Document8 pagesProbability and Statistics For Engineers FinalExam - 2007-1a.bNo ratings yet
- Lampiran Hasil Uji Reliabilitas Kuesioner PenelitianDocument3 pagesLampiran Hasil Uji Reliabilitas Kuesioner PenelitianMA Sunan Kalijaga BawangNo ratings yet
- Alan Agresti, Christine A. Franklin, Bernhard Klingenberg-Statistics - The Art and Science of Learning From Data-Pearson (2017)Document10 pagesAlan Agresti, Christine A. Franklin, Bernhard Klingenberg-Statistics - The Art and Science of Learning From Data-Pearson (2017)luana testoniNo ratings yet
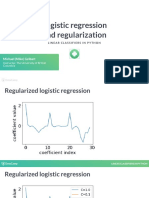
- Logistic Regression and Regularization: Michael (Mike) GelbartDocument19 pagesLogistic Regression and Regularization: Michael (Mike) GelbartNourheneMbarekNo ratings yet
- Nonparametric TestsDocument4 pagesNonparametric TestsAllen MarcNo ratings yet
- Acot103 Final ExamDocument8 pagesAcot103 Final ExamNicole Anne Santiago SibuloNo ratings yet
- Syed Irfan Haider: ID # 2836 Course: QTIA Submitted To: Sir Imtiaz ArifDocument17 pagesSyed Irfan Haider: ID # 2836 Course: QTIA Submitted To: Sir Imtiaz ArifaashanNo ratings yet
- Lecure-3 ProbabilityDocument80 pagesLecure-3 ProbabilityBonsaNo ratings yet
- Probability Unit 3Document3 pagesProbability Unit 3Dinesh reddyNo ratings yet
- Parameter and StatisticsDocument22 pagesParameter and StatisticsRichel Bulalacao RabasNo ratings yet
- Quantification of Uncertainties in The 100-Year Flow at An Ungaged Site Near A Gaged Station and Its Application in GeorgiaDocument8 pagesQuantification of Uncertainties in The 100-Year Flow at An Ungaged Site Near A Gaged Station and Its Application in GeorgiaAlvaro García BaezaNo ratings yet
- Correlation & Regression Analysis - Exercise2Document43 pagesCorrelation & Regression Analysis - Exercise2Samiha Maysoon Nooria100% (1)
- IOER Descriptive and Inferential Gonzales NepthalieDocument39 pagesIOER Descriptive and Inferential Gonzales NepthalieMITZHE GAE MAMINONo ratings yet
- 4 - Probability TheoryDocument20 pages4 - Probability TheoryJani Saida ShaikNo ratings yet
- Psicothema: Evidence For Test Validation: A Guide For PractitionersDocument10 pagesPsicothema: Evidence For Test Validation: A Guide For PractitionersRafael CalpenaNo ratings yet
- Loyola College Master of Social Work Question Paper 3Document2 pagesLoyola College Master of Social Work Question Paper 3shaliniramamurthy19No ratings yet
- Assignment01 PTRPDocument1 pageAssignment01 PTRPPretty FibberNo ratings yet
- Using Logistic Regression To Estimate The Influence of Crash Factors On Road Crash Severity in Kathmandu ValleyDocument14 pagesUsing Logistic Regression To Estimate The Influence of Crash Factors On Road Crash Severity in Kathmandu ValleyAnil MarsaniNo ratings yet