
Big Data
Big Data
You might also like
- CO2-Reducing Cement Based On Calcium SilicatesDocument9 pagesCO2-Reducing Cement Based On Calcium Silicatesyinglv100% (1)
- Clark LundbergDocument3 pagesClark Lundbergms. bee0% (1)
- Likert Scales: How To (Ab) Use Them Susan JamiesonDocument8 pagesLikert Scales: How To (Ab) Use Them Susan JamiesonFelipe Santana LopesNo ratings yet
- What Is Difference Between Data Warehouse and Big DataDocument8 pagesWhat Is Difference Between Data Warehouse and Big Datakin bhNo ratings yet
- Hitachi White Paper Big Data InfrastructureDocument9 pagesHitachi White Paper Big Data InfrastructureMaurício ZanellaNo ratings yet
- Big Data Hadoop Training 8214944.ppsxDocument52 pagesBig Data Hadoop Training 8214944.ppsxhoukoumatNo ratings yet
- Big Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Document8 pagesBig Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Renuka PandeyNo ratings yet
- BIG DATA 1 UnitDocument17 pagesBIG DATA 1 UnitIshika SinghNo ratings yet
- Big Data (Unit 1)Document37 pagesBig Data (Unit 1)Shekhar KumarNo ratings yet
- Big Data 101 Brief PDFDocument4 pagesBig Data 101 Brief PDFAruna PattamNo ratings yet
- Module 2-4Document16 pagesModule 2-4lamiya kasimNo ratings yet
- Data Warehouse Literature ReviewDocument4 pagesData Warehouse Literature Reviewafmzubsbdcfffg100% (1)
- Big Data Storage: Margaret Rouse Garry KranzDocument6 pagesBig Data Storage: Margaret Rouse Garry KranzLotti LottiNo ratings yet
- Big DataDocument17 pagesBig DataJelinNo ratings yet
- What Is Big Data ?Document6 pagesWhat Is Big Data ?Meet MahidaNo ratings yet
- Unit I-KCS-061Document42 pagesUnit I-KCS-061aggarwalmohit813No ratings yet
- Big Data12Document11 pagesBig Data12Gustavo MercadoNo ratings yet
- Unit-5 DSDocument20 pagesUnit-5 DSrajkumarmtechNo ratings yet
- Big Data AnalyticsDocument21 pagesBig Data AnalyticsAasim SaifiNo ratings yet
- Big Data Analytics 1-5Document63 pagesBig Data Analytics 1-5Amani yar KhanNo ratings yet
- Big DataDocument6 pagesBig DataDivyasriNo ratings yet
- Big Data Analysis Using Hadoop and Mapreduce: Figure 1: World Wide Data Creation IndexDocument11 pagesBig Data Analysis Using Hadoop and Mapreduce: Figure 1: World Wide Data Creation Indexswapnil kaleNo ratings yet
- CSD 1043: Big Data Fundamentals Week1: Big Data Landscape: DefinitionsDocument13 pagesCSD 1043: Big Data Fundamentals Week1: Big Data Landscape: DefinitionsFernando Andrés Hinojosa VillarrealNo ratings yet
- CC Becse Unit 4 PDFDocument32 pagesCC Becse Unit 4 PDFRushikesh YadavNo ratings yet
- Big Data (Unit 1)Document38 pagesBig Data (Unit 1)moubais3143No ratings yet
- BIG DATA & Hadoop TutorialDocument23 pagesBIG DATA & Hadoop Tutorialsaif salahNo ratings yet
- Internet Technologies: By: Nandish Rao ADocument16 pagesInternet Technologies: By: Nandish Rao Amalini.kuppuraj1802No ratings yet
- Big Data: Presented By, Nishaa RDocument24 pagesBig Data: Presented By, Nishaa RNishaaNo ratings yet
- Harnessing Big DataDocument29 pagesHarnessing Big DataDipak ShowNo ratings yet
- Escritura 1Document7 pagesEscritura 1kennethNo ratings yet
- Ethiopin Tecica University Departement of Ict Cours Title: Big DataDocument15 pagesEthiopin Tecica University Departement of Ict Cours Title: Big DatagudissagabissaNo ratings yet
- WINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataDocument20 pagesWINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataSimritha RANo ratings yet
- Big Data With HadoopDocument26 pagesBig Data With Hadoopsonu samgeNo ratings yet
- UNIT-1 Bda KalyanDocument25 pagesUNIT-1 Bda KalyanKalyan KumarNo ratings yet
- Discuss The Characteristics of Big DataDocument2 pagesDiscuss The Characteristics of Big DataRhea EstavilloNo ratings yet
- Data StructuresDocument50 pagesData StructuresKoushik Raaj Radha KrishnanNo ratings yet
- Data Mining 1Document13 pagesData Mining 1Waleed RazaNo ratings yet
- Advanced DataBase AssignmentDocument8 pagesAdvanced DataBase AssignmentIbrahem RamadanNo ratings yet
- Bda - 1 UnitDocument21 pagesBda - 1 UnitASMA UL HUSNANo ratings yet
- Big Data SeminarDocument27 pagesBig Data SeminarAlemayehu Getachew100% (2)
- Big Data1Document9 pagesBig Data1JelinNo ratings yet
- Big Data Analytics (VN) 1Document98 pagesBig Data Analytics (VN) 1Veera NageswaranNo ratings yet
- Hadoop ReportDocument110 pagesHadoop ReportGahlot DivyanshNo ratings yet
- CC Unit 3 Imp QuestionsDocument15 pagesCC Unit 3 Imp QuestionsSahana UrsNo ratings yet
- The Emergence of "Big Data" Technology and AnalyticsDocument6 pagesThe Emergence of "Big Data" Technology and AnalyticsHabib MradNo ratings yet
- BDA Sem3Document19 pagesBDA Sem3Yachika YadavNo ratings yet
- Big dataaRCHITECTURES FoundationsDocument42 pagesBig dataaRCHITECTURES FoundationsGilbert DwasiNo ratings yet
- Big Data Analytics NotesDocument74 pagesBig Data Analytics Notesmazlankhan1430No ratings yet
- Bda Mod 1Document17 pagesBda Mod 1Ison PereiraNo ratings yet
- Big Data Unit 1 Notes - 240311 - 100703Document15 pagesBig Data Unit 1 Notes - 240311 - 100703vishalsy301No ratings yet
- Data Scraping From Various Data ResourcesDocument6 pagesData Scraping From Various Data Resourcesmrudula nimmalaNo ratings yet
- A Survey - Data Security and Privacy Big DataDocument6 pagesA Survey - Data Security and Privacy Big DataiaetsdiaetsdNo ratings yet
- Big Data Module 1Document19 pagesBig Data Module 1AnanthvasanthaNo ratings yet
- Hand Book: Ahmedabad Institute of TechnologyDocument103 pagesHand Book: Ahmedabad Institute of TechnologyBhavik SangharNo ratings yet
- BigData Terminology Hadoop MapReduce Yarn Spark File FormatsDocument42 pagesBigData Terminology Hadoop MapReduce Yarn Spark File FormatsyassmineelbessiNo ratings yet
- Big DataDocument3 pagesBig DataAnonymous lPvvgiQjRNo ratings yet
- Hadoop Notes Unit2Document24 pagesHadoop Notes Unit2manyamlakshmiprasannaNo ratings yet
- CS8091 BDA Unit 1Document118 pagesCS8091 BDA Unit 1dhurgadeviNo ratings yet
- Ism 6404 CH 7Document47 pagesIsm 6404 CH 7Noemer OrsolinoNo ratings yet
- Ccs 334Document16 pagesCcs 334Amsaveni .amsaveniNo ratings yet
- Project FInal ReportDocument67 pagesProject FInal ReportUnknown UserNo ratings yet
- PC (3rd) Dec2016Document2 pagesPC (3rd) Dec2016pinniNo ratings yet
- PC (3rd) Dec2014Document1 pagePC (3rd) Dec2014pinniNo ratings yet
- Syllabus of Big Data1Document2 pagesSyllabus of Big Data1pinniNo ratings yet
- Qu Izzy Thesis 1Document74 pagesQu Izzy Thesis 1pinniNo ratings yet
- Stoonae: Aes StandadDocument6 pagesStoonae: Aes StandadpinniNo ratings yet
- Quiz Contest A Quiz Application A PROJECDocument53 pagesQuiz Contest A Quiz Application A PROJECpinniNo ratings yet
- Major Project FormatDocument6 pagesMajor Project FormatpinniNo ratings yet
- Major Project FormatDocument6 pagesMajor Project FormatpinniNo ratings yet
- NotesDocument319 pagesNotesSiavash KhademNo ratings yet
- Maths P6Document6 pagesMaths P6Gaspardus MFASHIJWENIMANANo ratings yet
- Deaerator TypesDocument4 pagesDeaerator TypesMuhammad Fakhriy Indallah0% (2)
- A Model of Gas Bubble Growth by Comsol Multiphysics - PaperDocument6 pagesA Model of Gas Bubble Growth by Comsol Multiphysics - Paperivansendacross5221No ratings yet
- Chtext - Rotina Lisp para Mudar o TextoDocument11 pagesChtext - Rotina Lisp para Mudar o TextopaulixNo ratings yet
- Basin Modelling in The Mahakam Delta Based On TheDocument21 pagesBasin Modelling in The Mahakam Delta Based On TheMartyson Yudha Prawira100% (1)
- Ch. 32 - Optical ImagesDocument19 pagesCh. 32 - Optical ImagesAbdallah IslaihNo ratings yet
- BS 1873-2 - 1997Document14 pagesBS 1873-2 - 1997RAKESH ANABNo ratings yet
- Seismic Inversion by Newtonian Machine Learning: Yuqing Chen and Gerard T. SchusterDocument16 pagesSeismic Inversion by Newtonian Machine Learning: Yuqing Chen and Gerard T. SchusterAlNo ratings yet
- P&Id P&ID P&Id P&Id Piping & Instrument Diagram Piping & Instrument Diagram PG G PG GDocument23 pagesP&Id P&ID P&Id P&Id Piping & Instrument Diagram Piping & Instrument Diagram PG G PG GAmirNo ratings yet
- SSL: Smart Street Lamp Based On Fog Computing For Smarter CitiesDocument6 pagesSSL: Smart Street Lamp Based On Fog Computing For Smarter CitiesHariniNo ratings yet
- Se Unit3Document138 pagesSe Unit3kishoreNo ratings yet
- Alternative To READ - TEXT Function Module (No More FM Needed) - SAP BlogsDocument32 pagesAlternative To READ - TEXT Function Module (No More FM Needed) - SAP BlogsDeadMan BlackHeartNo ratings yet
- C Programming FaqDocument432 pagesC Programming FaqharshabalamNo ratings yet
- A Biomechanical Perspective On Bone QualityDocument9 pagesA Biomechanical Perspective On Bone QualityXiao YangNo ratings yet
- Storage Documents Eshop Cheda HR 6500 Ing 06 2012Document1 pageStorage Documents Eshop Cheda HR 6500 Ing 06 2012maxwell onyekachukwuNo ratings yet
- Chapter One HandoutDocument24 pagesChapter One Handouttamenet5405No ratings yet
- Advanced Algorithm Analysis CSC683Document61 pagesAdvanced Algorithm Analysis CSC683Qacim KiyaniNo ratings yet
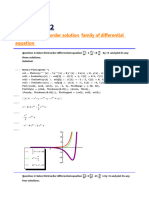
- Practical-2: Plotting of Third Order Solution Family of Differential EquationDocument4 pagesPractical-2: Plotting of Third Order Solution Family of Differential EquationnidhikoshaliaNo ratings yet
- GP0001Document12 pagesGP0001mdasifkhan2013No ratings yet
- COST ACCTNG - Chapters 7 9 ActivitiesDocument27 pagesCOST ACCTNG - Chapters 7 9 ActivitiesAnjelika ViescaNo ratings yet
- Thermal Imaging (Updated) 1Document37 pagesThermal Imaging (Updated) 1conmec.crplNo ratings yet
- IR SecurityKitA2Document50 pagesIR SecurityKitA2Richard WilliamNo ratings yet
- Coordinate Geometry and Calculus. TIME: 3hrs Max. Marks.75Document16 pagesCoordinate Geometry and Calculus. TIME: 3hrs Max. Marks.75Tarigonda GiridharNo ratings yet
- Harmonic Analysis of SVPWM Based Three Phase Inverter Using MATLAB SimulinkDocument6 pagesHarmonic Analysis of SVPWM Based Three Phase Inverter Using MATLAB SimulinkEditor IJTSRDNo ratings yet
- PV Modeling PDFDocument57 pagesPV Modeling PDFgilbertomjcNo ratings yet
- Qianli Thermal Camera User Guide v3Document4 pagesQianli Thermal Camera User Guide v3Abdulrahman AlabdanNo ratings yet

































































































Download as ppt, pdf, or txt
You might also like
- CO2-Reducing Cement Based On Calcium SilicatesDocument9 pagesCO2-Reducing Cement Based On Calcium Silicatesyinglv100% (1)
- Clark LundbergDocument3 pagesClark Lundbergms. bee0% (1)
- Likert Scales: How To (Ab) Use Them Susan JamiesonDocument8 pagesLikert Scales: How To (Ab) Use Them Susan JamiesonFelipe Santana LopesNo ratings yet
- What Is Difference Between Data Warehouse and Big DataDocument8 pagesWhat Is Difference Between Data Warehouse and Big Datakin bhNo ratings yet
- Hitachi White Paper Big Data InfrastructureDocument9 pagesHitachi White Paper Big Data InfrastructureMaurício ZanellaNo ratings yet
- Big Data Hadoop Training 8214944.ppsxDocument52 pagesBig Data Hadoop Training 8214944.ppsxhoukoumatNo ratings yet
- Big Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Document8 pagesBig Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Renuka PandeyNo ratings yet
- BIG DATA 1 UnitDocument17 pagesBIG DATA 1 UnitIshika SinghNo ratings yet
- Big Data (Unit 1)Document37 pagesBig Data (Unit 1)Shekhar KumarNo ratings yet
- Big Data 101 Brief PDFDocument4 pagesBig Data 101 Brief PDFAruna PattamNo ratings yet
- Module 2-4Document16 pagesModule 2-4lamiya kasimNo ratings yet
- Data Warehouse Literature ReviewDocument4 pagesData Warehouse Literature Reviewafmzubsbdcfffg100% (1)
- Big Data Storage: Margaret Rouse Garry KranzDocument6 pagesBig Data Storage: Margaret Rouse Garry KranzLotti LottiNo ratings yet
- Big DataDocument17 pagesBig DataJelinNo ratings yet
- What Is Big Data ?Document6 pagesWhat Is Big Data ?Meet MahidaNo ratings yet
- Unit I-KCS-061Document42 pagesUnit I-KCS-061aggarwalmohit813No ratings yet
- Big Data12Document11 pagesBig Data12Gustavo MercadoNo ratings yet
- Unit-5 DSDocument20 pagesUnit-5 DSrajkumarmtechNo ratings yet
- Big Data AnalyticsDocument21 pagesBig Data AnalyticsAasim SaifiNo ratings yet
- Big Data Analytics 1-5Document63 pagesBig Data Analytics 1-5Amani yar KhanNo ratings yet
- Big DataDocument6 pagesBig DataDivyasriNo ratings yet
- Big Data Analysis Using Hadoop and Mapreduce: Figure 1: World Wide Data Creation IndexDocument11 pagesBig Data Analysis Using Hadoop and Mapreduce: Figure 1: World Wide Data Creation Indexswapnil kaleNo ratings yet
- CSD 1043: Big Data Fundamentals Week1: Big Data Landscape: DefinitionsDocument13 pagesCSD 1043: Big Data Fundamentals Week1: Big Data Landscape: DefinitionsFernando Andrés Hinojosa VillarrealNo ratings yet
- CC Becse Unit 4 PDFDocument32 pagesCC Becse Unit 4 PDFRushikesh YadavNo ratings yet
- Big Data (Unit 1)Document38 pagesBig Data (Unit 1)moubais3143No ratings yet
- BIG DATA & Hadoop TutorialDocument23 pagesBIG DATA & Hadoop Tutorialsaif salahNo ratings yet
- Internet Technologies: By: Nandish Rao ADocument16 pagesInternet Technologies: By: Nandish Rao Amalini.kuppuraj1802No ratings yet
- Big Data: Presented By, Nishaa RDocument24 pagesBig Data: Presented By, Nishaa RNishaaNo ratings yet
- Harnessing Big DataDocument29 pagesHarnessing Big DataDipak ShowNo ratings yet
- Escritura 1Document7 pagesEscritura 1kennethNo ratings yet
- Ethiopin Tecica University Departement of Ict Cours Title: Big DataDocument15 pagesEthiopin Tecica University Departement of Ict Cours Title: Big DatagudissagabissaNo ratings yet
- WINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataDocument20 pagesWINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataSimritha RANo ratings yet
- Big Data With HadoopDocument26 pagesBig Data With Hadoopsonu samgeNo ratings yet
- UNIT-1 Bda KalyanDocument25 pagesUNIT-1 Bda KalyanKalyan KumarNo ratings yet
- Discuss The Characteristics of Big DataDocument2 pagesDiscuss The Characteristics of Big DataRhea EstavilloNo ratings yet
- Data StructuresDocument50 pagesData StructuresKoushik Raaj Radha KrishnanNo ratings yet
- Data Mining 1Document13 pagesData Mining 1Waleed RazaNo ratings yet
- Advanced DataBase AssignmentDocument8 pagesAdvanced DataBase AssignmentIbrahem RamadanNo ratings yet
- Bda - 1 UnitDocument21 pagesBda - 1 UnitASMA UL HUSNANo ratings yet
- Big Data SeminarDocument27 pagesBig Data SeminarAlemayehu Getachew100% (2)
- Big Data1Document9 pagesBig Data1JelinNo ratings yet
- Big Data Analytics (VN) 1Document98 pagesBig Data Analytics (VN) 1Veera NageswaranNo ratings yet
- Hadoop ReportDocument110 pagesHadoop ReportGahlot DivyanshNo ratings yet
- CC Unit 3 Imp QuestionsDocument15 pagesCC Unit 3 Imp QuestionsSahana UrsNo ratings yet
- The Emergence of "Big Data" Technology and AnalyticsDocument6 pagesThe Emergence of "Big Data" Technology and AnalyticsHabib MradNo ratings yet
- BDA Sem3Document19 pagesBDA Sem3Yachika YadavNo ratings yet
- Big dataaRCHITECTURES FoundationsDocument42 pagesBig dataaRCHITECTURES FoundationsGilbert DwasiNo ratings yet
- Big Data Analytics NotesDocument74 pagesBig Data Analytics Notesmazlankhan1430No ratings yet
- Bda Mod 1Document17 pagesBda Mod 1Ison PereiraNo ratings yet
- Big Data Unit 1 Notes - 240311 - 100703Document15 pagesBig Data Unit 1 Notes - 240311 - 100703vishalsy301No ratings yet
- Data Scraping From Various Data ResourcesDocument6 pagesData Scraping From Various Data Resourcesmrudula nimmalaNo ratings yet
- A Survey - Data Security and Privacy Big DataDocument6 pagesA Survey - Data Security and Privacy Big DataiaetsdiaetsdNo ratings yet
- Big Data Module 1Document19 pagesBig Data Module 1AnanthvasanthaNo ratings yet
- Hand Book: Ahmedabad Institute of TechnologyDocument103 pagesHand Book: Ahmedabad Institute of TechnologyBhavik SangharNo ratings yet
- BigData Terminology Hadoop MapReduce Yarn Spark File FormatsDocument42 pagesBigData Terminology Hadoop MapReduce Yarn Spark File FormatsyassmineelbessiNo ratings yet
- Big DataDocument3 pagesBig DataAnonymous lPvvgiQjRNo ratings yet
- Hadoop Notes Unit2Document24 pagesHadoop Notes Unit2manyamlakshmiprasannaNo ratings yet
- CS8091 BDA Unit 1Document118 pagesCS8091 BDA Unit 1dhurgadeviNo ratings yet
- Ism 6404 CH 7Document47 pagesIsm 6404 CH 7Noemer OrsolinoNo ratings yet
- Ccs 334Document16 pagesCcs 334Amsaveni .amsaveniNo ratings yet
- Project FInal ReportDocument67 pagesProject FInal ReportUnknown UserNo ratings yet
- PC (3rd) Dec2016Document2 pagesPC (3rd) Dec2016pinniNo ratings yet
- PC (3rd) Dec2014Document1 pagePC (3rd) Dec2014pinniNo ratings yet
- Syllabus of Big Data1Document2 pagesSyllabus of Big Data1pinniNo ratings yet
- Qu Izzy Thesis 1Document74 pagesQu Izzy Thesis 1pinniNo ratings yet
- Stoonae: Aes StandadDocument6 pagesStoonae: Aes StandadpinniNo ratings yet
- Quiz Contest A Quiz Application A PROJECDocument53 pagesQuiz Contest A Quiz Application A PROJECpinniNo ratings yet
- Major Project FormatDocument6 pagesMajor Project FormatpinniNo ratings yet
- Major Project FormatDocument6 pagesMajor Project FormatpinniNo ratings yet
- NotesDocument319 pagesNotesSiavash KhademNo ratings yet
- Maths P6Document6 pagesMaths P6Gaspardus MFASHIJWENIMANANo ratings yet
- Deaerator TypesDocument4 pagesDeaerator TypesMuhammad Fakhriy Indallah0% (2)
- A Model of Gas Bubble Growth by Comsol Multiphysics - PaperDocument6 pagesA Model of Gas Bubble Growth by Comsol Multiphysics - Paperivansendacross5221No ratings yet
- Chtext - Rotina Lisp para Mudar o TextoDocument11 pagesChtext - Rotina Lisp para Mudar o TextopaulixNo ratings yet
- Basin Modelling in The Mahakam Delta Based On TheDocument21 pagesBasin Modelling in The Mahakam Delta Based On TheMartyson Yudha Prawira100% (1)
- Ch. 32 - Optical ImagesDocument19 pagesCh. 32 - Optical ImagesAbdallah IslaihNo ratings yet
- BS 1873-2 - 1997Document14 pagesBS 1873-2 - 1997RAKESH ANABNo ratings yet
- Seismic Inversion by Newtonian Machine Learning: Yuqing Chen and Gerard T. SchusterDocument16 pagesSeismic Inversion by Newtonian Machine Learning: Yuqing Chen and Gerard T. SchusterAlNo ratings yet
- P&Id P&ID P&Id P&Id Piping & Instrument Diagram Piping & Instrument Diagram PG G PG GDocument23 pagesP&Id P&ID P&Id P&Id Piping & Instrument Diagram Piping & Instrument Diagram PG G PG GAmirNo ratings yet
- SSL: Smart Street Lamp Based On Fog Computing For Smarter CitiesDocument6 pagesSSL: Smart Street Lamp Based On Fog Computing For Smarter CitiesHariniNo ratings yet
- Se Unit3Document138 pagesSe Unit3kishoreNo ratings yet
- Alternative To READ - TEXT Function Module (No More FM Needed) - SAP BlogsDocument32 pagesAlternative To READ - TEXT Function Module (No More FM Needed) - SAP BlogsDeadMan BlackHeartNo ratings yet
- C Programming FaqDocument432 pagesC Programming FaqharshabalamNo ratings yet
- A Biomechanical Perspective On Bone QualityDocument9 pagesA Biomechanical Perspective On Bone QualityXiao YangNo ratings yet
- Storage Documents Eshop Cheda HR 6500 Ing 06 2012Document1 pageStorage Documents Eshop Cheda HR 6500 Ing 06 2012maxwell onyekachukwuNo ratings yet
- Chapter One HandoutDocument24 pagesChapter One Handouttamenet5405No ratings yet
- Advanced Algorithm Analysis CSC683Document61 pagesAdvanced Algorithm Analysis CSC683Qacim KiyaniNo ratings yet
- Practical-2: Plotting of Third Order Solution Family of Differential EquationDocument4 pagesPractical-2: Plotting of Third Order Solution Family of Differential EquationnidhikoshaliaNo ratings yet
- GP0001Document12 pagesGP0001mdasifkhan2013No ratings yet
- COST ACCTNG - Chapters 7 9 ActivitiesDocument27 pagesCOST ACCTNG - Chapters 7 9 ActivitiesAnjelika ViescaNo ratings yet
- Thermal Imaging (Updated) 1Document37 pagesThermal Imaging (Updated) 1conmec.crplNo ratings yet
- IR SecurityKitA2Document50 pagesIR SecurityKitA2Richard WilliamNo ratings yet
- Coordinate Geometry and Calculus. TIME: 3hrs Max. Marks.75Document16 pagesCoordinate Geometry and Calculus. TIME: 3hrs Max. Marks.75Tarigonda GiridharNo ratings yet
- Harmonic Analysis of SVPWM Based Three Phase Inverter Using MATLAB SimulinkDocument6 pagesHarmonic Analysis of SVPWM Based Three Phase Inverter Using MATLAB SimulinkEditor IJTSRDNo ratings yet
- PV Modeling PDFDocument57 pagesPV Modeling PDFgilbertomjcNo ratings yet
- Qianli Thermal Camera User Guide v3Document4 pagesQianli Thermal Camera User Guide v3Abdulrahman AlabdanNo ratings yet