Download as ppt, pdf, or txt
You might also like
- Lec 7Document24 pagesLec 7hussienboss99No ratings yet
- Mat Lab ObservationDocument25 pagesMat Lab Observationabinash ayyappanNo ratings yet
- BEH.420 Matlab TutorialDocument12 pagesBEH.420 Matlab TutorialDeepshikhaSinghNo ratings yet
- Lecture 04Document18 pagesLecture 04demomentoNo ratings yet
- InternetalgoDocument13 pagesInternetalgoAmisha SharmaNo ratings yet
- Laboratory in Automatic Control: Lab 1 Matlab BasicsDocument23 pagesLaboratory in Automatic Control: Lab 1 Matlab BasicsnchubcclNo ratings yet
- Programming Paradigms: cs784 (Prasad) L5Pdm 1Document28 pagesProgramming Paradigms: cs784 (Prasad) L5Pdm 1MunniNo ratings yet
- Lecture-09 - Shortest Path AlgorithmsDocument42 pagesLecture-09 - Shortest Path Algorithms灭霸No ratings yet
- EC330 Applied Algorithms and Data Structures For Engineers Fall 2018 Homework 4Document3 pagesEC330 Applied Algorithms and Data Structures For Engineers Fall 2018 Homework 4DF QWERTNo ratings yet
- 문제해결 공학프로그래밍 Ch7 DnCDocument71 pages문제해결 공학프로그래밍 Ch7 DnC남유찬No ratings yet
- Problem Solving & Problem Design Using CDocument38 pagesProblem Solving & Problem Design Using CWaliullah MazharNo ratings yet
- Introduction To MATLAB: Stefan Güttel October 15, 2020Document12 pagesIntroduction To MATLAB: Stefan Güttel October 15, 2020BorderBRENo ratings yet
- Che310handout2 PDFDocument72 pagesChe310handout2 PDFRidwan MahfuzNo ratings yet
- STTN 225 R SummaryDocument18 pagesSTTN 225 R Summarymaya valentyneNo ratings yet
- Write: Tutorials Student JobsDocument12 pagesWrite: Tutorials Student JobsBHOJWANI HEMANTNo ratings yet
- Final Spring18Document3 pagesFinal Spring18aizazNo ratings yet
- Unit 1: Daa Two Mark Question and Answer 1Document22 pagesUnit 1: Daa Two Mark Question and Answer 1Raja RajanNo ratings yet
- 資料工程 Data Engineering: Pattern Matching 張賢宗Document38 pages資料工程 Data Engineering: Pattern Matching 張賢宗Harish PannalaNo ratings yet
- IT2070 - Data Structures and AlgorithmsDocument5 pagesIT2070 - Data Structures and AlgorithmsTanya KaushiNo ratings yet
- 02 Exact KMP Boyer - MooreDocument100 pages02 Exact KMP Boyer - MooreBig BerthaNo ratings yet
- R Graphics2Document55 pagesR Graphics2mopliqNo ratings yet
- 12 IpDocument14 pages12 IpJígñésh Jáy PrákáshNo ratings yet
- Python String MCQ With Answers & Explanation - LetsfindcourseDocument1 pagePython String MCQ With Answers & Explanation - Letsfindcoursefazilaariff032No ratings yet
- Experimento 3 MATLAB Analisis FrecuenciaDocument12 pagesExperimento 3 MATLAB Analisis FrecuenciaCarolina RuizNo ratings yet
- MIT1 204S10 Lec05Document13 pagesMIT1 204S10 Lec05guddinan makureNo ratings yet
- Lecture-03 - Growth of FunctionsDocument21 pagesLecture-03 - Growth of Functions灭霸No ratings yet
- Experiment No. 01 Experiment Name: Objectives:: 2.platform Independence. 3Document10 pagesExperiment No. 01 Experiment Name: Objectives:: 2.platform Independence. 3Omor FarukNo ratings yet
- Python - Unit 4Document59 pagesPython - Unit 4dagadsai0330No ratings yet
- Lecture 5. Basics Part 4Document39 pagesLecture 5. Basics Part 4shankaranaidoo9214No ratings yet
- Pattern Matching 2Document46 pagesPattern Matching 2adi s. nugrohoNo ratings yet
- IT 340-Programming Language Design Concepts7Document7 pagesIT 340-Programming Language Design Concepts7jathurshanm3No ratings yet
- Python Basic and Advanced-Day 8Document20 pagesPython Basic and Advanced-Day 8Ashok Kumar100% (1)
- Python Programming Unit Ii: Prof - Ajay Pashankar Assistant Professor Department of Cs & It K.M.Agrawal College KalyanDocument58 pagesPython Programming Unit Ii: Prof - Ajay Pashankar Assistant Professor Department of Cs & It K.M.Agrawal College KalyanPrathameshNo ratings yet
- Scientific Python (By Stanford)Document58 pagesScientific Python (By Stanford)atom tuxNo ratings yet
- Type T Array (1..10) of Integer S T A: T B: T C: S D: Array (1..10) of IntegerDocument3 pagesType T Array (1..10) of Integer S T A: T B: T C: S D: Array (1..10) of IntegerRishab JainNo ratings yet
- Advanced Artificial Intelligence (Datalog, Part II) : Marco Maratea DIBRIS, University of Genoa, Italy A.Y. 2020/21Document28 pagesAdvanced Artificial Intelligence (Datalog, Part II) : Marco Maratea DIBRIS, University of Genoa, Italy A.Y. 2020/21mulettoNo ratings yet
- Pyplot TutorialDocument9 pagesPyplot TutorialJorge SaldarriagaNo ratings yet
- Introduction To Optimization: CBMM Summer School Aug 12, 2018Document64 pagesIntroduction To Optimization: CBMM Summer School Aug 12, 2018Carlos Alonso Aznarán LaosNo ratings yet
- TAG3P: Preliminary Comparison: 5.1 Test ProblemsDocument16 pagesTAG3P: Preliminary Comparison: 5.1 Test ProblemsNam LeNo ratings yet
- Csc349a f2023 Asn1Document5 pagesCsc349a f2023 Asn1mileskticknerNo ratings yet
- Control System Lab Manual (Kec-652)Document29 pagesControl System Lab Manual (Kec-652)VIKASH YADAVNo ratings yet
- Module 05 PDFDocument20 pagesModule 05 PDFHari KandelNo ratings yet
- B CTS Test 8Document13 pagesB CTS Test 8sarahloner030No ratings yet
- Cs3353 Fds Unit 5 Notes EduenggDocument41 pagesCs3353 Fds Unit 5 Notes EduenggGanesh KumarNo ratings yet
- Algorithm Lec8Document62 pagesAlgorithm Lec8Habiba HegazyNo ratings yet
- String MatchingDocument35 pagesString Matchingduration123No ratings yet
- Chapter 11 - Templates: 2003 Prentice Hall, Inc. All Rights ReservedDocument26 pagesChapter 11 - Templates: 2003 Prentice Hall, Inc. All Rights ReservedSukhwinder Singh GillNo ratings yet
- P04700 MATLAB Handout - 1 2015Document32 pagesP04700 MATLAB Handout - 1 2015Fabrizio TreccarichiNo ratings yet
- DAA (5th) Dec2017Document2 pagesDAA (5th) Dec2017Raavi SaamarNo ratings yet
- Programming Exercise 2: Logistic Regression: Machine LearningDocument13 pagesProgramming Exercise 2: Logistic Regression: Machine LearningzonadosNo ratings yet
- ML Andrew NGDocument13 pagesML Andrew NGGuru PrasadNo ratings yet
- Functions Lectr01Document25 pagesFunctions Lectr01huzi malixNo ratings yet
- 1 MATLAB IntroDocument21 pages1 MATLAB IntroMd. Moshiur Rahman MugdhoNo ratings yet
- Strings in PythonDocument27 pagesStrings in PythonSreedhar YellamNo ratings yet
- End Sem Model SolutionDocument13 pagesEnd Sem Model SolutionKarthikeyaNo ratings yet
- Matplotlib PlottingDocument1 pageMatplotlib Plottingahmed salemNo ratings yet
- TP1 MFDocument4 pagesTP1 MFMakieseNo ratings yet
- Function Package SlidesDocument45 pagesFunction Package SlidesAnirban SadhuNo ratings yet
- 2020 Day6 Functions Recursion PythonDocument26 pages2020 Day6 Functions Recursion PythonTridib Nanda RoyNo ratings yet
- Lecture 12 HashingDocument22 pagesLecture 12 Hashing灭霸No ratings yet
- Lecture-15 Approximation AlgorithmsDocument32 pagesLecture-15 Approximation Algorithms灭霸No ratings yet
- Lecture 13 14 - NP CompletenessDocument27 pagesLecture 13 14 - NP Completeness灭霸No ratings yet
- Lecture-10 - Information Coding TechniquesDocument50 pagesLecture-10 - Information Coding Techniques灭霸No ratings yet
- Lecture-07 - Advanced Data Structures - 1Document36 pagesLecture-07 - Advanced Data Structures - 1灭霸No ratings yet
- Lecture-09 - Shortest Path AlgorithmsDocument42 pagesLecture-09 - Shortest Path Algorithms灭霸No ratings yet
- Lecture-08 - Advanced Data Structures - 2Document56 pagesLecture-08 - Advanced Data Structures - 2灭霸No ratings yet
- Lecture-06 Graph TheoryDocument44 pagesLecture-06 Graph Theory灭霸No ratings yet
- Lecture-03 - Growth of FunctionsDocument21 pagesLecture-03 - Growth of Functions灭霸No ratings yet
- Lecture-04 05 - Sorting Techniques AnalysisDocument10 pagesLecture-04 05 - Sorting Techniques Analysis灭霸No ratings yet
- Lecture-01 Introduction OverviewDocument17 pagesLecture-01 Introduction Overview灭霸No ratings yet
- B.Tech. 3rd Yr CSE (AIML) 2022 23Document33 pagesB.Tech. 3rd Yr CSE (AIML) 2022 23Knowledge FactoryNo ratings yet
- Rust by PracticeDocument253 pagesRust by Practiceshubhamx7697No ratings yet
- Edge-Maximal Triangulated Subgraphs and Heuristics For The Maximum Clique ProblemDocument12 pagesEdge-Maximal Triangulated Subgraphs and Heuristics For The Maximum Clique Problem赵夏淼No ratings yet
- OS-344 Assignment-2BDocument5 pagesOS-344 Assignment-2BEkeshwar GowlaNo ratings yet
- Os Lab Pratices FinializedDocument2 pagesOs Lab Pratices Finializedswathi bommisettyNo ratings yet
- Itec513 Fall20172018 EstimationDocument81 pagesItec513 Fall20172018 EstimationzinssafNo ratings yet
- FDocument15 pagesFpkh29No ratings yet
- TE Computer 2019 Course Revised Draft 7june2021Document104 pagesTE Computer 2019 Course Revised Draft 7june2021sun foruNo ratings yet
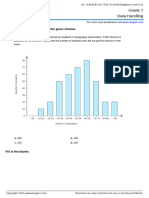
- Grade7 850183 22 7701.qDocument5 pagesGrade7 850183 22 7701.qV.s VijayNo ratings yet
- High-Level Synthesis: Hao Zheng Comp Sci & Eng University of South FloridaDocument26 pagesHigh-Level Synthesis: Hao Zheng Comp Sci & Eng University of South Floridamdumar umarNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing: Pcolella@berkeley - Edu Pcolella@lbl - GovDocument39 pagesCS 294-73 Software Engineering For Scientific Computing: Pcolella@berkeley - Edu Pcolella@lbl - GovEdmund ZinNo ratings yet
- True University Management SystemDocument12 pagesTrue University Management SystemSa'ad AbdiNo ratings yet
- Functiom Modules TheoryDocument2 pagesFunctiom Modules TheorykhaleelinnovatorNo ratings yet
- Computer Science Notes For Class 5Th - Lesson # 2 Memory of The ComputerDocument4 pagesComputer Science Notes For Class 5Th - Lesson # 2 Memory of The Computerkemden42No ratings yet
- Algorithms and Correctness Past PaperDocument7 pagesAlgorithms and Correctness Past PaperBilly GeneNo ratings yet
- Lecture 2Document25 pagesLecture 2AbhishekNo ratings yet
- WBJP MicroDocument12 pagesWBJP MicroThe DhvanitNo ratings yet
- D1-Practice-Exercise-12 Binary Search TreeDocument14 pagesD1-Practice-Exercise-12 Binary Search TreeMihir OberoiNo ratings yet
- Duplichecker Plagiarism ReportDocument3 pagesDuplichecker Plagiarism Reportmmorad aamraouyNo ratings yet
- Lecture 3 & 4 Editors and Its TypesDocument24 pagesLecture 3 & 4 Editors and Its Typesrsrinet.876No ratings yet
- Python Chapter 1Document45 pagesPython Chapter 1praveenNo ratings yet
- On Thi TNVDKDocument24 pagesOn Thi TNVDKPhan Ngọc Minh TriếtNo ratings yet
- Unit-II Action Script IDocument89 pagesUnit-II Action Script IDHANASEKAR GNo ratings yet
- Code Resource PackDocument38 pagesCode Resource PackSurnainaNo ratings yet
- Effective GoDocument38 pagesEffective Gomasi22No ratings yet
- (Heni Vyas)Document5 pages(Heni Vyas)41- Vaibhav VyasNo ratings yet
- Exercise ProbabilityDocument5 pagesExercise ProbabilityAhmad MalakNo ratings yet
- 8086 ArchitectureDocument40 pages8086 ArchitectureSimranjotSinghNo ratings yet
- Computer Science Unit-4 Sem 1Document14 pagesComputer Science Unit-4 Sem 1aditya67857No ratings yet
- All Ass AnswersDocument91 pagesAll Ass Answerspragya27apoorvaNo ratings yet