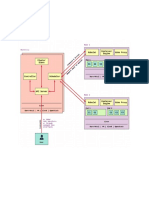
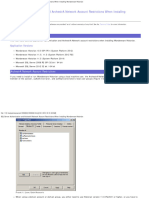
Download as ppt, pdf, or txt
You might also like
- Data StageDocument3 pagesData StageSathishNo ratings yet
- Cka Kubernetes Application Developer Crash CourseDocument172 pagesCka Kubernetes Application Developer Crash Coursesanjosetel7No ratings yet
- AZ - 104 Test 3Document240 pagesAZ - 104 Test 3carlos davidNo ratings yet
- Test AnsibleDocument116 pagesTest Ansibleabhi garg100% (1)
- Clustering DocumentationDocument15 pagesClustering DocumentationNazifa KazimiNo ratings yet
- Percona XtraDB 集群文档Document37 pagesPercona XtraDB 集群文档HoneyMooseNo ratings yet
- 13 MANG SlidesDocument42 pages13 MANG Slidesshamsher3052No ratings yet
- Callmanager Database ReplicationDocument53 pagesCallmanager Database ReplicationGoutham BaratamNo ratings yet
- Mysql Replication & ClusterDocument40 pagesMysql Replication & Clustertaejun100% (9)
- Oracle 11g R2 RAC and Grid Infrastructure by Rene KundersmaDocument20 pagesOracle 11g R2 RAC and Grid Infrastructure by Rene Kundersmaittichai100% (1)
- Oracle Background ProcessesDocument9 pagesOracle Background ProcessesAmalraj IrudayamaniNo ratings yet
- Managing Managing Postgresql With Postgresql With Ansible AnsibleDocument50 pagesManaging Managing Postgresql With Postgresql With Ansible Ansiblegforce_haterNo ratings yet
- k8s PrimerDocument40 pagesk8s Primersunil kalvaNo ratings yet
- Ansible Interview QuestionsDocument3 pagesAnsible Interview QuestionssrinivasNo ratings yet
- Module 5 - Ensuring Successful Operation of A Cloud SolutionDocument41 pagesModule 5 - Ensuring Successful Operation of A Cloud Solutionraghs4uNo ratings yet
- Shareplex PresentationDocument44 pagesShareplex Presentation7862005No ratings yet
- Oracle Cluster On CentOS Using CentOS Cluster Ware PDFDocument131 pagesOracle Cluster On CentOS Using CentOS Cluster Ware PDFmusabsyd100% (1)
- Kubernetes For World PDFDocument9 pagesKubernetes For World PDFcumar2014No ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document6 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- 10 Crs Diag Jfv4Document18 pages10 Crs Diag Jfv4Palash SarkarNo ratings yet
- RAC 11gR2 CLUSTER SETUPDocument82 pagesRAC 11gR2 CLUSTER SETUPvenkatreddyNo ratings yet
- CLMGRDocument12 pagesCLMGRAnvesh ReddyNo ratings yet
- Ansible TebotDocument30 pagesAnsible Tebotvinodbabu24No ratings yet
- Practical 5 - NoSQL - SUJALDocument8 pagesPractical 5 - NoSQL - SUJALpapatel4045No ratings yet
- Percona XtraDB Cluster 5.7Document92 pagesPercona XtraDB Cluster 5.7Rifki ZulfikarNo ratings yet
- Chapter 11Document60 pagesChapter 11vaishali khairnarNo ratings yet
- Lab Guide: OutlineDocument100 pagesLab Guide: OutlineValon BajramiNo ratings yet
- 14 EJBS SlidesDocument27 pages14 EJBS Slidesshamsher3052No ratings yet
- What Is Ansible?: Ansible Tutorial For Beginners: Playbook, Commands & ExampleDocument24 pagesWhat Is Ansible?: Ansible Tutorial For Beginners: Playbook, Commands & ExampleNishant TNo ratings yet
- Kubernetes For Java DevelopersDocument63 pagesKubernetes For Java DevelopersRobin AwalNo ratings yet
- Configure High Availability Cluster in Centos 7 (Step by Step Guide)Document9 pagesConfigure High Availability Cluster in Centos 7 (Step by Step Guide)HamzaKhanNo ratings yet
- Kubeenetes ClusterDocument47 pagesKubeenetes ClustertaleffNo ratings yet
- How To Configure Two Node High Availability Cluster On RHELDocument18 pagesHow To Configure Two Node High Availability Cluster On RHELslides courseNo ratings yet
- RAC Installation On Hpux Itanium POADocument13 pagesRAC Installation On Hpux Itanium POAbirupakhyamisramcaNo ratings yet
- Kuber Net EsDocument47 pagesKuber Net EsjaipreetsharmaNo ratings yet
- How To Configure High - 2Document17 pagesHow To Configure High - 2slides courseNo ratings yet
- Parallel Programming Platforms: Alexandre David 1.2.05Document30 pagesParallel Programming Platforms: Alexandre David 1.2.05Priya PatelNo ratings yet
- ELK SetupDocument16 pagesELK Setupdell xpsNo ratings yet
- Advanced Eap7 Cheat Sheet r2v1Document8 pagesAdvanced Eap7 Cheat Sheet r2v1chakrikollaNo ratings yet
- Major Features: Postgres 10: Ruce OmjianDocument20 pagesMajor Features: Postgres 10: Ruce OmjianPhotoHawkNo ratings yet
- 11g Rac InstallationDocument63 pages11g Rac Installationjay karandikarNo ratings yet
- Deploy High Availability Cluster On RHEL 8 Using Shared StorageDocument13 pagesDeploy High Availability Cluster On RHEL 8 Using Shared StorageluongdkNo ratings yet
- Kubernetes Production Readiness and Best Practices ChecklistDocument33 pagesKubernetes Production Readiness and Best Practices ChecklistBrianJ.RomeroAguirreNo ratings yet
- Kub Prac 01092022Document38 pagesKub Prac 01092022Rajan YadavNo ratings yet
- LinuxCluster PDFDocument21 pagesLinuxCluster PDFVittorio GrassoNo ratings yet
- Oracle Cluster Ready Services 11g - Tips and CommentsDocument41 pagesOracle Cluster Ready Services 11g - Tips and CommentsDin4everNo ratings yet
- kubernetes Architecture 1Document5 pageskubernetes Architecture 1Vamsi ChowdaryNo ratings yet
- k8s1 PDFDocument61 pagesk8s1 PDFSree Harsha Ananda RaoNo ratings yet
- Oracle Clusteware Presentation COUGDocument47 pagesOracle Clusteware Presentation COUGHuynh Sy Nguyen100% (1)
- NetappDocument88 pagesNetappnandanNo ratings yet
- Ansible KodekloudDocument46 pagesAnsible KodekloudAhmed Abd el naserNo ratings yet
- Everything Useful I Know About Kubectl - Atomic CommitsDocument10 pagesEverything Useful I Know About Kubectl - Atomic CommitstutorificNo ratings yet
- Celerra CLI Guide PDFDocument9 pagesCelerra CLI Guide PDFShashidhar MahalingamNo ratings yet
- SQL Dba Interview QuestionsDocument67 pagesSQL Dba Interview QuestionsShubhamNo ratings yet
- Apache ZooKeeper - MesosphereDocument27 pagesApache ZooKeeper - MesospheresatmaniaNo ratings yet
- MysqlDocument77 pagesMysqlNguyễn VũNo ratings yet
- Amazon MSK To Snowflake v1.3Document16 pagesAmazon MSK To Snowflake v1.3lexNo ratings yet
- Mastering Go Network Automation: Automating Networks, Container Orchestration, Kubernetes with Puppet, Vegeta and Apache JMeterFrom EverandMastering Go Network Automation: Automating Networks, Container Orchestration, Kubernetes with Puppet, Vegeta and Apache JMeterNo ratings yet
- Solr Cluster Installation Tool "Anuenue" and "Did You Mean?" For JapaneseDocument47 pagesSolr Cluster Installation Tool "Anuenue" and "Did You Mean?" For JapaneselucidimaginationNo ratings yet
- Using SOLR For Enabling Highly Customized Sitewide NavigationDocument12 pagesUsing SOLR For Enabling Highly Customized Sitewide NavigationlucidimaginationNo ratings yet
- Building Specialized Industry Applications Using Solr, and Migration From FAST ESPDocument20 pagesBuilding Specialized Industry Applications Using Solr, and Migration From FAST ESPlucidimaginationNo ratings yet
- Highly Relevant Search Result Ranking For Large Law Enforcement Information Sharing SystemsDocument43 pagesHighly Relevant Search Result Ranking For Large Law Enforcement Information Sharing SystemslucidimaginationNo ratings yet
- Searching The United States Code With Solr/Lucene: Paul Nelson / Ronald Matamoros, Search TechnologiesDocument39 pagesSearching The United States Code With Solr/Lucene: Paul Nelson / Ronald Matamoros, Search TechnologieslucidimaginationNo ratings yet
- Flexible Indexing in Lucene 4.0Document35 pagesFlexible Indexing in Lucene 4.0lucidimaginationNo ratings yet
- Practical Search in The CloudDocument18 pagesPractical Search in The CloudlucidimaginationNo ratings yet
- Solr at Ebay KleinanzeigenDocument17 pagesSolr at Ebay KleinanzeigenlucidimaginationNo ratings yet
- Implementing Click-Through Relevance Ranking in Solr and LucidWorks EnterpriseDocument31 pagesImplementing Click-Through Relevance Ranking in Solr and LucidWorks EnterpriselucidimaginationNo ratings yet
- Greplin On Thousands of Indexes in The Cloud at Lucene Revolution 2011Document11 pagesGreplin On Thousands of Indexes in The Cloud at Lucene Revolution 2011lucidimaginationNo ratings yet
- Aleksandrovskyboris Real Time Search at Yammer 110531210420 Phpapp01Document48 pagesAleksandrovskyboris Real Time Search at Yammer 110531210420 Phpapp01lucidimaginationNo ratings yet
- From Publisher To Platform: How The Guardian Embraced The Internet Using Content, Search, and Open SourceDocument85 pagesFrom Publisher To Platform: How The Guardian Embraced The Internet Using Content, Search, and Open SourcelucidimaginationNo ratings yet
- Joshua Tuberville @lucene Revolution 2011Document50 pagesJoshua Tuberville @lucene Revolution 2011lucidimaginationNo ratings yet
- Redmonk at Lucene Revolution 2011Document31 pagesRedmonk at Lucene Revolution 2011lucidimaginationNo ratings yet
- Boosting Documents in Solr by Recency, Popularity, and User PreferencesDocument20 pagesBoosting Documents in Solr by Recency, Popularity, and User PreferenceslucidimaginationNo ratings yet
- Marc Krellenst's Session at Lucene Revolution 2011Document16 pagesMarc Krellenst's Session at Lucene Revolution 2011lucidimaginationNo ratings yet
- Programmer Open Source Search What's New in Apache Lucene Programmer's Guide To Open Source Search: Apache Lucene 3.0Document36 pagesProgrammer Open Source Search What's New in Apache Lucene Programmer's Guide To Open Source Search: Apache Lucene 3.0lucidimaginationNo ratings yet
- Gregg Donovan @lucene Revolution 2011Document84 pagesGregg Donovan @lucene Revolution 2011lucidimaginationNo ratings yet
- Summary of It Client Interview 1Document4 pagesSummary of It Client Interview 1Derick cheruyotNo ratings yet
- CSC 202 Chapter 1Document9 pagesCSC 202 Chapter 1Favour JosephNo ratings yet
- Paul Fedele Free Linux Course MaterialsDocument36 pagesPaul Fedele Free Linux Course MaterialsThumma MaryNo ratings yet
- Using The Catalina Loader On An ImacDocument14 pagesUsing The Catalina Loader On An Imacman_ariefNo ratings yet
- Lab 1 - Part A (2.3.8) - Navigate The IOS by Using Tera Term For Console Connectivity-UpdatedDocument6 pagesLab 1 - Part A (2.3.8) - Navigate The IOS by Using Tera Term For Console Connectivity-Updatedkhalifaalmuhairi20No ratings yet
- AZ 305+Official+Course+Study+GuideDocument14 pagesAZ 305+Official+Course+Study+GuideHeilly JerivethNo ratings yet
- Sap User TypesDocument65 pagesSap User TypesDevender5194No ratings yet
- Q1) Issues in Designing Distributed Systems:: 1. HeterogeneityDocument3 pagesQ1) Issues in Designing Distributed Systems:: 1. HeterogeneitySubhadeepti GantiNo ratings yet
- How To Export and Import Emails and Files Using Google TakeoutDocument7 pagesHow To Export and Import Emails and Files Using Google TakeoutDarlene Yap RontasNo ratings yet
- System Center Configuration Manager Protect Data and Infrastructure PDFDocument181 pagesSystem Center Configuration Manager Protect Data and Infrastructure PDFJu FiksonNo ratings yet
- Infotype Menu Configuration Steps SAP HR - SAP Training TutorialsDocument6 pagesInfotype Menu Configuration Steps SAP HR - SAP Training TutorialsMrinal Kanti DasNo ratings yet
- ACID40 ManualDocument196 pagesACID40 ManualchichangNo ratings yet
- TIBCO - TIBCO TRA Installation NotesDocument10 pagesTIBCO - TIBCO TRA Installation NotesKanchan ChakrabortyNo ratings yet
- Project 1 A V3Document20 pagesProject 1 A V3Pranay SuryaraoNo ratings yet
- IS 13517 - Rock Bolts - Resin Type - Bureau of Indian Standards - Free Download, Borrow, and Streaming - Internet ArchiveDocument2 pagesIS 13517 - Rock Bolts - Resin Type - Bureau of Indian Standards - Free Download, Borrow, and Streaming - Internet Archiveihateu1No ratings yet
- CN7021 Project TemplateDocument8 pagesCN7021 Project TemplatePallavi PalluNo ratings yet
- Bigbluebutton 0.8B Student Guide Enabling AudioDocument4 pagesBigbluebutton 0.8B Student Guide Enabling AudiovalentinoNo ratings yet
- Aggregates: Studying The Aggregation of Molecules in Trajectories of Molecular DynamicsDocument11 pagesAggregates: Studying The Aggregation of Molecules in Trajectories of Molecular DynamicschuneshphysicsNo ratings yet
- Day PI QuestionsDocument9 pagesDay PI QuestionsVIKAS KUMARNo ratings yet
- CommandsDocument21 pagesCommandsWill PayneNo ratings yet
- Ahmad Nazirul Mohd NazarDocument3 pagesAhmad Nazirul Mohd NazarAhmad JettoNo ratings yet
- NCO Grade 4 Sample Test PaperDocument8 pagesNCO Grade 4 Sample Test PaperShantanu100% (2)
- BMJCVDocument1 pageBMJCVKulsum ModaNo ratings yet
- Troubleshoot Jabber Login ProblemsDocument20 pagesTroubleshoot Jabber Login ProblemsJody iOSNo ratings yet
- COB20 - Online Note SharingDocument24 pagesCOB20 - Online Note SharingVenu RachanNo ratings yet
- Architectural Design: ©ian Sommerville 2000 Software Engineering. Chapter 11 Slide 1Document65 pagesArchitectural Design: ©ian Sommerville 2000 Software Engineering. Chapter 11 Slide 1Suada Bőw WéěžýNo ratings yet
- LogDocument2,661 pagesLogAlessioLuigiDastoliNo ratings yet
- Tech Note 1010 - SQL Server Authentication and ArchestrA Network Account Restrictions When Installing Wonderware HistorianDocument8 pagesTech Note 1010 - SQL Server Authentication and ArchestrA Network Account Restrictions When Installing Wonderware Historianprofilemail8No ratings yet
- Introduction To XCATDocument45 pagesIntroduction To XCATZero RainNo ratings yet
- Threats and Attacks: CSE 4471: Information Security Instructor: Adam C. Champion, PH.DDocument26 pagesThreats and Attacks: CSE 4471: Information Security Instructor: Adam C. Champion, PH.Dswapnil RawatNo ratings yet