
Rokach GomaxSlides
Rokach GomaxSlides
You might also like
- Wattpad: Artificial Intelligence & MarketingDocument3 pagesWattpad: Artificial Intelligence & MarketingsrishNo ratings yet
- Mitsubishi IC Pneumatic Forklift PDFDocument5 pagesMitsubishi IC Pneumatic Forklift PDFfdpc1987No ratings yet
- Music Similarity and RetrievalDocument313 pagesMusic Similarity and Retrievalieysimurra100% (1)
- P1903009-0ga-Ar-3801-Hygiene Master Ground Floor Plan - Overall PDFDocument1 pageP1903009-0ga-Ar-3801-Hygiene Master Ground Floor Plan - Overall PDFwrightwomanNo ratings yet
- Optimisation of Drilling Process: Rajahmundry Asset MDFF Training Batch - IV 31.07.2021Document11 pagesOptimisation of Drilling Process: Rajahmundry Asset MDFF Training Batch - IV 31.07.2021HrishabhJainNo ratings yet
- Presentation Market OverviewWorld Robotics 29-9-2016Document18 pagesPresentation Market OverviewWorld Robotics 29-9-2016Manuel CáceresNo ratings yet
- Presentation Market Overviewworld Robotics 29 9 2016 PDFDocument18 pagesPresentation Market Overviewworld Robotics 29 9 2016 PDFManuel CáceresNo ratings yet
- Floor Plan ViewsDocument2 pagesFloor Plan ViewsDorobantu CatalinNo ratings yet
- Experiences T Buzovschi MoldovaDocument29 pagesExperiences T Buzovschi MoldovakedayiNo ratings yet
- Guest House Review 02Document5 pagesGuest House Review 02Sunday JohnNo ratings yet
- R1 Cheruthony Truss 1 - 4Document1 pageR1 Cheruthony Truss 1 - 4Anujith K BabuNo ratings yet
- Operating Parameters Bit Load For Geotechnical Core Bits TD110 R1Document4 pagesOperating Parameters Bit Load For Geotechnical Core Bits TD110 R1Milko HarizanovNo ratings yet
- 2 - VL 17feb2023Document27 pages2 - VL 17feb2023Sergejs JaunzemsNo ratings yet
- Bouteiller 1Document27 pagesBouteiller 1Yaseen AlAjmi CompanyNo ratings yet
- Mezzaninie FloorDocument1 pageMezzaninie FloorElancheliyanNo ratings yet
- Brief Achievements UAFDocument5 pagesBrief Achievements UAFWaqar Akbar KhanNo ratings yet
- Analytics RoadmapDocument30 pagesAnalytics RoadmapmohmalNo ratings yet
- Floor Plan Views2Document60 pagesFloor Plan Views2Sharlene LynnetteNo ratings yet
- BT Plan - FY'24 - Final RahulDocument12 pagesBT Plan - FY'24 - Final RahulDurgaprasad ShettyNo ratings yet
- Appendix J - Manpower HistogramDocument1 pageAppendix J - Manpower HistogramAchu UnnikrishnanNo ratings yet
- Cia 3 - MobDocument5 pagesCia 3 - MobPADMANAP E 2127307No ratings yet
- Mezzanine FloorDocument1 pageMezzanine FloorpreconNo ratings yet
- Exide PresentationDocument17 pagesExide Presentationwasifur1230% (2)
- Catalogue LED XK-12.2019 - 4 PDFDocument100 pagesCatalogue LED XK-12.2019 - 4 PDFBinh VietNo ratings yet
- Keyword Research and Competitors Analysis of Clickbank University ProductDocument7 pagesKeyword Research and Competitors Analysis of Clickbank University ProductMohammed SultanNo ratings yet
- Electronet Equipments PVT LTD - Corporate PresentationDocument41 pagesElectronet Equipments PVT LTD - Corporate PresentationElectronet EquipmentsNo ratings yet
- Trens LathesDocument8 pagesTrens LathesGunay ChelikNo ratings yet
- Knowbigdata-Market PotentialDocument16 pagesKnowbigdata-Market Potentialkilladi123No ratings yet
- Liebherr LTM 1500-8.1: DimensionsDocument22 pagesLiebherr LTM 1500-8.1: DimensionsMohammed HafizNo ratings yet
- Prima Presentation LaserDocument28 pagesPrima Presentation Laser92piovaNo ratings yet
- Statistik Transportasi Laut 2019Document2 pagesStatistik Transportasi Laut 2019Bagus HuriNo ratings yet
- Economic Implications of Foreign Portfolio InvestmentsDocument18 pagesEconomic Implications of Foreign Portfolio Investmentsdharmesh_k91No ratings yet
- VSMAbrasives TechManualDocument12 pagesVSMAbrasives TechManualElep Tran LeNo ratings yet
- CBRI Annual Report 2017 2018 1 PDFDocument297 pagesCBRI Annual Report 2017 2018 1 PDFKshitij JainNo ratings yet
- Drawing1.Dwgغغغ ModelDocument1 pageDrawing1.Dwgغغغ Modelkano hibaNo ratings yet
- Cover Page Design For Digital DisplayDocument34 pagesCover Page Design For Digital DisplayJawms DalaNo ratings yet
- Construction of Baba Sarsai Nath Government Medical College, Sirsa, HaryanaDocument1 pageConstruction of Baba Sarsai Nath Government Medical College, Sirsa, Haryanaonlineielts200No ratings yet
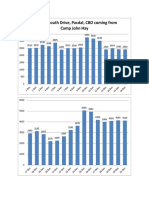
- Going To South Drive, Pacdal, CBD Coming From Camp John HayDocument6 pagesGoing To South Drive, Pacdal, CBD Coming From Camp John HayRJay JacabanNo ratings yet
- Monthly Departmental Meeting For The Month of DECEMBER - 2020Document14 pagesMonthly Departmental Meeting For The Month of DECEMBER - 2020atiqNo ratings yet
- Architect P. Seeburun: Hal Serenity LTD Ground Floor Plan 29.11.2023 A-04Document1 pageArchitect P. Seeburun: Hal Serenity LTD Ground Floor Plan 29.11.2023 A-04Kem RaiNo ratings yet
- Become A Member: Today!Document2 pagesBecome A Member: Today!nassagNo ratings yet
- ???????? ??? ??? ????????? ??? ???? ?????????? !Document142 pages???????? ??? ??? ????????? ??? ???? ?????????? !sravanireddy.kotaNo ratings yet
- Preview Photograph QB GATE 2022 Recovered PDFDocument62 pagesPreview Photograph QB GATE 2022 Recovered PDFPronceNo ratings yet
- Notes: Ground Floor PlanDocument1 pageNotes: Ground Floor PlankingsleyclementakpanNo ratings yet
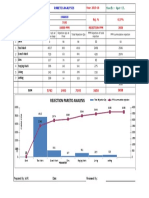
- Rejection Pareto Analysis: Dent Tool Mark Screch Mark Dim. Forging Mark Lining SettingDocument1 pageRejection Pareto Analysis: Dent Tool Mark Screch Mark Dim. Forging Mark Lining SettingMonik kotadiaNo ratings yet
- UTE523Document1 pageUTE523Proc. RembangNo ratings yet
- R2 Apex - Presentaion 22Document30 pagesR2 Apex - Presentaion 22awards.apexindiafoundationNo ratings yet
- Weekly Target & Mapping Jalur Supporting Ladder 2Document2 pagesWeekly Target & Mapping Jalur Supporting Ladder 2Edo renaldiNo ratings yet
- A101 - Ground Floor PlanDocument1 pageA101 - Ground Floor PlanDee-ar Inducil TrinidadNo ratings yet
- Copy of 02. Formulas_v1.0Document12 pagesCopy of 02. Formulas_v1.0mahalakshmi.kokkirimetti1994No ratings yet
- Metric Bolts - Minimum Ultimate Tensile & Proof LoadsDocument4 pagesMetric Bolts - Minimum Ultimate Tensile & Proof LoadsBenjamin IndrawanNo ratings yet
- Ambe Bhawani Layout CBSG-60Document1 pageAmbe Bhawani Layout CBSG-60arshad aliNo ratings yet
- I-A1-0150-Ground Floor General LayoutDocument1 pageI-A1-0150-Ground Floor General Layoutlinga2014No ratings yet
- Kpi T5Document1 pageKpi T5usmansaleem1501No ratings yet
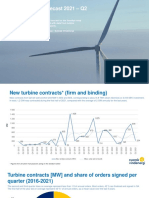
- Statistics and Forecast 2021 - Q2Document15 pagesStatistics and Forecast 2021 - Q2Yassine YassineNo ratings yet
- About Nera Networks - May2006 - WebDocument17 pagesAbout Nera Networks - May2006 - WebMarco BarontiNo ratings yet
- Tour de Future ... of Čsob SKDocument18 pagesTour de Future ... of Čsob SKJakub NovotaNo ratings yet
- Revised Portacabin 003Document1 pageRevised Portacabin 003wangxiaofei926No ratings yet
- Site PlantDocument1 pageSite PlantMuhamadTaufikHidayatNo ratings yet
- Handbook-CivilAviationStatistics 2014-15Document28 pagesHandbook-CivilAviationStatistics 2014-15ashwinkumarsubramaniamNo ratings yet
- Tie Beam and Floor DetailDocument1 pageTie Beam and Floor DetailSuhail AhamedNo ratings yet
- Agile and Six SigmaDocument1 pageAgile and Six SigmapraveenNo ratings yet
- Trident Embassy Reso Price List-6Document2 pagesTrident Embassy Reso Price List-6praveenNo ratings yet
- Resume - Roshan Kumar SharmaDocument1 pageResume - Roshan Kumar SharmapraveenNo ratings yet
- Resume Aakash NagpalDocument1 pageResume Aakash NagpalpraveenNo ratings yet
- Patan Multiple Campus: Tribhuvan UniversityDocument61 pagesPatan Multiple Campus: Tribhuvan UniversitysumanNo ratings yet
- HuKorenVolinsky ICDM08Document10 pagesHuKorenVolinsky ICDM08aaa awwNo ratings yet
- Deep Learning Based Recommender System: A Survey and New PerspectivesDocument35 pagesDeep Learning Based Recommender System: A Survey and New PerspectivesSarı LacivertNo ratings yet
- AI Recommendation SystemDocument20 pagesAI Recommendation SystemChitra ParsailaNo ratings yet
- Scalable RecommendationDocument12 pagesScalable Recommendationnavneet prabhakarNo ratings yet
- Music Recommendation SystemDocument24 pagesMusic Recommendation SystemChinmai JosephNo ratings yet
- PR3215 - Movie - Recommendation - System-Report - PAVAN KUMAR P BDocument30 pagesPR3215 - Movie - Recommendation - System-Report - PAVAN KUMAR P BTushar JainNo ratings yet
- RecSys PyData2016Document32 pagesRecSys PyData2016Chong Hoo ChuahNo ratings yet
- Collaborative Filtering and Content-Based Recommendation of Documents and ProductsDocument9 pagesCollaborative Filtering and Content-Based Recommendation of Documents and ProductsUMA MNo ratings yet
- Transformation of Marketing at The Ohio Art Company (A) and (B) (Abridged)Document5 pagesTransformation of Marketing at The Ohio Art Company (A) and (B) (Abridged)Amit Anand KumarNo ratings yet
- MLCourse SlidesDocument356 pagesMLCourse SlidesSahas InnovapathNo ratings yet
- ResumeDocument2 pagesResumeSai Krishna KethanNo ratings yet
- ML Basics 02 (Statistics)Document438 pagesML Basics 02 (Statistics)Rishabh chaudhary100% (7)
- Movie Recommendation System PresentationDocument15 pagesMovie Recommendation System PresentationabhayNo ratings yet
- Report On Restaurant RecommendationDocument61 pagesReport On Restaurant RecommendationDeepikaNo ratings yet
- Unit-5 MahoutDocument26 pagesUnit-5 Mahoutsixit377870% (1)
- Automated Online Course Recommendation System Using Collaborative FilteringDocument10 pagesAutomated Online Course Recommendation System Using Collaborative FilteringIJRASETPublicationsNo ratings yet
- BFSMpR:A BFS Graph Based Recommendation System Using Map ReduceDocument5 pagesBFSMpR:A BFS Graph Based Recommendation System Using Map ReduceEditor IJRITCCNo ratings yet
- Movie Recommender System Using K-Means Clustering AND K-Nearest NeighborDocument6 pagesMovie Recommender System Using K-Means Clustering AND K-Nearest NeighborArmin ShahabNo ratings yet
- A Survey On Personalized Recommendation TechniquesDocument11 pagesA Survey On Personalized Recommendation TechniquesEditor IJRITCCNo ratings yet
- Information Sciences: Seok Kee Lee, Yoon Ho Cho, Soung Hie KimDocument14 pagesInformation Sciences: Seok Kee Lee, Yoon Ho Cho, Soung Hie KimAdeyekun Lateef Adekunle BestluckNo ratings yet
- Apache Mahout Essentials - Sample ChapterDocument25 pagesApache Mahout Essentials - Sample ChapterPackt PublishingNo ratings yet
- CS F469 Information Retrieval - HandoutDocument3 pagesCS F469 Information Retrieval - HandoutOPM RockyNo ratings yet
- Recommendations Worth A Million: An Introduction To ClusteringDocument42 pagesRecommendations Worth A Million: An Introduction To ClusteringShubham SharmaNo ratings yet
- A Recommender System For Academic Projects RepositryDocument10 pagesA Recommender System For Academic Projects Repositrysonawaneabhishek69No ratings yet
- ICECCO2015Document5 pagesICECCO2015Syam sundharNo ratings yet
- Content Based Movie Recommendation System by PythonDocument44 pagesContent Based Movie Recommendation System by PythonAbhiNo ratings yet
- Music Recommendation System Using Content and Collaborative FilteringDocument5 pagesMusic Recommendation System Using Content and Collaborative FilteringGovind TripathiNo ratings yet


























































































Download as pptx, pdf, or txt
You might also like
- Wattpad: Artificial Intelligence & MarketingDocument3 pagesWattpad: Artificial Intelligence & MarketingsrishNo ratings yet
- Mitsubishi IC Pneumatic Forklift PDFDocument5 pagesMitsubishi IC Pneumatic Forklift PDFfdpc1987No ratings yet
- Music Similarity and RetrievalDocument313 pagesMusic Similarity and Retrievalieysimurra100% (1)
- P1903009-0ga-Ar-3801-Hygiene Master Ground Floor Plan - Overall PDFDocument1 pageP1903009-0ga-Ar-3801-Hygiene Master Ground Floor Plan - Overall PDFwrightwomanNo ratings yet
- Optimisation of Drilling Process: Rajahmundry Asset MDFF Training Batch - IV 31.07.2021Document11 pagesOptimisation of Drilling Process: Rajahmundry Asset MDFF Training Batch - IV 31.07.2021HrishabhJainNo ratings yet
- Presentation Market OverviewWorld Robotics 29-9-2016Document18 pagesPresentation Market OverviewWorld Robotics 29-9-2016Manuel CáceresNo ratings yet
- Presentation Market Overviewworld Robotics 29 9 2016 PDFDocument18 pagesPresentation Market Overviewworld Robotics 29 9 2016 PDFManuel CáceresNo ratings yet
- Floor Plan ViewsDocument2 pagesFloor Plan ViewsDorobantu CatalinNo ratings yet
- Experiences T Buzovschi MoldovaDocument29 pagesExperiences T Buzovschi MoldovakedayiNo ratings yet
- Guest House Review 02Document5 pagesGuest House Review 02Sunday JohnNo ratings yet
- R1 Cheruthony Truss 1 - 4Document1 pageR1 Cheruthony Truss 1 - 4Anujith K BabuNo ratings yet
- Operating Parameters Bit Load For Geotechnical Core Bits TD110 R1Document4 pagesOperating Parameters Bit Load For Geotechnical Core Bits TD110 R1Milko HarizanovNo ratings yet
- 2 - VL 17feb2023Document27 pages2 - VL 17feb2023Sergejs JaunzemsNo ratings yet
- Bouteiller 1Document27 pagesBouteiller 1Yaseen AlAjmi CompanyNo ratings yet
- Mezzaninie FloorDocument1 pageMezzaninie FloorElancheliyanNo ratings yet
- Brief Achievements UAFDocument5 pagesBrief Achievements UAFWaqar Akbar KhanNo ratings yet
- Analytics RoadmapDocument30 pagesAnalytics RoadmapmohmalNo ratings yet
- Floor Plan Views2Document60 pagesFloor Plan Views2Sharlene LynnetteNo ratings yet
- BT Plan - FY'24 - Final RahulDocument12 pagesBT Plan - FY'24 - Final RahulDurgaprasad ShettyNo ratings yet
- Appendix J - Manpower HistogramDocument1 pageAppendix J - Manpower HistogramAchu UnnikrishnanNo ratings yet
- Cia 3 - MobDocument5 pagesCia 3 - MobPADMANAP E 2127307No ratings yet
- Mezzanine FloorDocument1 pageMezzanine FloorpreconNo ratings yet
- Exide PresentationDocument17 pagesExide Presentationwasifur1230% (2)
- Catalogue LED XK-12.2019 - 4 PDFDocument100 pagesCatalogue LED XK-12.2019 - 4 PDFBinh VietNo ratings yet
- Keyword Research and Competitors Analysis of Clickbank University ProductDocument7 pagesKeyword Research and Competitors Analysis of Clickbank University ProductMohammed SultanNo ratings yet
- Electronet Equipments PVT LTD - Corporate PresentationDocument41 pagesElectronet Equipments PVT LTD - Corporate PresentationElectronet EquipmentsNo ratings yet
- Trens LathesDocument8 pagesTrens LathesGunay ChelikNo ratings yet
- Knowbigdata-Market PotentialDocument16 pagesKnowbigdata-Market Potentialkilladi123No ratings yet
- Liebherr LTM 1500-8.1: DimensionsDocument22 pagesLiebherr LTM 1500-8.1: DimensionsMohammed HafizNo ratings yet
- Prima Presentation LaserDocument28 pagesPrima Presentation Laser92piovaNo ratings yet
- Statistik Transportasi Laut 2019Document2 pagesStatistik Transportasi Laut 2019Bagus HuriNo ratings yet
- Economic Implications of Foreign Portfolio InvestmentsDocument18 pagesEconomic Implications of Foreign Portfolio Investmentsdharmesh_k91No ratings yet
- VSMAbrasives TechManualDocument12 pagesVSMAbrasives TechManualElep Tran LeNo ratings yet
- CBRI Annual Report 2017 2018 1 PDFDocument297 pagesCBRI Annual Report 2017 2018 1 PDFKshitij JainNo ratings yet
- Drawing1.Dwgغغغ ModelDocument1 pageDrawing1.Dwgغغغ Modelkano hibaNo ratings yet
- Cover Page Design For Digital DisplayDocument34 pagesCover Page Design For Digital DisplayJawms DalaNo ratings yet
- Construction of Baba Sarsai Nath Government Medical College, Sirsa, HaryanaDocument1 pageConstruction of Baba Sarsai Nath Government Medical College, Sirsa, Haryanaonlineielts200No ratings yet
- Going To South Drive, Pacdal, CBD Coming From Camp John HayDocument6 pagesGoing To South Drive, Pacdal, CBD Coming From Camp John HayRJay JacabanNo ratings yet
- Monthly Departmental Meeting For The Month of DECEMBER - 2020Document14 pagesMonthly Departmental Meeting For The Month of DECEMBER - 2020atiqNo ratings yet
- Architect P. Seeburun: Hal Serenity LTD Ground Floor Plan 29.11.2023 A-04Document1 pageArchitect P. Seeburun: Hal Serenity LTD Ground Floor Plan 29.11.2023 A-04Kem RaiNo ratings yet
- Become A Member: Today!Document2 pagesBecome A Member: Today!nassagNo ratings yet
- ???????? ??? ??? ????????? ??? ???? ?????????? !Document142 pages???????? ??? ??? ????????? ??? ???? ?????????? !sravanireddy.kotaNo ratings yet
- Preview Photograph QB GATE 2022 Recovered PDFDocument62 pagesPreview Photograph QB GATE 2022 Recovered PDFPronceNo ratings yet
- Notes: Ground Floor PlanDocument1 pageNotes: Ground Floor PlankingsleyclementakpanNo ratings yet
- Rejection Pareto Analysis: Dent Tool Mark Screch Mark Dim. Forging Mark Lining SettingDocument1 pageRejection Pareto Analysis: Dent Tool Mark Screch Mark Dim. Forging Mark Lining SettingMonik kotadiaNo ratings yet
- UTE523Document1 pageUTE523Proc. RembangNo ratings yet
- R2 Apex - Presentaion 22Document30 pagesR2 Apex - Presentaion 22awards.apexindiafoundationNo ratings yet
- Weekly Target & Mapping Jalur Supporting Ladder 2Document2 pagesWeekly Target & Mapping Jalur Supporting Ladder 2Edo renaldiNo ratings yet
- A101 - Ground Floor PlanDocument1 pageA101 - Ground Floor PlanDee-ar Inducil TrinidadNo ratings yet
- Copy of 02. Formulas_v1.0Document12 pagesCopy of 02. Formulas_v1.0mahalakshmi.kokkirimetti1994No ratings yet
- Metric Bolts - Minimum Ultimate Tensile & Proof LoadsDocument4 pagesMetric Bolts - Minimum Ultimate Tensile & Proof LoadsBenjamin IndrawanNo ratings yet
- Ambe Bhawani Layout CBSG-60Document1 pageAmbe Bhawani Layout CBSG-60arshad aliNo ratings yet
- I-A1-0150-Ground Floor General LayoutDocument1 pageI-A1-0150-Ground Floor General Layoutlinga2014No ratings yet
- Kpi T5Document1 pageKpi T5usmansaleem1501No ratings yet
- Statistics and Forecast 2021 - Q2Document15 pagesStatistics and Forecast 2021 - Q2Yassine YassineNo ratings yet
- About Nera Networks - May2006 - WebDocument17 pagesAbout Nera Networks - May2006 - WebMarco BarontiNo ratings yet
- Tour de Future ... of Čsob SKDocument18 pagesTour de Future ... of Čsob SKJakub NovotaNo ratings yet
- Revised Portacabin 003Document1 pageRevised Portacabin 003wangxiaofei926No ratings yet
- Site PlantDocument1 pageSite PlantMuhamadTaufikHidayatNo ratings yet
- Handbook-CivilAviationStatistics 2014-15Document28 pagesHandbook-CivilAviationStatistics 2014-15ashwinkumarsubramaniamNo ratings yet
- Tie Beam and Floor DetailDocument1 pageTie Beam and Floor DetailSuhail AhamedNo ratings yet
- Agile and Six SigmaDocument1 pageAgile and Six SigmapraveenNo ratings yet
- Trident Embassy Reso Price List-6Document2 pagesTrident Embassy Reso Price List-6praveenNo ratings yet
- Resume - Roshan Kumar SharmaDocument1 pageResume - Roshan Kumar SharmapraveenNo ratings yet
- Resume Aakash NagpalDocument1 pageResume Aakash NagpalpraveenNo ratings yet
- Patan Multiple Campus: Tribhuvan UniversityDocument61 pagesPatan Multiple Campus: Tribhuvan UniversitysumanNo ratings yet
- HuKorenVolinsky ICDM08Document10 pagesHuKorenVolinsky ICDM08aaa awwNo ratings yet
- Deep Learning Based Recommender System: A Survey and New PerspectivesDocument35 pagesDeep Learning Based Recommender System: A Survey and New PerspectivesSarı LacivertNo ratings yet
- AI Recommendation SystemDocument20 pagesAI Recommendation SystemChitra ParsailaNo ratings yet
- Scalable RecommendationDocument12 pagesScalable Recommendationnavneet prabhakarNo ratings yet
- Music Recommendation SystemDocument24 pagesMusic Recommendation SystemChinmai JosephNo ratings yet
- PR3215 - Movie - Recommendation - System-Report - PAVAN KUMAR P BDocument30 pagesPR3215 - Movie - Recommendation - System-Report - PAVAN KUMAR P BTushar JainNo ratings yet
- RecSys PyData2016Document32 pagesRecSys PyData2016Chong Hoo ChuahNo ratings yet
- Collaborative Filtering and Content-Based Recommendation of Documents and ProductsDocument9 pagesCollaborative Filtering and Content-Based Recommendation of Documents and ProductsUMA MNo ratings yet
- Transformation of Marketing at The Ohio Art Company (A) and (B) (Abridged)Document5 pagesTransformation of Marketing at The Ohio Art Company (A) and (B) (Abridged)Amit Anand KumarNo ratings yet
- MLCourse SlidesDocument356 pagesMLCourse SlidesSahas InnovapathNo ratings yet
- ResumeDocument2 pagesResumeSai Krishna KethanNo ratings yet
- ML Basics 02 (Statistics)Document438 pagesML Basics 02 (Statistics)Rishabh chaudhary100% (7)
- Movie Recommendation System PresentationDocument15 pagesMovie Recommendation System PresentationabhayNo ratings yet
- Report On Restaurant RecommendationDocument61 pagesReport On Restaurant RecommendationDeepikaNo ratings yet
- Unit-5 MahoutDocument26 pagesUnit-5 Mahoutsixit377870% (1)
- Automated Online Course Recommendation System Using Collaborative FilteringDocument10 pagesAutomated Online Course Recommendation System Using Collaborative FilteringIJRASETPublicationsNo ratings yet
- BFSMpR:A BFS Graph Based Recommendation System Using Map ReduceDocument5 pagesBFSMpR:A BFS Graph Based Recommendation System Using Map ReduceEditor IJRITCCNo ratings yet
- Movie Recommender System Using K-Means Clustering AND K-Nearest NeighborDocument6 pagesMovie Recommender System Using K-Means Clustering AND K-Nearest NeighborArmin ShahabNo ratings yet
- A Survey On Personalized Recommendation TechniquesDocument11 pagesA Survey On Personalized Recommendation TechniquesEditor IJRITCCNo ratings yet
- Information Sciences: Seok Kee Lee, Yoon Ho Cho, Soung Hie KimDocument14 pagesInformation Sciences: Seok Kee Lee, Yoon Ho Cho, Soung Hie KimAdeyekun Lateef Adekunle BestluckNo ratings yet
- Apache Mahout Essentials - Sample ChapterDocument25 pagesApache Mahout Essentials - Sample ChapterPackt PublishingNo ratings yet
- CS F469 Information Retrieval - HandoutDocument3 pagesCS F469 Information Retrieval - HandoutOPM RockyNo ratings yet
- Recommendations Worth A Million: An Introduction To ClusteringDocument42 pagesRecommendations Worth A Million: An Introduction To ClusteringShubham SharmaNo ratings yet
- A Recommender System For Academic Projects RepositryDocument10 pagesA Recommender System For Academic Projects Repositrysonawaneabhishek69No ratings yet
- ICECCO2015Document5 pagesICECCO2015Syam sundharNo ratings yet
- Content Based Movie Recommendation System by PythonDocument44 pagesContent Based Movie Recommendation System by PythonAbhiNo ratings yet
- Music Recommendation System Using Content and Collaborative FilteringDocument5 pagesMusic Recommendation System Using Content and Collaborative FilteringGovind TripathiNo ratings yet