Download as pptx, pdf, or txt
You might also like
- Johnny Pag Barhog-Service ManualDocument25 pagesJohnny Pag Barhog-Service Manual100regNo ratings yet
- Calpine Corp. The Evolution From Project To Corporate FinanceDocument4 pagesCalpine Corp. The Evolution From Project To Corporate FinanceDarshan Gosalia100% (1)
- Ficha Tecnica Alpha 30Document7 pagesFicha Tecnica Alpha 30jonathan francisco allende escobarNo ratings yet
- RR-250 SS-250: Road Reclaimer Soil StabilizerDocument8 pagesRR-250 SS-250: Road Reclaimer Soil StabilizerFabiano_P100% (1)
- ORF 544 Week 6 Modeling The Unified FrameworkDocument193 pagesORF 544 Week 6 Modeling The Unified FrameworkBruno BritoNo ratings yet
- ORF 544 Week 8 PFAs and Policy SearchDocument82 pagesORF 544 Week 8 PFAs and Policy SearchBruno BritoNo ratings yet
- ORF 544 Week 11 Approximate Dynamic Prograrmming Monotonicity and ConvexityDocument195 pagesORF 544 Week 11 Approximate Dynamic Prograrmming Monotonicity and ConvexityBruno BritoNo ratings yet
- Take Charge Understanding Your Electricty BillDocument2 pagesTake Charge Understanding Your Electricty Billneww33No ratings yet
- Solutions To Chapter 9 ProblemsDocument37 pagesSolutions To Chapter 9 ProblemsMorning KalalNo ratings yet
- Economics of Photovoltaic SystemsDocument40 pagesEconomics of Photovoltaic SystemsJoshua Pearce83% (6)
- Engineering Economy: Sensitivity AnalysisDocument28 pagesEngineering Economy: Sensitivity AnalysisJuvenJohn0% (1)
- Chapter Thirty-Four: Information TechnologyDocument62 pagesChapter Thirty-Four: Information TechnologyDejene TumisoNo ratings yet
- Byd Sutainable Development Strategy For Ev BatteryDocument31 pagesByd Sutainable Development Strategy For Ev Batterydoddy ChannelNo ratings yet
- Punjab Technical University: Strategic Financial ManagementDocument3 pagesPunjab Technical University: Strategic Financial ManagementRajyaLakshmiNo ratings yet
- For 9.220, Term 1, 2002/03 02 - Lecture19.ppt Student Version: 3. Summary and Conclusions (So Far)Document10 pagesFor 9.220, Term 1, 2002/03 02 - Lecture19.ppt Student Version: 3. Summary and Conclusions (So Far)Nahom endNo ratings yet
- Presentation of Wind Data - SlidesDocument15 pagesPresentation of Wind Data - SlidesC SzetoNo ratings yet
- Solved Quebec Canada Offers A Per Child Subsidy On Day Care ForDocument1 pageSolved Quebec Canada Offers A Per Child Subsidy On Day Care ForM Bilal SaleemNo ratings yet
- Grid - Interactive Solar Inverters - Anil TuladharDocument54 pagesGrid - Interactive Solar Inverters - Anil Tuladharrcrane99No ratings yet
- Capital Structure: © 2019 Pearson Education LTDDocument12 pagesCapital Structure: © 2019 Pearson Education LTDLeanne TehNo ratings yet
- Engineering Economic Analysis - Review: University of TorontoDocument25 pagesEngineering Economic Analysis - Review: University of TorontoHaiderNo ratings yet
- Portfolio ConstructionDocument6 pagesPortfolio Constructionhadiyyh2018No ratings yet
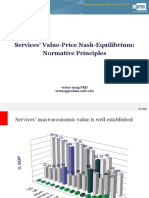
- Services' Value-Price Nash-Equilibrium: Normative PrinciplesDocument33 pagesServices' Value-Price Nash-Equilibrium: Normative PrinciplesMaximiliano OlivaresNo ratings yet
- Engeco Chap 11 Breakeven and Sensitivity AnalysisDocument26 pagesEngeco Chap 11 Breakeven and Sensitivity Analysisquark87100% (2)
- Capital Budgeting Under UncertaintyDocument30 pagesCapital Budgeting Under UncertaintyJyoti YadavNo ratings yet
- 5 Evolution of Electricity Market Regulation - March2022 LMeeus (VBS)Document63 pages5 Evolution of Electricity Market Regulation - March2022 LMeeus (VBS)Jesús CastellanosNo ratings yet
- This Study Resource WasDocument3 pagesThis Study Resource WaskalyanNo ratings yet
- This Study Resource WasDocument3 pagesThis Study Resource WaskalyanNo ratings yet
- 3 - Frictionless Commerce and Internet Law of GravityDocument32 pages3 - Frictionless Commerce and Internet Law of Gravitypanqi.pennNo ratings yet
- We Scar WrapDocument1 pageWe Scar WrapPetal RemonNo ratings yet
- Psa Backup 1 031108Document26 pagesPsa Backup 1 031108Greg aymondNo ratings yet
- Chapter 19 - Electric Potential Energy and Electric PotentialDocument43 pagesChapter 19 - Electric Potential Energy and Electric Potentialbob rob100% (1)
- CH 01 SMDocument10 pagesCH 01 SMarm195148No ratings yet
- Battery Replacing Service For Electric VehicleDocument4 pagesBattery Replacing Service For Electric VehicleJoshuaNo ratings yet
- TM4 MidDocument10 pagesTM4 MidAilea Kathleen BagtasNo ratings yet
- Solved True or False Suppliers Ability To Pass On An ExciseDocument1 pageSolved True or False Suppliers Ability To Pass On An ExciseM Bilal SaleemNo ratings yet
- Valuation and Capital Budgeting For The Levered Firm: Mcgraw-Hill/IrwinDocument34 pagesValuation and Capital Budgeting For The Levered Firm: Mcgraw-Hill/IrwinThanh ThanhNo ratings yet
- APP Megohm TelephoneCablesDocument3 pagesAPP Megohm TelephoneCablesHassanNo ratings yet
- CE 22 Ma. Brida Lea D. DiolaDocument34 pagesCE 22 Ma. Brida Lea D. DiolaaefNo ratings yet
- TYIT - SPM - L8 Project Evaluation2Document21 pagesTYIT - SPM - L8 Project Evaluation2sanilNo ratings yet
- Considerations When Designing A Wireless Charging SystemDocument10 pagesConsiderations When Designing A Wireless Charging SystemAhmed ElkhateebNo ratings yet
- LevelTenEnergy 6 PPA Risk FactorsDocument23 pagesLevelTenEnergy 6 PPA Risk FactorsDan StreetNo ratings yet
- Introduction To Wind Energy: James Mccalley Honors 322W, Wind Energy Honors SeminarDocument28 pagesIntroduction To Wind Energy: James Mccalley Honors 322W, Wind Energy Honors SeminarMohamed Al-OdatNo ratings yet
- 15 Sum Romich EnergyDocument40 pages15 Sum Romich EnergyPortgas D. AceNo ratings yet
- 660 Final Assignment (Maruf)Document29 pages660 Final Assignment (Maruf)Maruf ChowdhuryNo ratings yet
- CF Chapter 18Document34 pagesCF Chapter 18Nhi HoangNo ratings yet
- 5.ZCMA6022 CVP AnalysisDocument71 pages5.ZCMA6022 CVP AnalysisPAVITRAN JAGANAZANNo ratings yet
- Ol 2024Document5 pagesOl 2024umarrizwan208No ratings yet
- Statics Check Results: Job No Sheet No RevDocument1 pageStatics Check Results: Job No Sheet No RevrajatNo ratings yet
- Transportation Business Proposal TemplateDocument1 pageTransportation Business Proposal TemplateMAENBAL DUNIENo ratings yet
- Math For Business and Finance An Algebraic Approach 1St Edition Slater Solutions Manual Full Chapter PDFDocument27 pagesMath For Business and Finance An Algebraic Approach 1St Edition Slater Solutions Manual Full Chapter PDFfinndanielidm51t100% (11)
- Math For Business and Finance An Algebraic Approach 1st Edition Slater Solutions ManualDocument37 pagesMath For Business and Finance An Algebraic Approach 1st Edition Slater Solutions Manualhenrycpwcooper100% (17)
- Math For Business and Finance An Algebraic Approach 1st Edition Slater Solutions ManualDocument6 pagesMath For Business and Finance An Algebraic Approach 1st Edition Slater Solutions Manualxeniaanselmnxcbea100% (27)
- Landed CostDocument17 pagesLanded Costswapnil khokeNo ratings yet
- Whistler Blackcomb Sell PitchDocument8 pagesWhistler Blackcomb Sell Pitchawesomeamy071No ratings yet
- Introduction To Wind Energy: James Mccalley Honors 322W, Wind Energy Honors SeminarDocument28 pagesIntroduction To Wind Energy: James Mccalley Honors 322W, Wind Energy Honors SeminarMohammed Al-OdatNo ratings yet
- How To FinanceDocument20 pagesHow To FinanceChristian EstebanNo ratings yet
- Morningstar LC 04Document11 pagesMorningstar LC 04wahola2998No ratings yet
- Lesson 31 PDFDocument5 pagesLesson 31 PDFSusheel KumarNo ratings yet
- Evaluación Económica de Proyectos USIL 2020-2 - Session 29 - Sensitivity AnalysisDocument9 pagesEvaluación Económica de Proyectos USIL 2020-2 - Session 29 - Sensitivity Analysissergio benitesNo ratings yet
- Customer Persona Analysis For NEADocument5 pagesCustomer Persona Analysis For NEABhupesh ShresthaNo ratings yet
- Mid-1 Revision Worksheet-1Document6 pagesMid-1 Revision Worksheet-1Awaara AgentNo ratings yet
- Charging Ahead: Hydro-Québec and the Future of ElectricityFrom EverandCharging Ahead: Hydro-Québec and the Future of ElectricityNo ratings yet
- ORF 544 Week 12 Lookahead PoliciesDocument219 pagesORF 544 Week 12 Lookahead PoliciesBruno BritoNo ratings yet
- ORF 544 Week 11 Approximate Dynamic Prograrmming Monotonicity and ConvexityDocument195 pagesORF 544 Week 11 Approximate Dynamic Prograrmming Monotonicity and ConvexityBruno BritoNo ratings yet
- ORF 544 Week 6 Modeling The Unified FrameworkDocument193 pagesORF 544 Week 6 Modeling The Unified FrameworkBruno BritoNo ratings yet
- ORF 544 Week 2 Adaptive LearningDocument145 pagesORF 544 Week 2 Adaptive LearningBruno BritoNo ratings yet
- ORF 544 Week 8 PFAs and Policy SearchDocument82 pagesORF 544 Week 8 PFAs and Policy SearchBruno BritoNo ratings yet
- ORF 544 Week 4 Derivative Free Stochastic OptimizationDocument167 pagesORF 544 Week 4 Derivative Free Stochastic OptimizationBruno BritoNo ratings yet
- ORF 544 Week 5 Derivative Free Stochastic Optimization VFA and DLADocument123 pagesORF 544 Week 5 Derivative Free Stochastic Optimization VFA and DLABruno BritoNo ratings yet
- ORF 544 Week 3 Derivative Based Stochastic OptimizationDocument114 pagesORF 544 Week 3 Derivative Based Stochastic OptimizationBruno BritoNo ratings yet
- BOOK - Heuristics, Probability and Causality - A Tribute To Judea PearlDocument573 pagesBOOK - Heuristics, Probability and Causality - A Tribute To Judea PearlBruno BritoNo ratings yet
- Unisonic Technologies Co., LTD: 2A, 600V N-Channel Power MosfetDocument6 pagesUnisonic Technologies Co., LTD: 2A, 600V N-Channel Power MosfetAlex tiendaNo ratings yet
- Curriculum VitaeDocument11 pagesCurriculum Vitaeeca bcdNo ratings yet
- Crusher and CrushingDocument95 pagesCrusher and Crushinghtetmyatag 2014No ratings yet
- EasyPact EXE - EXE122608K3W611Document3 pagesEasyPact EXE - EXE122608K3W611Mohamoud MuseNo ratings yet
- Guidelines For FeedwaterDocument57 pagesGuidelines For FeedwaterUmut Kurt100% (1)
- Electric BellDocument8 pagesElectric Bellnassoro waziriNo ratings yet
- Unit - IIDocument35 pagesUnit - IIthota nagajyothiNo ratings yet
- GE Final ReportDocument122 pagesGE Final Report00083583rfNo ratings yet
- What Electrical Hazards Can You Identify at HomeDocument1 pageWhat Electrical Hazards Can You Identify at HomeJHONATONo ratings yet
- Importance of Sub-Station Equipment Maintenance: Presented by MD - Golam Mowla XEN (G&P)Document23 pagesImportance of Sub-Station Equipment Maintenance: Presented by MD - Golam Mowla XEN (G&P)rajshahieeeNo ratings yet
- Water Desalineation by Adsorption 3Document34 pagesWater Desalineation by Adsorption 3Mouhamed NdongNo ratings yet
- Executive SummaryDocument52 pagesExecutive SummaryAdarsh HeggannavarNo ratings yet
- Kinango Sub County Electrical Installation Bills of QuantitiesDocument3 pagesKinango Sub County Electrical Installation Bills of QuantitiesKassim NderiNo ratings yet
- Chapter 6 Heat and TemperatureDocument9 pagesChapter 6 Heat and TemperatureF1040 AleeyaNo ratings yet
- Electronic Timer - Series Micon 225: Multi Function Timer Multi Function Timer With 1 Instant & 1 Delayed C/ODocument2 pagesElectronic Timer - Series Micon 225: Multi Function Timer Multi Function Timer With 1 Instant & 1 Delayed C/ORohit chavanNo ratings yet
- Chapter 1-Semiconductor Basics-2-3Document40 pagesChapter 1-Semiconductor Basics-2-3Syed Zubair ZahidNo ratings yet
- ArgueCard IVR-L 100-30 PDFDocument2 pagesArgueCard IVR-L 100-30 PDFPulse XNo ratings yet
- Compressed PPT: Electric Potential, Work and Point ChargesDocument18 pagesCompressed PPT: Electric Potential, Work and Point ChargesJaylanie EvangelistaNo ratings yet
- Tutorial 4Document18 pagesTutorial 4Harrshit LimbodiaNo ratings yet
- FG FG Designation 004 Labels and Miscellaneous Materials: Business Portal Online Print 09-09-2016Document318 pagesFG FG Designation 004 Labels and Miscellaneous Materials: Business Portal Online Print 09-09-2016armaganNo ratings yet
- Automotive Film Product ListDocument1 pageAutomotive Film Product Listdarwise01No ratings yet
- MCQ CH 5-Electricity and Magnetism SL Level: (30 Marks)Document11 pagesMCQ CH 5-Electricity and Magnetism SL Level: (30 Marks)Hiya ShahNo ratings yet
- Fire Technology and Arson Investigation ModuleDocument15 pagesFire Technology and Arson Investigation ModuleNinoboy BaligatNo ratings yet
- Chandan Kumar SinghDocument1 pageChandan Kumar SinghSuryavanshi ChandanNo ratings yet
- Engine Performance Curve: Rating: Application:MarineDocument4 pagesEngine Performance Curve: Rating: Application:Marinekman548No ratings yet
- GSV2500211 189278 DatasheetDocument2 pagesGSV2500211 189278 DatasheetChamila DissanayakaNo ratings yet
- Epicyclic Speed Reduction Gears: MLN Block 405, Algeria Operator TrainingDocument8 pagesEpicyclic Speed Reduction Gears: MLN Block 405, Algeria Operator TrainingGUESSOUMANo ratings yet