Download as pptx, pdf, or txt
You might also like
- Weekly Quiz 1 Machine Learning Great Learning PDFDocument7 pagesWeekly Quiz 1 Machine Learning Great Learning PDFRobertKimtai100% (2)
- Dimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiDocument17 pagesDimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- Kernel K-Means, Spectral Clustering and Normalized Cuts: Inderjit S. Dhillon Yuqiang Guan Brian KulisDocument6 pagesKernel K-Means, Spectral Clustering and Normalized Cuts: Inderjit S. Dhillon Yuqiang Guan Brian KulisNo12n533No ratings yet
- Fuzzy Clustering: Presented by CH - Srikanth (07991A1268)Document11 pagesFuzzy Clustering: Presented by CH - Srikanth (07991A1268)Srikanth Surya ChikkalaNo ratings yet
- Data Clustering: Some Other Aspects: (K-Means++, Overlapping Clustering, Evaluation)Document7 pagesData Clustering: Some Other Aspects: (K-Means++, Overlapping Clustering, Evaluation)Rajachandra VoodigaNo ratings yet
- SML Hand Note Bau by DTDocument1 pageSML Hand Note Bau by DTfarida1971yasminNo ratings yet
- Dimensionality Reduction: Principal Component Analysis and SVDDocument16 pagesDimensionality Reduction: Principal Component Analysis and SVDRajachandra VoodigaNo ratings yet
- Week 3 ClusteringDocument36 pagesWeek 3 ClusteringIshaq AliNo ratings yet
- Hota ML13Document24 pagesHota ML13crazyfinisher891No ratings yet
- UCS551 Chapter 7 - ClusteringDocument6 pagesUCS551 Chapter 7 - Clusteringnur ashfaralianaNo ratings yet
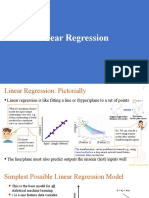
- Linear RegressionDocument14 pagesLinear RegressionALINA SOYNo ratings yet
- Kpconv: Flexible and Deformable Convolution For Point CloudsDocument10 pagesKpconv: Flexible and Deformable Convolution For Point CloudscuimosemailNo ratings yet
- Irregular Convolutional Neural NetworksDocument7 pagesIrregular Convolutional Neural NetworksNadya ShamaraNo ratings yet
- Adaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceDocument17 pagesAdaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceAyushNo ratings yet
- Lecture 23Document15 pagesLecture 23Kushagra guptaNo ratings yet
- By: Janhavi Thakur: K-Nearest NeighboursDocument1 pageBy: Janhavi Thakur: K-Nearest NeighboursJanhavi ThakurNo ratings yet
- Assignment 5Document3 pagesAssignment 5Pujan PatelNo ratings yet
- K-Means Data Clustering Approach: Jaipur National UniversityDocument43 pagesK-Means Data Clustering Approach: Jaipur National UniversityFaizan ShaikhNo ratings yet
- Clustering FinancialDataDocument38 pagesClustering FinancialDataZeeshan AliNo ratings yet
- Linear Regression: CS771: Introduction To Machine Learning NisheethDocument14 pagesLinear Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Unsupervised Learning: K-Means ClusteringDocument23 pagesUnsupervised Learning: K-Means Clusteringariw200201No ratings yet
- Unsupervised Image Segmentation by Backpropagation: Asako KanezakiDocument5 pagesUnsupervised Image Segmentation by Backpropagation: Asako KanezakiUnaixa KhanNo ratings yet
- Mullick 2018Document13 pagesMullick 2018EmilioNo ratings yet
- Supervised Kmeans-08Document9 pagesSupervised Kmeans-08Mohammad MuskaanNo ratings yet
- Data Mining Clustering QuestionsDocument18 pagesData Mining Clustering Questionsnitob90303No ratings yet
- CS423 Data Warehousing and Data Mining: Dr. Hammad AfzalDocument41 pagesCS423 Data Warehousing and Data Mining: Dr. Hammad AfzalZafar IqbalNo ratings yet
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningJiyual MustiNo ratings yet
- Concepts and Techniques: Data MiningDocument27 pagesConcepts and Techniques: Data MiningAdamZain788No ratings yet
- Ds 11Document21 pagesDs 11DilipNo ratings yet
- ML.5-Clustering Techniques (Week 9)Document71 pagesML.5-Clustering Techniques (Week 9)Sơn TrịnhNo ratings yet
- Cluster Lecture-1Document20 pagesCluster Lecture-1aychewchernetNo ratings yet
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningRizky RamadhanNo ratings yet
- Data Mining ClusteringDocument76 pagesData Mining ClusteringAnjali Asha JacobNo ratings yet
- Lecture 5Document18 pagesLecture 5coutyesNo ratings yet
- 12 Text ClusteringDocument26 pages12 Text ClusteringthatsarraNo ratings yet
- 4 ClusteringDocument21 pages4 Clusteringpaulitxenko08No ratings yet
- 4 Clustering1Document41 pages4 Clustering1melipintNo ratings yet
- Lecture 19 - Nonlinear Learning With Kernels (1) - PlainDocument15 pagesLecture 19 - Nonlinear Learning With Kernels (1) - PlainRajachandra VoodigaNo ratings yet
- A Method To Estimate The Statistical Confidence of Cluster SeparationDocument8 pagesA Method To Estimate The Statistical Confidence of Cluster SeparationIvan CordovaNo ratings yet
- Weighted Graph Cuts Without Eigenvectors: A Multilevel ApproachDocument14 pagesWeighted Graph Cuts Without Eigenvectors: A Multilevel ApproachShwetha BNo ratings yet
- Chap8 Advanced Cluster AnalysisDocument45 pagesChap8 Advanced Cluster Analysisمحمد إحسنNo ratings yet
- Towards Efficient and Improved Hierarchical Clustering With Instance and Cluster Level ConstraintsDocument12 pagesTowards Efficient and Improved Hierarchical Clustering With Instance and Cluster Level ConstraintspandalovetacoNo ratings yet
- Unsupervisd Learning AlgorithmDocument6 pagesUnsupervisd Learning AlgorithmShrey DixitNo ratings yet
- Clustering: ISOM3360 Data Mining For Business AnalyticsDocument28 pagesClustering: ISOM3360 Data Mining For Business AnalyticsClaire LeeNo ratings yet
- Met Is 256338Document5 pagesMet Is 256338yulyNo ratings yet
- Class19-22 Clustering 17-25oct2019Document42 pagesClass19-22 Clustering 17-25oct2019Saili MishraNo ratings yet
- Constrained K-Means Clustering With Background KnowledgeDocument8 pagesConstrained K-Means Clustering With Background KnowledgefatihumamNo ratings yet
- Machine Learning: Algorithms and Applications: Philip O. OgunbonaDocument29 pagesMachine Learning: Algorithms and Applications: Philip O. OgunbonaNguyễn Hoàng Phương TrầnNo ratings yet
- ET4248E - Chap9 - K-Means and GMMDocument27 pagesET4248E - Chap9 - K-Means and GMMChuyên Mai TấtNo ratings yet
- Fuzzy Clustering With Multiple Kernels: Naouel Baili Hichem FriguiDocument7 pagesFuzzy Clustering With Multiple Kernels: Naouel Baili Hichem FriguiRajendra PrasadNo ratings yet
- Journal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Document5 pagesJournal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Journal of Computer ApplicationsNo ratings yet
- Clustering Techniques - Hierarchical, K-Means ClusteringDocument22 pagesClustering Techniques - Hierarchical, K-Means ClusteringTanya SharmaNo ratings yet
- 13: Clustering: Unsupervised Learning - IntroductionDocument6 pages13: Clustering: Unsupervised Learning - Introductionswetha sastryNo ratings yet
- Stat 390 Presentation 2Document14 pagesStat 390 Presentation 2api-340742243No ratings yet
- Concepts and Techniques: Data MiningDocument43 pagesConcepts and Techniques: Data MiningEsraa SamirNo ratings yet
- Machine Learning ISA-2 Answer BankDocument28 pagesMachine Learning ISA-2 Answer BankShivansh MishraNo ratings yet
- Lecture 21 and 22Document28 pagesLecture 21 and 22Kushagra guptaNo ratings yet
- DB ScanDocument7 pagesDB ScanUJJAWAL PUGALIANo ratings yet
- Practical Solutions To The Problem of Diagonal DomDocument9 pagesPractical Solutions To The Problem of Diagonal Domdeepti singhNo ratings yet
- 3 UnSupervised LearningDocument53 pages3 UnSupervised LearningZaeem AbbasNo ratings yet
- Chapter2-Timing and Profiling CodeDocument5 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Chapter3 Gaining EfficienciesDocument58 pagesChapter3 Gaining EfficienciesRajachandra VoodigaNo ratings yet
- Chapter2-Timing and Profiling CodeDocument51 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Chapter4-Basic Pandas OptimizationsDocument37 pagesChapter4-Basic Pandas OptimizationsRajachandra VoodigaNo ratings yet
- Supervised LearningDocument210 pagesSupervised LearningRajachandra VoodigaNo ratings yet
- Recommender SystemsDocument12 pagesRecommender SystemsRajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument5 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument28 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- Reinforcement LearningDocument23 pagesReinforcement LearningRajachandra VoodigaNo ratings yet
- Semi-: Supervised LearningDocument40 pagesSemi-: Supervised LearningRajachandra VoodigaNo ratings yet
- RNN LSTMDocument49 pagesRNN LSTMRajachandra VoodigaNo ratings yet
- Ensemble MethodDocument115 pagesEnsemble MethodRajachandra VoodigaNo ratings yet
- What To Do When It Is Not WorkingDocument7 pagesWhat To Do When It Is Not WorkingRajachandra VoodigaNo ratings yet
- Time SeriesDocument91 pagesTime SeriesRajachandra Voodiga100% (1)
- 4 Selected Topics in Computer Vision & Deep LearningDocument78 pages4 Selected Topics in Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- Uncertainity QuantificationDocument88 pagesUncertainity QuantificationRajachandra VoodigaNo ratings yet
- Strategic Data Science-PreviewDocument109 pagesStrategic Data Science-PreviewRajachandra VoodigaNo ratings yet
- Monthly Periodicals v2Document47 pagesMonthly Periodicals v2Rajachandra VoodigaNo ratings yet
- RegressionDocument4 pagesRegressionRajachandra VoodigaNo ratings yet
- Gurukul DataScience Jan2022Document34 pagesGurukul DataScience Jan2022Rajachandra VoodigaNo ratings yet
- Joining Data in SQL Cheat SheetDocument1 pageJoining Data in SQL Cheat SheetRajachandra VoodigaNo ratings yet
- 2 Machine Learning GeneralDocument56 pages2 Machine Learning GeneralRajachandra VoodigaNo ratings yet
- MachineLearning JDDocument90 pagesMachineLearning JDRajachandra VoodigaNo ratings yet
- 3 Fundamentals For Computer Vision & Deep LearningDocument56 pages3 Fundamentals For Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- 08.time SeriesDocument1 page08.time SeriesRajachandra VoodigaNo ratings yet
- 4.introduction To Random Forests TakeawaysDocument3 pages4.introduction To Random Forests TakeawaysRajachandra VoodigaNo ratings yet
- 1 Computer ScienceDocument60 pages1 Computer ScienceRajachandra VoodigaNo ratings yet
- Week 1 DSDocument48 pagesWeek 1 DSRajachandra VoodigaNo ratings yet
- Linear RegressionDocument13 pagesLinear RegressionRajachandra VoodigaNo ratings yet
- 20210501-ML Question BankDocument1 page20210501-ML Question BankRajachandra VoodigaNo ratings yet
- Intro To Data MinningDocument24 pagesIntro To Data MinningAkshay MathurNo ratings yet
- Cluster AnalysisDocument9 pagesCluster AnalysisAmol RattanNo ratings yet
- Clustering TodayDocument52 pagesClustering TodayShubh AgarwalNo ratings yet
- Clustering: K-Means, Agglomerative, DBSCAN: Tan, Steinbach, KumarDocument45 pagesClustering: K-Means, Agglomerative, DBSCAN: Tan, Steinbach, Kumarhub23No ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- Segmenting Bank Customers Via RFM Model and Unsupervised Machine LearningDocument6 pagesSegmenting Bank Customers Via RFM Model and Unsupervised Machine LearningShaifuru AnamuNo ratings yet
- Consumers' Awareness of Sustainable Fashion, Marketing Management JournalDocument14 pagesConsumers' Awareness of Sustainable Fashion, Marketing Management JournalCecilia CeciCeciNo ratings yet
- U-Matrix 3Document10 pagesU-Matrix 3Kazem BetvanNo ratings yet
- Unit 5 - Cluster AnalysisDocument28 pagesUnit 5 - Cluster Analysisnimmaladinesh82No ratings yet
- Ca-3 QB (Pec-It602b) - 2024-1Document12 pagesCa-3 QB (Pec-It602b) - 2024-1niladribiswas47530No ratings yet
- DSA Presentation Group 6Document34 pagesDSA Presentation Group 6AYUSHI WAKODENo ratings yet
- Seminar Report FormatDocument19 pagesSeminar Report FormatShahnawaz SheikhNo ratings yet
- Term-End Project - Customer Analytics by Vishal V (2020)Document39 pagesTerm-End Project - Customer Analytics by Vishal V (2020)Johnn SneNo ratings yet
- Cluster Is A Group of Objects That Belongs To The Same ClassDocument12 pagesCluster Is A Group of Objects That Belongs To The Same ClasskalpanaNo ratings yet
- Algorithem Cheat SheetDocument25 pagesAlgorithem Cheat Sheetsekhar hexaNo ratings yet
- 資料探勘應用於醫藥物流中心消耗預測Document70 pages資料探勘應用於醫藥物流中心消耗預測Harper ChengNo ratings yet
- IRS Unit-4Document13 pagesIRS Unit-4Anonymous iCFJ73OMpD50% (4)
- Telecom Dataset OutputDocument34 pagesTelecom Dataset OutputSantoshIshkhanNo ratings yet
- The Classification of Style in Fine-Art PaintingDocument10 pagesThe Classification of Style in Fine-Art PaintingwobblegobbleNo ratings yet
- XL Miner User GuideDocument694 pagesXL Miner User Guideavi_281993No ratings yet
- CainterprtoolsDocument33 pagesCainterprtoolsapi-233997904No ratings yet
- Clustering of Time-Series DataDocument20 pagesClustering of Time-Series DataAyu SofiaNo ratings yet
- SPSS Tutorial Cluster AnalysisDocument42 pagesSPSS Tutorial Cluster AnalysisAnirban BhowmickNo ratings yet
- A Comparison of Document Clustering Techniques: 1 Background and MotivationDocument20 pagesA Comparison of Document Clustering Techniques: 1 Background and Motivationirisnellygomez4560No ratings yet
- 10.cluster AnalysisDocument68 pages10.cluster AnalysisironchefffNo ratings yet
- Chapter Twenty: Cluster AnalysisDocument46 pagesChapter Twenty: Cluster AnalysisYash GajwaniNo ratings yet
- Project Management Information Systems (PMISs) : A Statistical-Based Analysis For The Evaluation of Software Packages FeaturesDocument21 pagesProject Management Information Systems (PMISs) : A Statistical-Based Analysis For The Evaluation of Software Packages FeaturesDiana MacoveiNo ratings yet
- Introduction To Unsupervised Learning:: ClusteringDocument21 pagesIntroduction To Unsupervised Learning:: Clusteringmohini senNo ratings yet
- Survey of Clustering Algorithms: IEEE Transactions On Neural Networks June 2005Document35 pagesSurvey of Clustering Algorithms: IEEE Transactions On Neural Networks June 2005Laradj CHELLAMANo ratings yet