Download as pptx, pdf, or txt
You might also like
- De Mod 1 Get Started With Databricks Data Science and Engineering WorkspaceDocument27 pagesDe Mod 1 Get Started With Databricks Data Science and Engineering WorkspaceJaya BharathiNo ratings yet
- Resume 4Document4 pagesResume 4arvindh siddhuNo ratings yet
- Using Oracle Integration Cloud ServiceDocument286 pagesUsing Oracle Integration Cloud Servicechandan_infotechNo ratings yet
- System Software: An Introduction To Systems Programming Leland L. Beck 3rd Edition Addison-Wesley, 1997Document40 pagesSystem Software: An Introduction To Systems Programming Leland L. Beck 3rd Edition Addison-Wesley, 1997Shoyab Ahamed50% (4)
- JSONDocument45 pagesJSONPriyanka KaliyaperumalNo ratings yet
- How-To - Install CDH On Mac OSX 10Document20 pagesHow-To - Install CDH On Mac OSX 10archsarkNo ratings yet
- EC2 NotesDocument10 pagesEC2 NotesTarun SinghNo ratings yet
- Cloudera Developer Training Exercise ManualDocument131 pagesCloudera Developer Training Exercise ManualKhusaila Toufali LapazNo ratings yet
- Karens ResumeDocument1 pageKarens Resumekaren100% (1)
- Data Warehouse QuesDocument10 pagesData Warehouse Quesviswanath12No ratings yet
- JAVA and Front PageDocument6 pagesJAVA and Front PageETL LABS0% (1)
- Extract Transform LoadDocument80 pagesExtract Transform LoadLy Nguyễn HươngNo ratings yet
- AWS Certified Solutions Architect Associate Training IpsrDocument8 pagesAWS Certified Solutions Architect Associate Training Ipsrriya vargheseNo ratings yet
- Oracle Forms MaterialDocument114 pagesOracle Forms MaterialNainika KedarisettiNo ratings yet
- PandasDocument16 pagesPandasHoneyNo ratings yet
- Creating A Custom NET Activity PipeLine For Azure Data FactoryDocument18 pagesCreating A Custom NET Activity PipeLine For Azure Data Factorycesarff2No ratings yet
- Api JsonDocument64 pagesApi JsonrimalionNo ratings yet
- HardiksResume 1Document2 pagesHardiksResume 1Time PassNo ratings yet
- Snowflake FS - 20211030Document82 pagesSnowflake FS - 20211030Wings QiNo ratings yet
- 2 Rupesha Patel Oracle DBA 1+yearDocument2 pages2 Rupesha Patel Oracle DBA 1+yearPraveen Kumar MadupuNo ratings yet
- Akhil Data+Engineer1Document5 pagesAkhil Data+Engineer1Vivek SagarNo ratings yet
- Manideep LenkalapallyDocument7 pagesManideep LenkalapallyNoor Ayesha IqbalNo ratings yet
- Google Cloud PlatformDocument17 pagesGoogle Cloud PlatformGOKUL55No ratings yet
- Kanishk ResumeDocument5 pagesKanishk ResumeHarshvardhini MunwarNo ratings yet
- 1.8 Database and Data ModellingDocument137 pages1.8 Database and Data ModellingMaaz Bin AliNo ratings yet
- Python Best Interview Question CollectionDocument182 pagesPython Best Interview Question Collectionpalanivel0% (1)
- Ui Notes'Document31 pagesUi Notes'Vindhya Mounika PatnaikNo ratings yet
- Digital Finance - Data Engineering LeadDocument3 pagesDigital Finance - Data Engineering LeadAlejandro ManzanelliNo ratings yet
- Real Time Analytics Spark Streaming PDFDocument20 pagesReal Time Analytics Spark Streaming PDFKyuseok LeeNo ratings yet
- Private Endpoint Connection Command GuidelineDocument4 pagesPrivate Endpoint Connection Command GuidelineSec AboutNo ratings yet
- MV Refresh ParallelDocument37 pagesMV Refresh ParallelBiplab ParidaNo ratings yet
- AX 70 AdministratorGuide enDocument120 pagesAX 70 AdministratorGuide enPrateek SinhaNo ratings yet
- Unix CommandsDocument5 pagesUnix Commandsmalleswari ChNo ratings yet
- Kubernetes NotesDocument36 pagesKubernetes NotesTarun SinghNo ratings yet
- In 101 AdministratorGuide enDocument339 pagesIn 101 AdministratorGuide enGanesh ChimmaniNo ratings yet
- CON8567 Abushaban Exadata EM12cDocument64 pagesCON8567 Abushaban Exadata EM12cgirglNo ratings yet
- Using Netcore Docker and Kubernetes SuccinctlyDocument91 pagesUsing Netcore Docker and Kubernetes SuccinctlyAnilKumarRamisetty100% (1)
- Hands-On Lab Guide For: Virtual Zero-To-SnowflakeDocument63 pagesHands-On Lab Guide For: Virtual Zero-To-Snowflakenischal vadariNo ratings yet
- Introduction To SQLDocument120 pagesIntroduction To SQLamanblr12100% (1)
- AWS Oracle DB Migration QuestionnaireDocument2 pagesAWS Oracle DB Migration QuestionnaireAvineet AgarwallaNo ratings yet
- On Python For Mechanical Engineers Internship: Carried Out at Decibels Lab PVT LTDDocument15 pagesOn Python For Mechanical Engineers Internship: Carried Out at Decibels Lab PVT LTDUmesh KashiNo ratings yet
- Interview-Shell ScriptingDocument31 pagesInterview-Shell ScriptingSanket PandhareNo ratings yet
- Apache Spark Interview GuideDocument22 pagesApache Spark Interview GuideVenmo 61930% (1)
- Chandra Mouli .B Mobile: 7338778089: Professional SkillsDocument3 pagesChandra Mouli .B Mobile: 7338778089: Professional SkillsNageswara RaoNo ratings yet
- Rest API Python GuideDocument13 pagesRest API Python GuidehabibNo ratings yet
- PLSQL TutorialDocument129 pagesPLSQL Tutorialstone kleverNo ratings yet
- Migrating Discoverer To Obie e Lessons LearnedDocument27 pagesMigrating Discoverer To Obie e Lessons LearnedJitendra KumarNo ratings yet
- Apache Spark EngineDocument82 pagesApache Spark EngineAMAL NEJJARI100% (1)
- Key Flex Field StructuresDocument5 pagesKey Flex Field Structuresnagarajuvcc123No ratings yet
- Data WarehousingDocument22 pagesData WarehousingLucia MakwashaNo ratings yet
- SHELL SCRIPTING - MergedDocument47 pagesSHELL SCRIPTING - Mergedrohit kumarNo ratings yet
- Spring Data JPADocument12 pagesSpring Data JPATejasri 001No ratings yet
- Mandapriyanka (7 0)Document3 pagesMandapriyanka (7 0)kmrulesNo ratings yet
- IT Elect 1 - Mobile Programming 1 - 1sem - SY2023Document10 pagesIT Elect 1 - Mobile Programming 1 - 1sem - SY2023Aaron Jude PaelNo ratings yet
- AZ-900 Study Guide-3Document14 pagesAZ-900 Study Guide-3Juan GarciaNo ratings yet
- OU - 1Z0 931 Autonomous Database Specialist 2019 Exam Prep GuideDocument9 pagesOU - 1Z0 931 Autonomous Database Specialist 2019 Exam Prep GuidecssundarNo ratings yet
- Notes - UP MODULE 1Document47 pagesNotes - UP MODULE 1kavitha GLNo ratings yet
- ADF Upload Blob File in Table ColumnDocument34 pagesADF Upload Blob File in Table ColumnNageswara Reddy100% (1)
- Ashok 2+Document4 pagesAshok 2+Ram RamarajuNo ratings yet
- Operating Manual: Power / Phase Angle / Power Factor TransducerDocument44 pagesOperating Manual: Power / Phase Angle / Power Factor TransducerpadmawarNo ratings yet
- Where, Is A Complex Exponential Magnitude & Angle: X (Z) X N ZDocument26 pagesWhere, Is A Complex Exponential Magnitude & Angle: X (Z) X N Zanil kadleNo ratings yet
- Replace Drive Solaris ZfsDocument4 pagesReplace Drive Solaris ZfsJimbo PardedeNo ratings yet
- Mystic Light 3 ReleaseNoteDocument12 pagesMystic Light 3 ReleaseNotejoshfartNo ratings yet
- Manual SDR Con App enDocument118 pagesManual SDR Con App enmartelldronesvNo ratings yet
- Read Only View Rel11 V2Document6 pagesRead Only View Rel11 V2sureshNo ratings yet
- Ekspert ultraLC 100-XL 110-XLDocument54 pagesEkspert ultraLC 100-XL 110-XLVane F. QuijonNo ratings yet
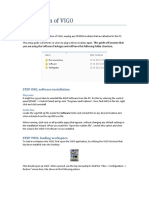
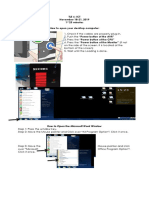
- Installation of VIGODocument11 pagesInstallation of VIGOAhmedhassan KhanNo ratings yet
- Lab 5: The FFT and Digital Filtering: 1. GoalsDocument3 pagesLab 5: The FFT and Digital Filtering: 1. GoalsTrung LyamNo ratings yet
- ThreadsDocument26 pagesThreadsNageswara DanikondaNo ratings yet
- CSC 403Document24 pagesCSC 403Mamee SkNo ratings yet
- اساسيات الشبكات - مكتبة زادDocument18 pagesاساسيات الشبكات - مكتبة زادسيد بن بشر بشرNo ratings yet
- A Hybrid Machine Learning Method For Estimating Software Project CostDocument7 pagesA Hybrid Machine Learning Method For Estimating Software Project CostInternational Journal of Innovative Science and Research Technology100% (1)
- Park+ Proposal Capex Himalaya Pride Plan 2Document2 pagesPark+ Proposal Capex Himalaya Pride Plan 2ritikaNo ratings yet
- 02 Electronic Spreadsheet Advanced Revision NotesDocument8 pages02 Electronic Spreadsheet Advanced Revision NotesumaNo ratings yet
- Assignment 3Document8 pagesAssignment 3Saima MoustakNo ratings yet
- Tle 6Document9 pagesTle 6Jessieca Aday SagerNo ratings yet
- Enabling Developer Mode On A Device - Apple Developer DocumentationDocument3 pagesEnabling Developer Mode On A Device - Apple Developer DocumentationdeluxepowerNo ratings yet
- DX DiagDocument48 pagesDX DiagLeonardo MonacoNo ratings yet
- GOT Simple SeriesDocument40 pagesGOT Simple SeriesVirendra ZopeNo ratings yet
- ActiveViam White Paper - Achieving Better Product ControlDocument14 pagesActiveViam White Paper - Achieving Better Product Controlbabitasaini6402No ratings yet
- Public Vs Private BlockchainDocument45 pagesPublic Vs Private BlockchainAnandapadmanaban Muralidharan MuralidharanNo ratings yet
- 250 250 Exam Questions Answers PDFDocument7 pages250 250 Exam Questions Answers PDFMatthew MathewsNo ratings yet
- Animatronics DocumentationDocument31 pagesAnimatronics DocumentationK TEJA DEEPNo ratings yet
- Brigada Eskwela Form 2 School Work PlanDocument2 pagesBrigada Eskwela Form 2 School Work PlanDawnNo ratings yet
- Docker For TeenagersDocument19 pagesDocker For TeenagersAntony Kervazo-CanutNo ratings yet
- B. Router B C. Router C D. Router ADocument8 pagesB. Router B C. Router C D. Router AAdi TrimuktiNo ratings yet
- Literature Review On The Impact of Information Technology in BankingDocument8 pagesLiterature Review On The Impact of Information Technology in BankingafmztwoalwbteqNo ratings yet