Download as pptx, pdf, or txt
You might also like
- Smart-L MM/F: Long Range Multi Mission RadarDocument2 pagesSmart-L MM/F: Long Range Multi Mission RadarCarakaNo ratings yet
- Konerulakshmaiah Education Foundation: A Project Based Lab Report On Implementaton of Linked List ApplicationsDocument19 pagesKonerulakshmaiah Education Foundation: A Project Based Lab Report On Implementaton of Linked List Applicationsbhanu sunny75% (4)
- Crop Recommender SystemDocument23 pagesCrop Recommender SystemPavitra DeviNo ratings yet
- Crop Yield ReportDocument30 pagesCrop Yield Reportkishore50% (2)
- Palas Blackbook OriginalDocument43 pagesPalas Blackbook Originalsonali pal100% (3)
- Envi-Met Introduction 2019Document61 pagesEnvi-Met Introduction 2019Thắm PhạmNo ratings yet
- Lesson 1: Comparing Security Roles and Security ControlsDocument17 pagesLesson 1: Comparing Security Roles and Security ControlsPhan Sư Ýnh100% (2)
- Lab Proj.05 Hex EditorDocument13 pagesLab Proj.05 Hex EditorQuốc Việt NguyễnNo ratings yet
- (Case Study) Is Social Business Working OutDocument2 pages(Case Study) Is Social Business Working OutDwi Diana II100% (1)
- Soil Data AnalysisDocument6 pagesSoil Data Analysis20C134-SRIKRISHNA MNo ratings yet
- Crop Yield Prediction Using Random Forest AlgorithmDocument11 pagesCrop Yield Prediction Using Random Forest AlgorithmVj KumarNo ratings yet
- By Narasimhalu R PES1PG21CA154Document45 pagesBy Narasimhalu R PES1PG21CA154aishwarya kalyanNo ratings yet
- Soil Classification - Survey Paper1Document6 pagesSoil Classification - Survey Paper1anushraypingale8No ratings yet
- Banasthali Vidyapeeth: Seminar Presentation ON "Crop Prediction"Document26 pagesBanasthali Vidyapeeth: Seminar Presentation ON "Crop Prediction"Selva rajNo ratings yet
- Alva'S Institute of Engineering and TechnologyDocument28 pagesAlva'S Institute of Engineering and TechnologyTejas XdNo ratings yet
- Sat - 40.Pdf - Agricultural Product Price and Crop Cultivation Prediction Based On SMLTDocument11 pagesSat - 40.Pdf - Agricultural Product Price and Crop Cultivation Prediction Based On SMLTVj KumarNo ratings yet
- Ijresm V5 I6 32Document3 pagesIjresm V5 I6 32Jatin KumarNo ratings yet
- Reference 1Document6 pagesReference 1Shreya GaikwadNo ratings yet
- Report 1Document26 pagesReport 1SARATH CHANDRANo ratings yet
- DBMS ReportDocument30 pagesDBMS Reportpp0031No ratings yet
- Report Seminar TushDocument30 pagesReport Seminar Tushrd xeroxNo ratings yet
- Recommendation of Crop, Fertilizers and Crop Disease Detection SystemDocument6 pagesRecommendation of Crop, Fertilizers and Crop Disease Detection SystemIJRASETPublicationsNo ratings yet
- Crop PredictionDocument21 pagesCrop Predictionaishwarya kalyanNo ratings yet
- Powdery Mildew Prediction in Sandalwood TreesDocument11 pagesPowdery Mildew Prediction in Sandalwood TreesdataprodcsNo ratings yet
- TailwatersystemsDocument26 pagesTailwatersystemsapi-358404608No ratings yet
- Sat - 80.Pdf - Crop Yield Prediction Based On Indian Agriculture Using Stacking AlgorithmDocument11 pagesSat - 80.Pdf - Crop Yield Prediction Based On Indian Agriculture Using Stacking AlgorithmVj KumarNo ratings yet
- Paper 4Document6 pagesPaper 4bamrithapaiNo ratings yet
- Agriculture Production Optimization Engine Using Data ScienceDocument26 pagesAgriculture Production Optimization Engine Using Data ScienceSaurabhNo ratings yet
- Review Paper On Crop Yield Recommendation SystemDocument4 pagesReview Paper On Crop Yield Recommendation SystemIJRASETPublicationsNo ratings yet
- Chapter 4 Characterization of Crop Health and StressDocument42 pagesChapter 4 Characterization of Crop Health and StressAbdulbasit SebsibNo ratings yet
- Computer Science Investigatory ProjectDocument16 pagesComputer Science Investigatory Projectdevlopmentoverhere001No ratings yet
- Review - 1Document37 pagesReview - 1Mubarak BegumNo ratings yet
- Rainfall PredictionDocument33 pagesRainfall PredictionNaasif M100% (1)
- Agricultural Data Analysis Using Machine LearningpdfDocument5 pagesAgricultural Data Analysis Using Machine LearningpdfdeviNo ratings yet
- Crop Disease PredictionDocument14 pagesCrop Disease PredictionPooja GNo ratings yet
- Applying Data Mining Techniques On Soil Fertility PredictionDocument5 pagesApplying Data Mining Techniques On Soil Fertility PredictionATSNo ratings yet
- Pen Doodle Minor Project SynopsisDocument7 pagesPen Doodle Minor Project Synopsisraghavsomani20192No ratings yet
- Harvestify - Crop Disease Detection and Fertilizer Suggestion Using CNNDocument11 pagesHarvestify - Crop Disease Detection and Fertilizer Suggestion Using CNNIJRASETPublicationsNo ratings yet
- Project Review IIDocument47 pagesProject Review IISagar DeshpandeNo ratings yet
- Soil Analysis For Fertilizer and Crop Prediction Using Optical Sensors and Machine LearningDocument5 pagesSoil Analysis For Fertilizer and Crop Prediction Using Optical Sensors and Machine Learning1DT18EC106 Y SAI MEGHANANo ratings yet
- Seminar FInal Report (ANN)Document42 pagesSeminar FInal Report (ANN)Anirudh Adithya B SNo ratings yet
- Rajeev Insttitute of Technology: Dept. of Electronics & Communication EngineeringDocument18 pagesRajeev Insttitute of Technology: Dept. of Electronics & Communication EngineeringSharadhiNo ratings yet
- Technology Was Developed For The Betterment of Our Lives in The World. Then Why Don't We Use It For The Betterment of This World?Document26 pagesTechnology Was Developed For The Betterment of Our Lives in The World. Then Why Don't We Use It For The Betterment of This World?SufyAn SufiNo ratings yet
- IJERT Classification of Soil and Crop SuDocument3 pagesIJERT Classification of Soil and Crop Suabdelhak AouadiNo ratings yet
- Project SynopsisDocument5 pagesProject SynopsisPuttarajNo ratings yet
- Design of Experiments Doe For The Beginner 2021 en B 00242 1 DataDocument43 pagesDesign of Experiments Doe For The Beginner 2021 en B 00242 1 Datashalom.chen0602No ratings yet
- RainfallDocument62 pagesRainfallKanasani RenukaNo ratings yet
- Shashi Organized Final OrganizedDocument65 pagesShashi Organized Final OrganizedShashi KhaNo ratings yet
- PROJECT123Document71 pagesPROJECT123simple sheikNo ratings yet
- Crop Prediction REPORTDocument10 pagesCrop Prediction REPORTSuraj JadhavNo ratings yet
- Computer Science Investigatory ProjectDocument24 pagesComputer Science Investigatory ProjectBenaiah J.K100% (1)
- Crop Yield Prediction Using Machine Learning Techniques: AbstractDocument3 pagesCrop Yield Prediction Using Machine Learning Techniques: Abstractdevils devilNo ratings yet
- Crop Recommendation System Using MLDocument11 pagesCrop Recommendation System Using MLeshithagunasekaranNo ratings yet
- Integrating Machine Learning Tool To Improve DSS Design: R. G. Joshi and H. S. FadewarDocument8 pagesIntegrating Machine Learning Tool To Improve DSS Design: R. G. Joshi and H. S. FadewarsushilkumarNo ratings yet
- Rajeev Insttitute of Technology: Dept. of Electronics & Communication EngineeringDocument19 pagesRajeev Insttitute of Technology: Dept. of Electronics & Communication EngineeringSharadhiNo ratings yet
- Optimization of Citric Acid Production Using AnnDocument27 pagesOptimization of Citric Acid Production Using AnnHana HamidNo ratings yet
- Air TechDocument70 pagesAir Techkalavatinid101No ratings yet
- Plant Disease Final ReportDocument35 pagesPlant Disease Final ReportShailesh SolankeNo ratings yet
- Soil Classification and Crop Suggestion Using Machine Learning TechniquesDocument5 pagesSoil Classification and Crop Suggestion Using Machine Learning TechniquesIJRASETPublicationsNo ratings yet
- Rainfall Prediction With Agricultural Soil Analysis Using Machine LearningDocument11 pagesRainfall Prediction With Agricultural Soil Analysis Using Machine LearningdataprodcsNo ratings yet
- The Simulation of Mineral Processing Machinery, W.J. WhitenDocument3 pagesThe Simulation of Mineral Processing Machinery, W.J. WhitenTsakalakis G. KonstantinosNo ratings yet
- Bharti 2023 BP 6853CDocument17 pagesBharti 2023 BP 6853CmonaranjansharmaNo ratings yet
- RDSML Project ReportDocument66 pagesRDSML Project Reportsandhiya pNo ratings yet
- A Data-Driven Approach To Soil Moisture Collection and Prediction Hong2016Document6 pagesA Data-Driven Approach To Soil Moisture Collection and Prediction Hong2016Hanamant SaleNo ratings yet
- Final Breast CancerDocument23 pagesFinal Breast CancerPrashanth Kumar100% (1)
- Project PPT Review (Batch 1)Document28 pagesProject PPT Review (Batch 1)Prashanth KumarNo ratings yet
- YoloDocument30 pagesYoloPrashanth KumarNo ratings yet
- SFMSDocument30 pagesSFMSPrashanth KumarNo ratings yet
- Batch 6Document28 pagesBatch 6Prashanth KumarNo ratings yet
- Product Information Mflow Extrusion PlastometerDocument7 pagesProduct Information Mflow Extrusion PlastometerDonNo ratings yet
- Id - Vend Integer: VendedorDocument2 pagesId - Vend Integer: VendedorCERONo ratings yet
- User Manual Bisonte Tamping RammerDocument24 pagesUser Manual Bisonte Tamping RammerDaniel PimsaNo ratings yet
- Grundfosliterature 3153315Document58 pagesGrundfosliterature 3153315Javier GarciaNo ratings yet
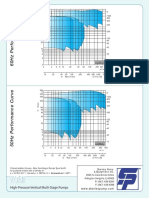
- Edur Vbu Series Performance CurvesDocument1 pageEdur Vbu Series Performance CurvesMohammad HosseinNo ratings yet
- Wa0016.Document4 pagesWa0016.otg92165No ratings yet
- Type VR Electrically Operated Ground and Test DeviceDocument29 pagesType VR Electrically Operated Ground and Test DeviceCarlos CamayoNo ratings yet
- EX2600 7 - Digital Only - 20 10Document19 pagesEX2600 7 - Digital Only - 20 10Huandson alves de meloNo ratings yet
- Reyax RYWDB00 - ENDocument10 pagesReyax RYWDB00 - ENAMNo ratings yet
- Separadores de BridaDocument6 pagesSeparadores de Bridajavier alvarezNo ratings yet
- 13-CongestioninDataNetworks REALDocument36 pages13-CongestioninDataNetworks REALmemo1023No ratings yet
- A First Course in Computational PhysicsDocument435 pagesA First Course in Computational PhysicsPedro Marques100% (7)
- Exercise 1 (Openmp-I)Document10 pagesExercise 1 (Openmp-I)Dhruv SakhujaNo ratings yet
- Edexcel IAL Pure Mathematics P4 June 2022 Wma14-01-Que-20220602Document32 pagesEdexcel IAL Pure Mathematics P4 June 2022 Wma14-01-Que-20220602Nikolas MarselliNo ratings yet
- Mapping BeyondTrust Capabilities To KSA's NCA ECCDocument9 pagesMapping BeyondTrust Capabilities To KSA's NCA ECCAla' Esam ZayadeenNo ratings yet
- Inventory of Ict FacilityDocument3 pagesInventory of Ict FacilityEiddik ErepmasNo ratings yet
- Marking Dt0 SMD TransistorDocument8 pagesMarking Dt0 SMD TransistorWee Chuan PoonNo ratings yet
- Deped Atm PresentationDocument16 pagesDeped Atm PresentationRey PingolNo ratings yet
- TDS Meyco Sa 167 PDFDocument3 pagesTDS Meyco Sa 167 PDFYasin AykanatNo ratings yet
- FREERhymetheRoom 1Document15 pagesFREERhymetheRoom 1Citlali Hau DzibNo ratings yet
- Ligaduras Griegas - WikipediaDocument10 pagesLigaduras Griegas - WikipediaCarlos Arturo MedinaNo ratings yet
- Calculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschDocument10 pagesCalculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschlapuNo ratings yet
- Part I: Introduction and Early Phases of Marketing ResearchDocument23 pagesPart I: Introduction and Early Phases of Marketing ResearchKhoa Nguyễn NhậtNo ratings yet
- Course Outline MTH-375Document5 pagesCourse Outline MTH-375Tal HaNo ratings yet
- Introduction To Digital Electronics: Microelectronic Circuit DesignDocument64 pagesIntroduction To Digital Electronics: Microelectronic Circuit DesignramibotrosNo ratings yet