Download as ppt, pdf, or txt
You might also like
- Chapter8 AnsDocument9 pagesChapter8 Ansgabboudeh100% (1)
- Lab Report On False Position Method: Assignment 3Document9 pagesLab Report On False Position Method: Assignment 3Samixa TimalcenaNo ratings yet
- R7410201 Neural Networks and Fuzzy LogicDocument1 pageR7410201 Neural Networks and Fuzzy LogicsivabharathamurthyNo ratings yet
- Modularisation and General Algorithms For Common Business ProblemsDocument64 pagesModularisation and General Algorithms For Common Business ProblemsMuhammad RafifNo ratings yet
- Data and Computer CommunicationsDocument32 pagesData and Computer CommunicationssantanoopNo ratings yet
- Data and Computer CommunicationsDocument32 pagesData and Computer Communicationschellam1_kalaiNo ratings yet
- Data and Computer Communications: - Routing in Switched NetworksDocument32 pagesData and Computer Communications: - Routing in Switched NetworksSandhya PandeyNo ratings yet
- Week 11 Switched NetworksDocument33 pagesWeek 11 Switched NetworksFaheemNo ratings yet
- Revision Before Studying Routing in ManetDocument20 pagesRevision Before Studying Routing in ManetAzmat Ali ShahNo ratings yet
- Routing in Circuit Switched NT K NetworkDocument34 pagesRouting in Circuit Switched NT K NetworkchilledkarthikNo ratings yet
- Shortest Path Algorithm: - Dijkstra's - Bellman-FordDocument18 pagesShortest Path Algorithm: - Dijkstra's - Bellman-Fordwork8No ratings yet
- Network LayerDocument18 pagesNetwork LayerChamara PrasannaNo ratings yet
- Lecture Routing 1 18 April 2022Document66 pagesLecture Routing 1 18 April 2022Dinkar Laxman BhombeNo ratings yet
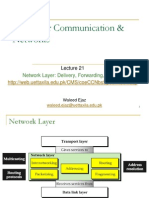
- Computer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingDocument36 pagesComputer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingAli AhmadNo ratings yet
- CN04-Routing (Types and Algorithms)Document38 pagesCN04-Routing (Types and Algorithms)Emad Samir FarahatNo ratings yet
- CS 408 Computer Networks: Chapter 11: Routing in IPDocument54 pagesCS 408 Computer Networks: Chapter 11: Routing in IPThuu Wien Tya EwieNo ratings yet
- Unit 4 Network LayerDocument43 pagesUnit 4 Network LayerRahul ChugwaniNo ratings yet
- What Is Routing AlgorithmDocument12 pagesWhat Is Routing AlgorithmTum BinNo ratings yet
- Functions of Network Layer Routing TableDocument4 pagesFunctions of Network Layer Routing TableAkshay VNo ratings yet
- Routing Algorithms (Distance Vector, Link State) Study Notes - Computer Sc. & EnggDocument6 pagesRouting Algorithms (Distance Vector, Link State) Study Notes - Computer Sc. & Enggkavya associatesNo ratings yet
- A B C D R2 R4: Source RouterDocument15 pagesA B C D R2 R4: Source Routerabhilashsjce100% (1)
- Unit 8Document14 pagesUnit 8Subeksha PiyaNo ratings yet
- Document From Harini.Document24 pagesDocument From Harini.prasannakarthik957No ratings yet
- Chapter 19 RoutingDocument26 pagesChapter 19 RoutingSardar Amandeep SinghNo ratings yet
- Chapter 4 Bit4001+q+ExDocument77 pagesChapter 4 Bit4001+q+ExĐình Đức PhạmNo ratings yet
- The Network Layer Is Concerned With GettingDocument103 pagesThe Network Layer Is Concerned With GettingsrinusirisalaNo ratings yet
- NetworkLayer RoutingDocument64 pagesNetworkLayer RoutingDrashtiNo ratings yet
- Module - 3 Network LayerDocument27 pagesModule - 3 Network Layer1NC21IS033 Manoj jayanth NNo ratings yet
- CN - UNIT 3 NewDocument30 pagesCN - UNIT 3 NewVarun TyagiNo ratings yet
- CN Unit 4Document22 pagesCN Unit 4PrateekNo ratings yet
- A Performance Comparison of Multi-Hop Wireless Ad Hoc Network Routing ProtocolsDocument41 pagesA Performance Comparison of Multi-Hop Wireless Ad Hoc Network Routing ProtocolsShiv Prasad ChoudharyNo ratings yet
- Lecture 8 and 9Document49 pagesLecture 8 and 9Abraham GadissaNo ratings yet
- ECE 695N Final Project: Ravish Khosla April 22, 2010Document15 pagesECE 695N Final Project: Ravish Khosla April 22, 2010Osidibo Bayuu LivelifeNo ratings yet
- Network Layer (Continued... )Document9 pagesNetwork Layer (Continued... )Delli HarinNo ratings yet
- CEG5103 EE5023 L3-Routing - Ann290124Document26 pagesCEG5103 EE5023 L3-Routing - Ann290124xuwumiao7No ratings yet
- Loop-Free Routing Using Diffusing Computations: Abstract-ADocument12 pagesLoop-Free Routing Using Diffusing Computations: Abstract-Anguyendanhson1409No ratings yet
- CH 2424042408Document5 pagesCH 2424042408IJMERNo ratings yet
- Routing For BCADocument35 pagesRouting For BCAPratibhaNo ratings yet
- Routing in Packet Switching NetworksDocument52 pagesRouting in Packet Switching NetworksSuranga SampathNo ratings yet
- Data and Computer CommunicationsDocument31 pagesData and Computer CommunicationsMogahed SemyNo ratings yet
- NetworkLayer RoutingDocument64 pagesNetworkLayer RoutingRishiGuptaNo ratings yet
- Lecture #5 THRDocument45 pagesLecture #5 THRZainab ShahzadNo ratings yet
- L2 - Mobile Ad Hoc NetworksDocument61 pagesL2 - Mobile Ad Hoc NetworkskristofferNo ratings yet
- Computer Networks (CS425) : Routing AlgorithmsDocument5 pagesComputer Networks (CS425) : Routing AlgorithmsAnish VeettiyankalNo ratings yet
- Store and Forward Packet SwitchingDocument22 pagesStore and Forward Packet SwitchingKevin PanuelosNo ratings yet
- Distance Vector RoutingDocument3 pagesDistance Vector RoutingKarthik SNo ratings yet
- Mobile Ad Hoc Routing ProtocolDocument47 pagesMobile Ad Hoc Routing ProtocolshashiNo ratings yet
- 07 Network Layer Print PDFDocument26 pages07 Network Layer Print PDFMatthew BattleNo ratings yet
- All Units - Notes - CNDocument406 pagesAll Units - Notes - CN160520737050No ratings yet
- Network LayerDocument38 pagesNetwork LayerSoccho cocNo ratings yet
- Performance Comparison of Ad Hoc Routing Protocols Over IEEE 802.11 DCF and TDMA MAC Layer ProtocolsDocument5 pagesPerformance Comparison of Ad Hoc Routing Protocols Over IEEE 802.11 DCF and TDMA MAC Layer ProtocolsSatish KedarNo ratings yet
- Chapter 4 - Routing and Routing ProtocolsDocument41 pagesChapter 4 - Routing and Routing Protocolstesfahuntilahun44No ratings yet
- Unit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)Document28 pagesUnit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)karthik vaddiNo ratings yet
- Link State RouterDocument19 pagesLink State RouterxxxNo ratings yet
- Unit 3Document31 pagesUnit 320H51A04P3-PEDAPUDI SHAKTHI GANESH B.Tech ECE (2020-24)No ratings yet
- 04 RoutingDocument40 pages04 RoutingSAYAN DASNo ratings yet
- Routing Protocol & AlgorithmsDocument45 pagesRouting Protocol & AlgorithmsVikas PsNo ratings yet
- On-Demand Multicast Routing Protocol in Multihop Wireless Mobile Networks (ODMRP)Document21 pagesOn-Demand Multicast Routing Protocol in Multihop Wireless Mobile Networks (ODMRP)ShanmugapriyaVinodkumarNo ratings yet
- CNModel2 Answer KeyDocument27 pagesCNModel2 Answer KeyAnitha MNo ratings yet
- Static Vs Dynamic: Routing AlgorithmDocument10 pagesStatic Vs Dynamic: Routing AlgorithmAnjuPandeyNo ratings yet
- Physical Layer-SwitchingDocument42 pagesPhysical Layer-SwitchingPalashAhujaNo ratings yet
- CNS Mod 3 NLDocument23 pagesCNS Mod 3 NLSamanthNo ratings yet
- 4.6 Principle of Pattern MultiplicationDocument16 pages4.6 Principle of Pattern MultiplicationAbdul RahmanNo ratings yet
- Ip AddressDocument22 pagesIp AddressAbdul RahmanNo ratings yet
- Appointment RecieptDocument3 pagesAppointment RecieptAbdul RahmanNo ratings yet
- Blue Tooth Protocol StackDocument8 pagesBlue Tooth Protocol StackAbdul RahmanNo ratings yet
- RoutingDocument66 pagesRoutingAbdul RahmanNo ratings yet
- Major ProjectDocument17 pagesMajor ProjectAbdul RahmanNo ratings yet
- Csen 2101Document2 pagesCsen 2101Bipin kumarNo ratings yet
- Python Practical Record AnnaDocument69 pagesPython Practical Record AnnaGunjan JainNo ratings yet
- Solution To CS 5104 Take-Home QuizDocument2 pagesSolution To CS 5104 Take-Home QuizkhawarbashirNo ratings yet
- Time ComplexityDocument13 pagesTime Complexityapi-3814408100% (1)
- Design of Algorithms AssignmentDocument17 pagesDesign of Algorithms AssignmentKudakwasheNo ratings yet
- Machine Learning QBDocument3 pagesMachine Learning QBJyotsna SuraydevaraNo ratings yet
- Lab Manual Bca 3 Sem Data Structures-IDocument16 pagesLab Manual Bca 3 Sem Data Structures-IdineshNo ratings yet
- 1Document2 pages1Keith D'souzaNo ratings yet
- Interview Preparation KitDocument132 pagesInterview Preparation KitSus ManNo ratings yet
- Dsa - Two Marks All UnitsDocument18 pagesDsa - Two Marks All Unitsgayanar rNo ratings yet
- Characteristics of Data StructuresDocument2 pagesCharacteristics of Data Structuresjosh.molinaNo ratings yet
- Deep Dive PytorchDocument986 pagesDeep Dive PytorchKaushik SivashankarNo ratings yet
- Integerprogramming Chapter 4Document60 pagesIntegerprogramming Chapter 4Frew Tadesse FreNo ratings yet
- Btech Cs 7 Sem Application of Soft Computing rcs071 2020Document2 pagesBtech Cs 7 Sem Application of Soft Computing rcs071 2020Lalit SaraswatNo ratings yet
- Sample Linked Lists Chapter (Data Structure and Algorithmic Thinking With Python)Document47 pagesSample Linked Lists Chapter (Data Structure and Algorithmic Thinking With Python)Karthikeyan BalasubramaniamNo ratings yet
- Ads Lab RecordDocument44 pagesAds Lab Recordsandeepabi25No ratings yet
- Phrase: Assumptions: The Two Cells On The Ends Have Single Adjacent Cell, So The OtherDocument10 pagesPhrase: Assumptions: The Two Cells On The Ends Have Single Adjacent Cell, So The OthershivNo ratings yet
- 1997 Bison A Fast Hybrid Procedure For Exactly Solving BPPDocument19 pages1997 Bison A Fast Hybrid Procedure For Exactly Solving BPPaegr82No ratings yet
- Daa SBDocument9 pagesDaa SBSoumyajit BagNo ratings yet
- JAVA - Slips 1-15Document67 pagesJAVA - Slips 1-15OM67% (3)
- Solu 3Document28 pagesSolu 3Aswani Kumar100% (2)
- Cse 5Document4 pagesCse 5Riya PatilNo ratings yet
- CSCI2520 Tutorial 3 (Week 4) : Hashtable: Gjchen@cse - Cuhk.edu - HKDocument23 pagesCSCI2520 Tutorial 3 (Week 4) : Hashtable: Gjchen@cse - Cuhk.edu - HKLeung Shing HeiNo ratings yet
- PB Algo2 2013 PDFDocument87 pagesPB Algo2 2013 PDFHeeramaniNo ratings yet
- Mid-Term QuestionsDocument5 pagesMid-Term QuestionsAhmed Samyan MidyatyNo ratings yet