
Unit 3 Routing: CO3: Outline The Functionality of Each Layer of The Network
Unit 3 Routing: CO3: Outline The Functionality of Each Layer of The Network
You might also like
- Hospital Network Design CC PDFDocument12 pagesHospital Network Design CC PDFpragnyashriprakhyaNo ratings yet
- D4 SBA Student Ans KeyDocument30 pagesD4 SBA Student Ans Key3qtrtym100% (1)
- Mikrotik Winbox TutorialDocument15 pagesMikrotik Winbox TutorialBokai LimaNo ratings yet
- 2.2.4.11 Lab - Configuring Switch Security Features - ILMDocument15 pages2.2.4.11 Lab - Configuring Switch Security Features - ILMJose Maria Rendon Rodriguez100% (1)
- 6.3.2.3 - Case Study - Prototype - Test The SolutionDocument4 pages6.3.2.3 - Case Study - Prototype - Test The SolutionNoor AthirahNo ratings yet
- BGP Unicast RoutingDocument55 pagesBGP Unicast RoutingsujithaNo ratings yet
- Unicast RoutingDocument58 pagesUnicast RoutingjoelanandrajNo ratings yet
- Unicast RoutingDocument70 pagesUnicast RoutingKarthik YogeshNo ratings yet
- Ec8551-Cn Unit-3 PDFDocument33 pagesEc8551-Cn Unit-3 PDFRithick BNo ratings yet
- RipospfDocument109 pagesRipospfJikku ThomasNo ratings yet
- ch22 Network Layer Routing Forwarding and DeliveryDocument40 pagesch22 Network Layer Routing Forwarding and Deliverysnehasikdar9279No ratings yet
- CCN Module 4 - Routing ProtocolsDocument47 pagesCCN Module 4 - Routing ProtocolsPrisha SinghaniaNo ratings yet
- Document From Harini.Document24 pagesDocument From Harini.prasannakarthik957No ratings yet
- Unicast RoutingDocument41 pagesUnicast Routingrsam19112003No ratings yet
- Cn-Unit Iii-NotesDocument39 pagesCn-Unit Iii-NotesRobin RobinNo ratings yet
- Chapter 4 - Routing and Routing ProtocolsDocument41 pagesChapter 4 - Routing and Routing Protocolstesfahuntilahun44No ratings yet
- CN R20 Unit-3Document19 pagesCN R20 Unit-3Indreshbabu BoyaNo ratings yet
- Case Study of Various Routing AlgorithmDocument25 pagesCase Study of Various Routing AlgorithmVijendra SolankiNo ratings yet
- Computer Network - Distance Vector Routing AlgorithmDocument8 pagesComputer Network - Distance Vector Routing AlgorithmNurlign YitbarekNo ratings yet
- Lec 20Document5 pagesLec 20Lewis IssacNo ratings yet
- Comparison of OSPF and RIP: AbstractDocument6 pagesComparison of OSPF and RIP: AbstractSushma LuhachNo ratings yet
- CNDocument13 pagesCNsuryamadhuchandran007No ratings yet
- Ch6 - Part1Document32 pagesCh6 - Part1Ibrahem AhmadNo ratings yet
- CN Material Unit-4 2023Document34 pagesCN Material Unit-4 2023Sacet 2003No ratings yet
- Network Layer Delivery, Forwarding and RoutingDocument46 pagesNetwork Layer Delivery, Forwarding and RoutingJohn AmonNo ratings yet
- Session-20 Network Layer RoutingDocument14 pagesSession-20 Network Layer RoutingKamal ThelagaNo ratings yet
- Network Layer - RoutingDocument83 pagesNetwork Layer - RoutingRohan BhattadNo ratings yet
- CN - Unit3.1Document49 pagesCN - Unit3.1Nishant BHARDWAJ100% (1)
- 4 Interconnecting DevicesDocument25 pages4 Interconnecting Devicespjain8be22No ratings yet
- Interconnecting DevicesDocument25 pagesInterconnecting DevicesAkshita GuptaNo ratings yet
- The Network LayerDocument75 pagesThe Network LayerRahulNo ratings yet
- 6.02 Practice Problems - Routing PDFDocument10 pages6.02 Practice Problems - Routing PDFalanNo ratings yet
- Routing ProtocolsDocument28 pagesRouting ProtocolstiffNo ratings yet
- 5 - Routing Algorithm Part2Document9 pages5 - Routing Algorithm Part2Mohmed AwadNo ratings yet
- AssignmentDocument4 pagesAssignmentHima Bindhu BusireddyNo ratings yet
- Mobile Adhoc+NetworkDocument157 pagesMobile Adhoc+NetworkSourav SinhaNo ratings yet
- 4 - Routing Algorithm Part1Document11 pages4 - Routing Algorithm Part1Mohmed AwadNo ratings yet
- CH 22Document43 pagesCH 22ADNo ratings yet
- NetworkLayer RoutingDocument64 pagesNetworkLayer RoutingRishiGuptaNo ratings yet
- Online Class 13 RoutingDocument23 pagesOnline Class 13 RoutingAshNo ratings yet
- Routing Algorithms 1663584102198Document120 pagesRouting Algorithms 1663584102198Hari RamNo ratings yet
- Unit 4Document16 pagesUnit 4Senthilnathan SNo ratings yet
- RoutingDocument27 pagesRoutingSirf VivekNo ratings yet
- Routing AlgorithmsDocument36 pagesRouting AlgorithmsKartik Aneja0% (1)
- Network Layer: Delivery, Forwarding, and RoutingDocument141 pagesNetwork Layer: Delivery, Forwarding, and RoutingSagarVanaraseNo ratings yet
- Routing AlgorithmsDocument10 pagesRouting AlgorithmsBabita NaagarNo ratings yet
- Lec3 InnerconnectionNetworksDocument28 pagesLec3 InnerconnectionNetworksSAINo ratings yet
- Network LayerDocument18 pagesNetwork LayerChamara PrasannaNo ratings yet
- Module - 3 Network LayerDocument27 pagesModule - 3 Network Layer1NC21IS033 Manoj jayanth NNo ratings yet
- Network Layer PDFDocument53 pagesNetwork Layer PDFAravinda A KumarNo ratings yet
- 3.distance Vector RoutingDocument38 pages3.distance Vector RoutingDivya K.SNo ratings yet
- 07 Network Layer Print PDFDocument26 pages07 Network Layer Print PDFMatthew BattleNo ratings yet
- Week 08-09 - Ch20 - p1Document23 pagesWeek 08-09 - Ch20 - p1abdulazizbinyabtempNo ratings yet
- Unit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)Document28 pagesUnit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)karthik vaddiNo ratings yet
- 21fa MidtermDocument15 pages21fa MidtermmisschuachinNo ratings yet
- Cse 538 Manet DV DSDVDocument68 pagesCse 538 Manet DV DSDVVijay BhattooNo ratings yet
- CN WK 11 Lec 21 22Document19 pagesCN WK 11 Lec 21 22noreencosmetics45No ratings yet
- CNS Mod 3 NLDocument23 pagesCNS Mod 3 NLSamanthNo ratings yet
- Unit 3Document31 pagesUnit 320H51A04P3-PEDAPUDI SHAKTHI GANESH B.Tech ECE (2020-24)No ratings yet
- COMPUTER NETWORKS Unit-3 NotesDocument23 pagesCOMPUTER NETWORKS Unit-3 NotesyashhardasaniNo ratings yet
- Datagram Forwarding: Asst. Prof. Chaiporn Jaikaeo, PH.DDocument39 pagesDatagram Forwarding: Asst. Prof. Chaiporn Jaikaeo, PH.DDorian GreyNo ratings yet
- Project BudgetDocument2 pagesProject BudgetB.BijuNo ratings yet
- Teamname: NumbersDocument8 pagesTeamname: NumbersB.BijuNo ratings yet
- 3 RD UnitDocument2 pages3 RD UnitB.BijuNo ratings yet
- MG8591-2 and 3Document24 pagesMG8591-2 and 3B.BijuNo ratings yet
- EnglishDocument9 pagesEnglishB.BijuNo ratings yet
- 2 ND UnitDocument3 pages2 ND UnitB.BijuNo ratings yet
- Fiber@Home LTD.: Md. Arafat NazmulDocument46 pagesFiber@Home LTD.: Md. Arafat NazmulImtiaz AhmedNo ratings yet
- Cisco BGP Lab Manual: Read/DownloadDocument2 pagesCisco BGP Lab Manual: Read/DownloadNetwork Bull0% (1)
- Contrail Networking Monitoring and Troubleshooting GuideDocument537 pagesContrail Networking Monitoring and Troubleshooting GuideKos DieNo ratings yet
- Cisco UCCE 904Document12 pagesCisco UCCE 904Sushil Bandal-deshmukhNo ratings yet
- CR 300Document264 pagesCR 300DINONo ratings yet
- Motorola TETRA Infrastructure Technical Documentation Library Dimetra IPCompact8.1 System Overview DIPCDocument250 pagesMotorola TETRA Infrastructure Technical Documentation Library Dimetra IPCompact8.1 System Overview DIPCkkqd2639No ratings yet
- Cisco GPLDocument3,506 pagesCisco GPLOdranoelGomesNo ratings yet
- MPLS LDP (Label Distribution Protocol)Document5 pagesMPLS LDP (Label Distribution Protocol)Emad MohamedNo ratings yet
- RTN 910A ProductoDocument484 pagesRTN 910A ProductoGabriel NavaNo ratings yet
- CSE3003 - Computer Networks - Lab Sheet: 7Document4 pagesCSE3003 - Computer Networks - Lab Sheet: 7Arjun ArjunNo ratings yet
- Configuring and Testing Border Gateway Protocol (BGP) On Basis of Cisco Hardware and Linux Gentoo With Quagga Package (Zebra)Document19 pagesConfiguring and Testing Border Gateway Protocol (BGP) On Basis of Cisco Hardware and Linux Gentoo With Quagga Package (Zebra)Coolz SeanNo ratings yet
- Data Sheet The IP VSAT Satellite WAN NetworkDocument3 pagesData Sheet The IP VSAT Satellite WAN NetworkHarsa TadayoshiNo ratings yet
- CN Chapter 2 SolutionsDocument7 pagesCN Chapter 2 SolutionsToon MeNo ratings yet
- Lab 6-2 Using The AS - PATH Attribute: Topology DiagramDocument8 pagesLab 6-2 Using The AS - PATH Attribute: Topology DiagramNidoninoNo ratings yet
- Amazon VPC Interview QuestionsDocument12 pagesAmazon VPC Interview QuestionsABHILASH NAMBIARNo ratings yet
- Irgtbook Router Command BookDocument842 pagesIrgtbook Router Command BookBlek Le Roc100% (1)
- Firewall 86 SlidesDocument86 pagesFirewall 86 SlidesHarneet Singh ChuggaNo ratings yet
- WBR 1310 DatasheetDocument2 pagesWBR 1310 DatasheetClaudio Renato dos Santos JuniorNo ratings yet
- Arp ProtocolDocument38 pagesArp ProtocolArivazhagan ChinnamadhuNo ratings yet
- What Is The Difference Between T568ADocument22 pagesWhat Is The Difference Between T568AGoodsonNo ratings yet
- User Guide: EST9120/EST16120 9/16 Channel MPEG-4 Triplex DVR V. 1.5Document74 pagesUser Guide: EST9120/EST16120 9/16 Channel MPEG-4 Triplex DVR V. 1.5Florin AnghelNo ratings yet
- 9.2.1.10 Packet Tracer Configuring Standard ACLs Instructions IG - Alexis PedrozaDocument8 pages9.2.1.10 Packet Tracer Configuring Standard ACLs Instructions IG - Alexis Pedrozaalexis pedrozaNo ratings yet
- Websense Proxy Configuration PDFDocument46 pagesWebsense Proxy Configuration PDFAbhishek GhoshNo ratings yet
- Packet SniffingDocument13 pagesPacket SniffingMohan KokkulaNo ratings yet
- LAN TopologiesDocument31 pagesLAN TopologiesDinku Minda100% (1)



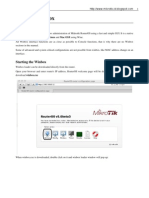




























































































Download as ppt, pdf, or txt
You might also like
- Hospital Network Design CC PDFDocument12 pagesHospital Network Design CC PDFpragnyashriprakhyaNo ratings yet
- D4 SBA Student Ans KeyDocument30 pagesD4 SBA Student Ans Key3qtrtym100% (1)
- Mikrotik Winbox TutorialDocument15 pagesMikrotik Winbox TutorialBokai LimaNo ratings yet
- 2.2.4.11 Lab - Configuring Switch Security Features - ILMDocument15 pages2.2.4.11 Lab - Configuring Switch Security Features - ILMJose Maria Rendon Rodriguez100% (1)
- 6.3.2.3 - Case Study - Prototype - Test The SolutionDocument4 pages6.3.2.3 - Case Study - Prototype - Test The SolutionNoor AthirahNo ratings yet
- BGP Unicast RoutingDocument55 pagesBGP Unicast RoutingsujithaNo ratings yet
- Unicast RoutingDocument58 pagesUnicast RoutingjoelanandrajNo ratings yet
- Unicast RoutingDocument70 pagesUnicast RoutingKarthik YogeshNo ratings yet
- Ec8551-Cn Unit-3 PDFDocument33 pagesEc8551-Cn Unit-3 PDFRithick BNo ratings yet
- RipospfDocument109 pagesRipospfJikku ThomasNo ratings yet
- ch22 Network Layer Routing Forwarding and DeliveryDocument40 pagesch22 Network Layer Routing Forwarding and Deliverysnehasikdar9279No ratings yet
- CCN Module 4 - Routing ProtocolsDocument47 pagesCCN Module 4 - Routing ProtocolsPrisha SinghaniaNo ratings yet
- Document From Harini.Document24 pagesDocument From Harini.prasannakarthik957No ratings yet
- Unicast RoutingDocument41 pagesUnicast Routingrsam19112003No ratings yet
- Cn-Unit Iii-NotesDocument39 pagesCn-Unit Iii-NotesRobin RobinNo ratings yet
- Chapter 4 - Routing and Routing ProtocolsDocument41 pagesChapter 4 - Routing and Routing Protocolstesfahuntilahun44No ratings yet
- CN R20 Unit-3Document19 pagesCN R20 Unit-3Indreshbabu BoyaNo ratings yet
- Case Study of Various Routing AlgorithmDocument25 pagesCase Study of Various Routing AlgorithmVijendra SolankiNo ratings yet
- Computer Network - Distance Vector Routing AlgorithmDocument8 pagesComputer Network - Distance Vector Routing AlgorithmNurlign YitbarekNo ratings yet
- Lec 20Document5 pagesLec 20Lewis IssacNo ratings yet
- Comparison of OSPF and RIP: AbstractDocument6 pagesComparison of OSPF and RIP: AbstractSushma LuhachNo ratings yet
- CNDocument13 pagesCNsuryamadhuchandran007No ratings yet
- Ch6 - Part1Document32 pagesCh6 - Part1Ibrahem AhmadNo ratings yet
- CN Material Unit-4 2023Document34 pagesCN Material Unit-4 2023Sacet 2003No ratings yet
- Network Layer Delivery, Forwarding and RoutingDocument46 pagesNetwork Layer Delivery, Forwarding and RoutingJohn AmonNo ratings yet
- Session-20 Network Layer RoutingDocument14 pagesSession-20 Network Layer RoutingKamal ThelagaNo ratings yet
- Network Layer - RoutingDocument83 pagesNetwork Layer - RoutingRohan BhattadNo ratings yet
- CN - Unit3.1Document49 pagesCN - Unit3.1Nishant BHARDWAJ100% (1)
- 4 Interconnecting DevicesDocument25 pages4 Interconnecting Devicespjain8be22No ratings yet
- Interconnecting DevicesDocument25 pagesInterconnecting DevicesAkshita GuptaNo ratings yet
- The Network LayerDocument75 pagesThe Network LayerRahulNo ratings yet
- 6.02 Practice Problems - Routing PDFDocument10 pages6.02 Practice Problems - Routing PDFalanNo ratings yet
- Routing ProtocolsDocument28 pagesRouting ProtocolstiffNo ratings yet
- 5 - Routing Algorithm Part2Document9 pages5 - Routing Algorithm Part2Mohmed AwadNo ratings yet
- AssignmentDocument4 pagesAssignmentHima Bindhu BusireddyNo ratings yet
- Mobile Adhoc+NetworkDocument157 pagesMobile Adhoc+NetworkSourav SinhaNo ratings yet
- 4 - Routing Algorithm Part1Document11 pages4 - Routing Algorithm Part1Mohmed AwadNo ratings yet
- CH 22Document43 pagesCH 22ADNo ratings yet
- NetworkLayer RoutingDocument64 pagesNetworkLayer RoutingRishiGuptaNo ratings yet
- Online Class 13 RoutingDocument23 pagesOnline Class 13 RoutingAshNo ratings yet
- Routing Algorithms 1663584102198Document120 pagesRouting Algorithms 1663584102198Hari RamNo ratings yet
- Unit 4Document16 pagesUnit 4Senthilnathan SNo ratings yet
- RoutingDocument27 pagesRoutingSirf VivekNo ratings yet
- Routing AlgorithmsDocument36 pagesRouting AlgorithmsKartik Aneja0% (1)
- Network Layer: Delivery, Forwarding, and RoutingDocument141 pagesNetwork Layer: Delivery, Forwarding, and RoutingSagarVanaraseNo ratings yet
- Routing AlgorithmsDocument10 pagesRouting AlgorithmsBabita NaagarNo ratings yet
- Lec3 InnerconnectionNetworksDocument28 pagesLec3 InnerconnectionNetworksSAINo ratings yet
- Network LayerDocument18 pagesNetwork LayerChamara PrasannaNo ratings yet
- Module - 3 Network LayerDocument27 pagesModule - 3 Network Layer1NC21IS033 Manoj jayanth NNo ratings yet
- Network Layer PDFDocument53 pagesNetwork Layer PDFAravinda A KumarNo ratings yet
- 3.distance Vector RoutingDocument38 pages3.distance Vector RoutingDivya K.SNo ratings yet
- 07 Network Layer Print PDFDocument26 pages07 Network Layer Print PDFMatthew BattleNo ratings yet
- Week 08-09 - Ch20 - p1Document23 pagesWeek 08-09 - Ch20 - p1abdulazizbinyabtempNo ratings yet
- Unit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)Document28 pagesUnit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)karthik vaddiNo ratings yet
- 21fa MidtermDocument15 pages21fa MidtermmisschuachinNo ratings yet
- Cse 538 Manet DV DSDVDocument68 pagesCse 538 Manet DV DSDVVijay BhattooNo ratings yet
- CN WK 11 Lec 21 22Document19 pagesCN WK 11 Lec 21 22noreencosmetics45No ratings yet
- CNS Mod 3 NLDocument23 pagesCNS Mod 3 NLSamanthNo ratings yet
- Unit 3Document31 pagesUnit 320H51A04P3-PEDAPUDI SHAKTHI GANESH B.Tech ECE (2020-24)No ratings yet
- COMPUTER NETWORKS Unit-3 NotesDocument23 pagesCOMPUTER NETWORKS Unit-3 NotesyashhardasaniNo ratings yet
- Datagram Forwarding: Asst. Prof. Chaiporn Jaikaeo, PH.DDocument39 pagesDatagram Forwarding: Asst. Prof. Chaiporn Jaikaeo, PH.DDorian GreyNo ratings yet
- Project BudgetDocument2 pagesProject BudgetB.BijuNo ratings yet
- Teamname: NumbersDocument8 pagesTeamname: NumbersB.BijuNo ratings yet
- 3 RD UnitDocument2 pages3 RD UnitB.BijuNo ratings yet
- MG8591-2 and 3Document24 pagesMG8591-2 and 3B.BijuNo ratings yet
- EnglishDocument9 pagesEnglishB.BijuNo ratings yet
- 2 ND UnitDocument3 pages2 ND UnitB.BijuNo ratings yet
- Fiber@Home LTD.: Md. Arafat NazmulDocument46 pagesFiber@Home LTD.: Md. Arafat NazmulImtiaz AhmedNo ratings yet
- Cisco BGP Lab Manual: Read/DownloadDocument2 pagesCisco BGP Lab Manual: Read/DownloadNetwork Bull0% (1)
- Contrail Networking Monitoring and Troubleshooting GuideDocument537 pagesContrail Networking Monitoring and Troubleshooting GuideKos DieNo ratings yet
- Cisco UCCE 904Document12 pagesCisco UCCE 904Sushil Bandal-deshmukhNo ratings yet
- CR 300Document264 pagesCR 300DINONo ratings yet
- Motorola TETRA Infrastructure Technical Documentation Library Dimetra IPCompact8.1 System Overview DIPCDocument250 pagesMotorola TETRA Infrastructure Technical Documentation Library Dimetra IPCompact8.1 System Overview DIPCkkqd2639No ratings yet
- Cisco GPLDocument3,506 pagesCisco GPLOdranoelGomesNo ratings yet
- MPLS LDP (Label Distribution Protocol)Document5 pagesMPLS LDP (Label Distribution Protocol)Emad MohamedNo ratings yet
- RTN 910A ProductoDocument484 pagesRTN 910A ProductoGabriel NavaNo ratings yet
- CSE3003 - Computer Networks - Lab Sheet: 7Document4 pagesCSE3003 - Computer Networks - Lab Sheet: 7Arjun ArjunNo ratings yet
- Configuring and Testing Border Gateway Protocol (BGP) On Basis of Cisco Hardware and Linux Gentoo With Quagga Package (Zebra)Document19 pagesConfiguring and Testing Border Gateway Protocol (BGP) On Basis of Cisco Hardware and Linux Gentoo With Quagga Package (Zebra)Coolz SeanNo ratings yet
- Data Sheet The IP VSAT Satellite WAN NetworkDocument3 pagesData Sheet The IP VSAT Satellite WAN NetworkHarsa TadayoshiNo ratings yet
- CN Chapter 2 SolutionsDocument7 pagesCN Chapter 2 SolutionsToon MeNo ratings yet
- Lab 6-2 Using The AS - PATH Attribute: Topology DiagramDocument8 pagesLab 6-2 Using The AS - PATH Attribute: Topology DiagramNidoninoNo ratings yet
- Amazon VPC Interview QuestionsDocument12 pagesAmazon VPC Interview QuestionsABHILASH NAMBIARNo ratings yet
- Irgtbook Router Command BookDocument842 pagesIrgtbook Router Command BookBlek Le Roc100% (1)
- Firewall 86 SlidesDocument86 pagesFirewall 86 SlidesHarneet Singh ChuggaNo ratings yet
- WBR 1310 DatasheetDocument2 pagesWBR 1310 DatasheetClaudio Renato dos Santos JuniorNo ratings yet
- Arp ProtocolDocument38 pagesArp ProtocolArivazhagan ChinnamadhuNo ratings yet
- What Is The Difference Between T568ADocument22 pagesWhat Is The Difference Between T568AGoodsonNo ratings yet
- User Guide: EST9120/EST16120 9/16 Channel MPEG-4 Triplex DVR V. 1.5Document74 pagesUser Guide: EST9120/EST16120 9/16 Channel MPEG-4 Triplex DVR V. 1.5Florin AnghelNo ratings yet
- 9.2.1.10 Packet Tracer Configuring Standard ACLs Instructions IG - Alexis PedrozaDocument8 pages9.2.1.10 Packet Tracer Configuring Standard ACLs Instructions IG - Alexis Pedrozaalexis pedrozaNo ratings yet
- Websense Proxy Configuration PDFDocument46 pagesWebsense Proxy Configuration PDFAbhishek GhoshNo ratings yet
- Packet SniffingDocument13 pagesPacket SniffingMohan KokkulaNo ratings yet
- LAN TopologiesDocument31 pagesLAN TopologiesDinku Minda100% (1)