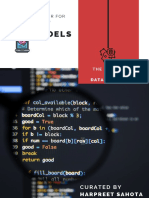
Download as pptx, pdf, or txt
You might also like
- DL Unit-2Document24 pagesDL Unit-2Kalpana MNo ratings yet
- Unit 02 - Nonlinear Classification, Linear Regression, Collaborative Filtering - MDDocument14 pagesUnit 02 - Nonlinear Classification, Linear Regression, Collaborative Filtering - MDMega Silvia HasugianNo ratings yet
- 120 DS-With AnswerDocument32 pages120 DS-With AnswerAsim Mazin100% (1)
- Interview Questions MLDocument83 pagesInterview Questions MLkprdeepak100% (1)
- Ds 9Document16 pagesDs 9Jayanth RagavNo ratings yet
- Ds 8Document10 pagesDs 8hkhandelwal2003No ratings yet
- Ds 10Document24 pagesDs 10Jglewd 2641No ratings yet
- Ds 12Document12 pagesDs 12Jayanth RagavNo ratings yet
- Ds 5Document13 pagesDs 5Jglewd 2641No ratings yet
- Ds 10Document15 pagesDs 10Jayanth RagavNo ratings yet
- Ds 11Document19 pagesDs 11Jayanth RagavNo ratings yet
- Building and Evaluating ML ModelsDocument27 pagesBuilding and Evaluating ML ModelsEliana MoralesNo ratings yet
- SSRN Id3177534 PDFDocument11 pagesSSRN Id3177534 PDFRajesh LalNo ratings yet
- Introduction To Machine Learning: The Problem of OverfittingDocument8 pagesIntroduction To Machine Learning: The Problem of OverfittingMuneeb ButtNo ratings yet
- ML Questions 2021Document26 pagesML Questions 2021Aamir Ali100% (1)
- Robot Reliability Through Fuzzy Markov Models: February 1998Document7 pagesRobot Reliability Through Fuzzy Markov Models: February 1998StanislavNo ratings yet
- Lec04 - The Most Confident ClassifierDocument14 pagesLec04 - The Most Confident ClassifierJOHNNo ratings yet
- Aws ML PDFDocument74 pagesAws ML PDFRajat ShrinetNo ratings yet
- Selecting Reference Location For Modal TestingDocument2 pagesSelecting Reference Location For Modal Testingcelestinodl736No ratings yet
- Machine Learning and Pattern Recognition Week 8 - Neural - Net - FittingDocument3 pagesMachine Learning and Pattern Recognition Week 8 - Neural - Net - FittingzeliawillscumbergNo ratings yet
- PS Notes (Machine LearningDocument14 pagesPS Notes (Machine LearningKodjo ALIPUINo ratings yet
- Lecture 12 - Probabilistic ML (4) - MAP Estimation and Bayesian Inference - PlainDocument15 pagesLecture 12 - Probabilistic ML (4) - MAP Estimation and Bayesian Inference - PlainRajachandra VoodigaNo ratings yet
- Applications of DerivativesDocument17 pagesApplications of DerivativesAshitha JoseNo ratings yet
- Scimakelatex 7653 Bna+BlaDocument6 pagesScimakelatex 7653 Bna+BlaJuhász TamásNo ratings yet
- Machine LearningDocument16 pagesMachine LearningZhivko ZhelyazkovNo ratings yet
- Ds 9Document17 pagesDs 9Jglewd 2641No ratings yet
- Lecture 27 - Latent Variable Models (2) - P1 - PlainDocument11 pagesLecture 27 - Latent Variable Models (2) - P1 - PlainRajachandra VoodigaNo ratings yet
- Neural Networks Cheat Sheet - 2020 PDFDocument14 pagesNeural Networks Cheat Sheet - 2020 PDFjoseacvNo ratings yet
- Ciml v0 - 99 ch02 PDFDocument10 pagesCiml v0 - 99 ch02 PDFpokospikosNo ratings yet
- CS550 Lec2Document24 pagesCS550 Lec2dipsresearchNo ratings yet
- Generalized Linear Mixed Models (Illustrated With R On Bresnan Et Al.'s Datives Data)Document40 pagesGeneralized Linear Mixed Models (Illustrated With R On Bresnan Et Al.'s Datives Data)pauloyyjNo ratings yet
- Course Notes Section 2Document14 pagesCourse Notes Section 2Aravind GunaNo ratings yet
- Intro 4 - Substantive Concepts: Description Remarks and Examples References Also SeeDocument19 pagesIntro 4 - Substantive Concepts: Description Remarks and Examples References Also SeeAntonella PetrilloNo ratings yet
- Lecture 11 - Probabilistic ML (3) - Parameter Estimation - PlainDocument8 pagesLecture 11 - Probabilistic ML (3) - Parameter Estimation - PlainRajachandra VoodigaNo ratings yet
- Get Your Doc Derivatives 13Document42 pagesGet Your Doc Derivatives 13acmcNo ratings yet
- Machine Learning and Pattern Recognition Bayesian Complexity ControlDocument4 pagesMachine Learning and Pattern Recognition Bayesian Complexity ControlzeliawillscumbergNo ratings yet
- Machine Lpipearning Interview Questions: Algorithms/Tp: Q1-What's The Trade-Off Between Bias and Variance?Document46 pagesMachine Lpipearning Interview Questions: Algorithms/Tp: Q1-What's The Trade-Off Between Bias and Variance?ChinmoyDasNo ratings yet
- Measuring Compositionality Gap in LLMsDocument25 pagesMeasuring Compositionality Gap in LLMsJuan BrugadaNo ratings yet
- Ciml v0 - 99 ch05 PDFDocument18 pagesCiml v0 - 99 ch05 PDFpokospikosNo ratings yet
- Robot Reliability Through Fuzzy Markov M PDFDocument6 pagesRobot Reliability Through Fuzzy Markov M PDFDaniel CarvalhoNo ratings yet
- Supervised Regression NotesDocument11 pagesSupervised Regression Notesneeharika.sssvvNo ratings yet
- Introtodeeplearning MIT 6.S191Document36 pagesIntrotodeeplearning MIT 6.S191jayateerthaNo ratings yet
- Linear Models: CS771: Introduction To Machine Learning Piyush RaiDocument8 pagesLinear Models: CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- 4538-Article Text-7577-2-10-20190729Document8 pages4538-Article Text-7577-2-10-20190729vinay thakarNo ratings yet
- 40 Interview Questions On Machine Learning From Analytics VidhyaDocument14 pages40 Interview Questions On Machine Learning From Analytics Vidhyashakir aliNo ratings yet
- Interview Questions On Machine LearningDocument22 pagesInterview Questions On Machine LearningPraveen100% (4)
- Random Forest (RF) : Decision TreesDocument3 pagesRandom Forest (RF) : Decision TreesDivya NegiNo ratings yet
- Scimakelatex 25298 Us ThemDocument7 pagesScimakelatex 25298 Us Themmdp anonNo ratings yet
- The Problem of Overfitting: Overfitting With Linear RegressionDocument32 pagesThe Problem of Overfitting: Overfitting With Linear RegressionPallab PuriNo ratings yet
- Regularization PDFDocument32 pagesRegularization PDFDimas WihandonoNo ratings yet
- 6 - Support Vector MachinesDocument14 pages6 - Support Vector MachinesdeepikasahumorNo ratings yet
- How Large Is Your Training Set?Document2 pagesHow Large Is Your Training Set?slimpiaNo ratings yet
- Machine Learning 6Document28 pagesMachine Learning 6barkha saxenaNo ratings yet
- Tutorial On Variational Autoencoders: C D Carnegie Mellon / UC BerkeleyDocument23 pagesTutorial On Variational Autoencoders: C D Carnegie Mellon / UC BerkeleyTTNo ratings yet
- Unit 1b - Fundamentals of Machine LearningDocument31 pagesUnit 1b - Fundamentals of Machine LearningEsha Thaniya MallaNo ratings yet
- Data Science Interview QnAs by CloudyMLDocument21 pagesData Science Interview QnAs by CloudyMLmacoyigNo ratings yet
- Convolutions in NLP - Paris NLP Meetup: FollowDocument12 pagesConvolutions in NLP - Paris NLP Meetup: FollowccodriciNo ratings yet
- 13 Ensemble MethodsDocument7 pages13 Ensemble MethodsJiahong HeNo ratings yet
- Monte CarloDocument59 pagesMonte Carloadiraju07No ratings yet
- Tut02 - Calculus Crash CourseDocument24 pagesTut02 - Calculus Crash CourseJglewd 2641No ratings yet
- Lec02 ML VariantsDocument18 pagesLec02 ML VariantsJglewd 2641No ratings yet
- Stat RefDocument37 pagesStat RefJglewd 2641No ratings yet
- Prob RefDocument39 pagesProb RefJglewd 2641No ratings yet
- Lec03 Building BlocksDocument22 pagesLec03 Building BlocksJglewd 2641No ratings yet
- Lec01 Getting StartedDocument13 pagesLec01 Getting StartedJglewd 2641No ratings yet
- Ds 7Document21 pagesDs 7Jglewd 2641No ratings yet
- Ds 10Document24 pagesDs 10Jglewd 2641No ratings yet
- Ds 9Document17 pagesDs 9Jglewd 2641No ratings yet
- Ds 6Document21 pagesDs 6Jglewd 2641No ratings yet
- Ds 5Document13 pagesDs 5Jglewd 2641No ratings yet
- Discussion 4 CS771Document25 pagesDiscussion 4 CS771Jglewd 2641No ratings yet
- Discussion 1 CS771Document17 pagesDiscussion 1 CS771Jglewd 2641No ratings yet
- Discussion 3 CS771Document23 pagesDiscussion 3 CS771Jglewd 2641No ratings yet
- Discussion 2 CS771Document16 pagesDiscussion 2 CS771Jglewd 2641No ratings yet
- Polya Note PDFDocument7 pagesPolya Note PDFNashitah Abd KadirNo ratings yet
- Bayes HandoutDocument17 pagesBayes Handoutrevathy1988No ratings yet
- Neural Correlates of Learning Accommodation and Consolidation in Generalised Anxiety DisorderDocument8 pagesNeural Correlates of Learning Accommodation and Consolidation in Generalised Anxiety DisorderJ MrNo ratings yet
- M.R. Tarafder, H. Carabin, L. Joseph, E. Balolong JR., R. Olveda, S.T. McgarveyDocument6 pagesM.R. Tarafder, H. Carabin, L. Joseph, E. Balolong JR., R. Olveda, S.T. McgarveySharmain Pranne Dulnuan NgipolNo ratings yet
- Co VariateDocument30 pagesCo Variateastari rahmaditaNo ratings yet
- Decision TreeDocument31 pagesDecision TreeAnwesha Dev ChaudharyNo ratings yet
- An Introduction To Objective Bayesian Statistics PDFDocument69 pagesAn Introduction To Objective Bayesian Statistics PDFWaterloo Ferreira da SilvaNo ratings yet
- CH 15 TestDocument21 pagesCH 15 TestDaniel HunksNo ratings yet
- Maximum Entropy DistributionDocument11 pagesMaximum Entropy DistributionsurvinderpalNo ratings yet
- A Third Route To Doomsday ArgumentDocument15 pagesA Third Route To Doomsday ArgumentnovriadyNo ratings yet
- Lecture 7 DynareDocument46 pagesLecture 7 DynareNaty GarridoNo ratings yet
- SCT - QB - Anwers - p1Document53 pagesSCT - QB - Anwers - p1hijaNo ratings yet
- Design of Experiments An Introduction BaDocument30 pagesDesign of Experiments An Introduction Bastck_hrNo ratings yet
- Introduce To Probabilistic Machine LearningDocument53 pagesIntroduce To Probabilistic Machine LearningPin WangNo ratings yet
- Package BMA': R Topics DocumentedDocument47 pagesPackage BMA': R Topics DocumentedNeilFaverNo ratings yet
- Edu 2009 Fall Exam C Questions PDFDocument172 pagesEdu 2009 Fall Exam C Questions PDFCamila Andrea Sarmiento BetancourtNo ratings yet
- UMBayesAdaptIntro SM2Document64 pagesUMBayesAdaptIntro SM2SergioDragomiroffNo ratings yet
- Bayes Rule, Prior, PosteriorDocument10 pagesBayes Rule, Prior, PosteriorVanlal KhiangteNo ratings yet
- UNIT 3-Bayesian StatisticsDocument80 pagesUNIT 3-Bayesian StatisticsfhjhgjhNo ratings yet
- Bayesian Learning: Salma Itagi, SvitDocument14 pagesBayesian Learning: Salma Itagi, SvitSuhas NSNo ratings yet
- (Encyclopaedia of Mathematics 1) M. Hazewinkel (Auth.), M. Hazewinkel (Eds.) - Encyclopaedia of Mathematics-Springer Netherlands (1987)Document495 pages(Encyclopaedia of Mathematics 1) M. Hazewinkel (Auth.), M. Hazewinkel (Eds.) - Encyclopaedia of Mathematics-Springer Netherlands (1987)bwpbruce100% (2)
- PPT05-Quantifying UncertaintyDocument39 pagesPPT05-Quantifying UncertaintyVeri VeriNo ratings yet
- Elements of Econometrics by Jan Kmenta ZDocument808 pagesElements of Econometrics by Jan Kmenta ZJeetu Sharma0% (1)
- Bayesian Approach For Animal Breeding Data AnalysisDocument42 pagesBayesian Approach For Animal Breeding Data AnalysisGopal Gowane50% (2)
- MLE and MAP ClassifierDocument55 pagesMLE and MAP ClassifierSupriyo ChakmaNo ratings yet
- Bayesian NonparametricsDocument60 pagesBayesian NonparametricsZeferinixNo ratings yet
- Probability EstimationDocument11 pagesProbability EstimationYash PokernaNo ratings yet
- Bayesian Learning Introduction Bayes08 PDFDocument65 pagesBayesian Learning Introduction Bayes08 PDFrcoca_1No ratings yet
- 25-27 Statistical Reasoning-Probablistic Model-Naive Bayes ClassifierDocument35 pages25-27 Statistical Reasoning-Probablistic Model-Naive Bayes ClassifierDaniel LivingstonNo ratings yet