
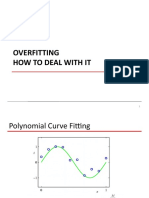
CNN Variants V1
CNN Variants V1
You might also like
- ML Interview Cheat SheetDocument9 pagesML Interview Cheat Sheetwing444No ratings yet
- CNN Architectures-Stanford-Small SizeDocument95 pagesCNN Architectures-Stanford-Small SizeZee IngameNo ratings yet
- cs231n 2018 Lecture09Document106 pagescs231n 2018 Lecture09Đào TiênNo ratings yet
- 5b DanaDocument67 pages5b Dana22 / Gyanaranjan NayakNo ratings yet
- CS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDocument167 pagesCS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDEEP ROYNo ratings yet
- 09 ConvNet ArchitecturesDocument86 pages09 ConvNet ArchitecturesalokNo ratings yet
- Aidl 2023s DL 08 CNN ArchitecturesDocument51 pagesAidl 2023s DL 08 CNN ArchitecturesOuriNo ratings yet
- Convolutional NetworksDocument211 pagesConvolutional NetworksiamrishitagangulyNo ratings yet
- Alex NetDocument11 pagesAlex NetMackrish MalikNo ratings yet
- CNN Architectures - Transfer LearningDocument64 pagesCNN Architectures - Transfer LearningBaraniNo ratings yet
- CNN For Computer Vision Problem (Session 1)Document43 pagesCNN For Computer Vision Problem (Session 1)haryantoNo ratings yet
- Cesar Lcpcv5 Tutorial12 v11 GBDocument24 pagesCesar Lcpcv5 Tutorial12 v11 GBJasmin AgriNo ratings yet
- DSE 3151 25 Sep 2023Document9 pagesDSE 3151 25 Sep 2023KaiNo ratings yet
- VGG and ResnetDocument18 pagesVGG and Resnetsaisivani.ashok2021No ratings yet
- Tutorial On DNN 02 Popular DNNs DatasetsDocument60 pagesTutorial On DNN 02 Popular DNNs DatasetsSrikanthNo ratings yet
- Imp.-Image Category Classification Using Deep Learning-MATLABDocument9 pagesImp.-Image Category Classification Using Deep Learning-MATLABMirceaNo ratings yet
- Module3 CasestudyDocument13 pagesModule3 CasestudyDevarenjini PNo ratings yet
- Lenet 5Document14 pagesLenet 5Sathwik ChandraNo ratings yet
- Mobilenet SSDv2An Improved Object Detection Model For Embedded SystemsDocument5 pagesMobilenet SSDv2An Improved Object Detection Model For Embedded Systemsputra mulia rizky selianNo ratings yet
- Accelerating CFD Simulations With Gpus: Patrice CastonguayDocument67 pagesAccelerating CFD Simulations With Gpus: Patrice CastonguayastudespusNo ratings yet
- Transfer Learning - Part 1Document16 pagesTransfer Learning - Part 1AditiNo ratings yet
- DNN ArchitecturesDocument12 pagesDNN Architecturesshreyagoudar06No ratings yet
- Convolution Neural Network: CP - 6 Machine Learning M S PrasadDocument28 pagesConvolution Neural Network: CP - 6 Machine Learning M S PrasadM S PrasadNo ratings yet
- Lecture11 - CNN ArchitecturesDocument129 pagesLecture11 - CNN ArchitecturesCariza DiasNo ratings yet
- Convolutional Neural Networks-Part2Document21 pagesConvolutional Neural Networks-Part2polinati.vinesh2023No ratings yet
- Data Science Interview Preparation (#DAY 14)Document11 pagesData Science Interview Preparation (#DAY 14)ARPAN MAITYNo ratings yet
- Mi Lecture KX Part 1Document38 pagesMi Lecture KX Part 1Sejal KaleNo ratings yet
- Carbon Nanotube Computing: Subhasish Mitra Collaborator: H.-S. Philip WongDocument50 pagesCarbon Nanotube Computing: Subhasish Mitra Collaborator: H.-S. Philip WongnanoteraCHNo ratings yet
- Lecture 6 CNN - DetectionDocument48 pagesLecture 6 CNN - DetectionAbdou AbdelaliNo ratings yet
- NN 07Document24 pagesNN 07youssef husseinNo ratings yet
- Architecture HandbookDocument19 pagesArchitecture HandbookAnonymous fqvjeG008BNo ratings yet
- Literature Review On Image Classification ArchitectureDocument14 pagesLiterature Review On Image Classification ArchitectureMahiNo ratings yet
- ENGG1015 Tutorial 5 HandoutDocument8 pagesENGG1015 Tutorial 5 HandoutAnonymous K4n797INo ratings yet
- Light Pipes For MatlabDocument113 pagesLight Pipes For MatlabHaripriya MuralikrishnanNo ratings yet
- Assignment 3Document5 pagesAssignment 3SaurabhNo ratings yet
- Convolution Neural Network: CP - 6 Machine Learning M S PrasadDocument37 pagesConvolution Neural Network: CP - 6 Machine Learning M S PrasadMani S Prasad100% (1)
- Sequential Monte Carlo Methods: A Survey: Elise ArnaudDocument43 pagesSequential Monte Carlo Methods: A Survey: Elise ArnaudneilwuNo ratings yet
- Deepirisnet: Deep Iris Representation With Applications in Iris Recognition and Cross-Sensor Iris RecognitionDocument5 pagesDeepirisnet: Deep Iris Representation With Applications in Iris Recognition and Cross-Sensor Iris RecognitionpedroNo ratings yet
- Lead CompensatorDocument13 pagesLead CompensatorMohammed MohsinNo ratings yet
- Convolutional Neural Network ReportDocument5 pagesConvolutional Neural Network ReportNatasha HanafiNo ratings yet
- Fast Fourier Transform: VLSI Architectures: Vladimir StojanovićDocument26 pagesFast Fourier Transform: VLSI Architectures: Vladimir StojanovićTharun ThampanNo ratings yet
- Lecture 3Document12 pagesLecture 3aly869556No ratings yet
- Lab 6: Quality of Service: DCNI-2Document20 pagesLab 6: Quality of Service: DCNI-2h3d0nistNo ratings yet
- a-GIST CNNs Quicksummary HyungukDocument25 pagesa-GIST CNNs Quicksummary Hyunguk최희욱No ratings yet
- CNN IitkgpDocument112 pagesCNN Iitkgpamrutamhetre9No ratings yet
- HYPERMESHDocument19 pagesHYPERMESHSharan AnnapuraNo ratings yet
- Hardware Accelerated Convolutional Neural Networks For Synthetic Vision SystemsDocument4 pagesHardware Accelerated Convolutional Neural Networks For Synthetic Vision Systemsddatdh1No ratings yet
- Apprentissage Automatique Et Apprentissage Profond: Réseaux de Neurones Profonds (Deep Neural Network)Document20 pagesApprentissage Automatique Et Apprentissage Profond: Réseaux de Neurones Profonds (Deep Neural Network)MehdiNo ratings yet
- Pattern Classification Using Simplified Neural Networks With Pruning AlgorithmDocument7 pagesPattern Classification Using Simplified Neural Networks With Pruning AlgorithmThái SơnNo ratings yet
- Video Processing Communications Yao Wang Chapter6bDocument32 pagesVideo Processing Communications Yao Wang Chapter6bAshoka VanjareNo ratings yet
- Week 7 - Network FlowDocument47 pagesWeek 7 - Network FlowHaris AhmedNo ratings yet
- DSE 5251 Insem1 SchemeDocument8 pagesDSE 5251 Insem1 SchemeBalathrinath ReddyNo ratings yet
- Imp Questions For Ci - UpdateDocument8 pagesImp Questions For Ci - Updaterajeshwari64.yNo ratings yet
- Introduction To Management Science: Session 13Document26 pagesIntroduction To Management Science: Session 13Haris AliNo ratings yet
- Motion Estimtion and Motion Compensated (Video) CodingDocument41 pagesMotion Estimtion and Motion Compensated (Video) CodingPravin MuliyashiyaNo ratings yet
- hw2Document2 pageshw2RavindraSamriaNo ratings yet
- CNN 22mar2017Document110 pagesCNN 22mar2017Rahul AryanNo ratings yet
- Video Coding (VC-1)Document35 pagesVideo Coding (VC-1)Kholidiyah Masykuroh YusufNo ratings yet
- Digital Mobile Communications and the TETRA SystemFrom EverandDigital Mobile Communications and the TETRA SystemRating: 5 out of 5 stars5/5 (1)
- Regression and Regularization V4.1Document48 pagesRegression and Regularization V4.1Eman zakriaNo ratings yet
- Introduction To: Support Vector MachinesDocument53 pagesIntroduction To: Support Vector MachinesEman zakriaNo ratings yet
- Face Detection and Recognition 2019Document20 pagesFace Detection and Recognition 2019Eman zakriaNo ratings yet
- Verification CVSDocument97 pagesVerification CVSEman zakriaNo ratings yet
- Lec7 OOPDocument31 pagesLec7 OOPEman zakriaNo ratings yet
- Types of TestBench and Fork JoinDocument46 pagesTypes of TestBench and Fork JoinEman zakriaNo ratings yet
- VerifyDocument44 pagesVerifyEman zakriaNo ratings yet
- Real-Time Human Tracking Using Multi-Features Visual With CNN-LSTM and Q-LearningDocument15 pagesReal-Time Human Tracking Using Multi-Features Visual With CNN-LSTM and Q-LearningEDARA KEERTHI LAHARINo ratings yet
- A Hybrid Analysis-Based Approach To Android Malware Family ClassificationDocument23 pagesA Hybrid Analysis-Based Approach To Android Malware Family ClassificationDanh Nguyễn CôngNo ratings yet
- L10 - Intro - To - Deep - LearningDocument75 pagesL10 - Intro - To - Deep - LearningNALE SVPMEnggNo ratings yet
- Asian Face Recognition Improving Robustness and Performance Using YOLODocument5 pagesAsian Face Recognition Improving Robustness and Performance Using YOLOmohamed aliNo ratings yet
- 50 Most Important CNN Interview QuestionsDocument18 pages50 Most Important CNN Interview QuestionsDeepak KumarNo ratings yet
- Iceberg Ship Classification of Satellite Radar ImagesDocument25 pagesIceberg Ship Classification of Satellite Radar ImagesKaran UpareNo ratings yet
- Facial Recognition of Cattle Based On SK-ResNetDocument10 pagesFacial Recognition of Cattle Based On SK-ResNetWaleed AhmedNo ratings yet
- Res Net 2Document40 pagesRes Net 2jaffar bikatNo ratings yet
- Age Group and Gender Estimation in The Wild With Deep Ror ArchitectureDocument11 pagesAge Group and Gender Estimation in The Wild With Deep Ror ArchitectureAnil Kumar BNo ratings yet
- Pus Algebraic Statistics Volume 13 Issue 3Document12 pagesPus Algebraic Statistics Volume 13 Issue 3TefeNo ratings yet
- SPLN Proc 2311Document11 pagesSPLN Proc 2311yaofeiyu10No ratings yet
- Technical Answers For Real World Problems Digital Assignment 2Document7 pagesTechnical Answers For Real World Problems Digital Assignment 2Raj AryanNo ratings yet
- Xuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural NetworkDocument9 pagesXuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural Networkbigliang98No ratings yet
- Detectionof Cotton Plant DiseseDocument20 pagesDetectionof Cotton Plant DiseseAdarsh ChauhanNo ratings yet
- (Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Document12 pages(Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Aman JalanNo ratings yet
- Difference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceDocument14 pagesDifference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceShrivathsatv ShriNo ratings yet
- Yolo Fruit RipenessDocument18 pagesYolo Fruit RipenessAyush MishraNo ratings yet
- Face Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniDocument67 pagesFace Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniShruti DeshmukhNo ratings yet
- He Deep Residual Learning CVPR 2016 Paper PDFDocument9 pagesHe Deep Residual Learning CVPR 2016 Paper PDFVimarshNo ratings yet
- Ahmad Et Al. - 2023Document19 pagesAhmad Et Al. - 2023apatzNo ratings yet
- Shopee Code League 2021 Administrative Guide V1Document11 pagesShopee Code League 2021 Administrative Guide V1Arif PrayogaNo ratings yet
- Explaining How Resnet-50 Works and Why It Is So PopularDocument15 pagesExplaining How Resnet-50 Works and Why It Is So PopularAbhishek SanapNo ratings yet
- A Real-Time Collision Detection System For VehiclesDocument6 pagesA Real-Time Collision Detection System For VehiclesMayank LovanshiNo ratings yet
- The Art of Reinforcement Learning Michael Hu Full ChapterDocument67 pagesThe Art of Reinforcement Learning Michael Hu Full Chapterlillian.tirado682100% (8)
- Perbandingan Arsitektur Resnet50 Dan Resnet101 Dalam Klasifikasi Kanker Serviks Pada Citra Pap SmearDocument8 pagesPerbandingan Arsitektur Resnet50 Dan Resnet101 Dalam Klasifikasi Kanker Serviks Pada Citra Pap SmearJamil Al-idrusNo ratings yet
- Underwater Target Detection Algorithm Based On YOLO and Swin Transformer For Sonar ImagesDocument7 pagesUnderwater Target Detection Algorithm Based On YOLO and Swin Transformer For Sonar Imagesdeshmukhneha833No ratings yet
- 17 J MST 88 2023 131 138 1671Document8 pages17 J MST 88 2023 131 138 1671k3proNo ratings yet
- Mask RCNNDocument6 pagesMask RCNNsudhanshu2198No ratings yet
- A Survey and Performance Evaluation of Deep Learning Methods For Small 2021Document14 pagesA Survey and Performance Evaluation of Deep Learning Methods For Small 2021sadeqNo ratings yet































































































Download as pptx, pdf, or txt
You might also like
- ML Interview Cheat SheetDocument9 pagesML Interview Cheat Sheetwing444No ratings yet
- CNN Architectures-Stanford-Small SizeDocument95 pagesCNN Architectures-Stanford-Small SizeZee IngameNo ratings yet
- cs231n 2018 Lecture09Document106 pagescs231n 2018 Lecture09Đào TiênNo ratings yet
- 5b DanaDocument67 pages5b Dana22 / Gyanaranjan NayakNo ratings yet
- CS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDocument167 pagesCS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDEEP ROYNo ratings yet
- 09 ConvNet ArchitecturesDocument86 pages09 ConvNet ArchitecturesalokNo ratings yet
- Aidl 2023s DL 08 CNN ArchitecturesDocument51 pagesAidl 2023s DL 08 CNN ArchitecturesOuriNo ratings yet
- Convolutional NetworksDocument211 pagesConvolutional NetworksiamrishitagangulyNo ratings yet
- Alex NetDocument11 pagesAlex NetMackrish MalikNo ratings yet
- CNN Architectures - Transfer LearningDocument64 pagesCNN Architectures - Transfer LearningBaraniNo ratings yet
- CNN For Computer Vision Problem (Session 1)Document43 pagesCNN For Computer Vision Problem (Session 1)haryantoNo ratings yet
- Cesar Lcpcv5 Tutorial12 v11 GBDocument24 pagesCesar Lcpcv5 Tutorial12 v11 GBJasmin AgriNo ratings yet
- DSE 3151 25 Sep 2023Document9 pagesDSE 3151 25 Sep 2023KaiNo ratings yet
- VGG and ResnetDocument18 pagesVGG and Resnetsaisivani.ashok2021No ratings yet
- Tutorial On DNN 02 Popular DNNs DatasetsDocument60 pagesTutorial On DNN 02 Popular DNNs DatasetsSrikanthNo ratings yet
- Imp.-Image Category Classification Using Deep Learning-MATLABDocument9 pagesImp.-Image Category Classification Using Deep Learning-MATLABMirceaNo ratings yet
- Module3 CasestudyDocument13 pagesModule3 CasestudyDevarenjini PNo ratings yet
- Lenet 5Document14 pagesLenet 5Sathwik ChandraNo ratings yet
- Mobilenet SSDv2An Improved Object Detection Model For Embedded SystemsDocument5 pagesMobilenet SSDv2An Improved Object Detection Model For Embedded Systemsputra mulia rizky selianNo ratings yet
- Accelerating CFD Simulations With Gpus: Patrice CastonguayDocument67 pagesAccelerating CFD Simulations With Gpus: Patrice CastonguayastudespusNo ratings yet
- Transfer Learning - Part 1Document16 pagesTransfer Learning - Part 1AditiNo ratings yet
- DNN ArchitecturesDocument12 pagesDNN Architecturesshreyagoudar06No ratings yet
- Convolution Neural Network: CP - 6 Machine Learning M S PrasadDocument28 pagesConvolution Neural Network: CP - 6 Machine Learning M S PrasadM S PrasadNo ratings yet
- Lecture11 - CNN ArchitecturesDocument129 pagesLecture11 - CNN ArchitecturesCariza DiasNo ratings yet
- Convolutional Neural Networks-Part2Document21 pagesConvolutional Neural Networks-Part2polinati.vinesh2023No ratings yet
- Data Science Interview Preparation (#DAY 14)Document11 pagesData Science Interview Preparation (#DAY 14)ARPAN MAITYNo ratings yet
- Mi Lecture KX Part 1Document38 pagesMi Lecture KX Part 1Sejal KaleNo ratings yet
- Carbon Nanotube Computing: Subhasish Mitra Collaborator: H.-S. Philip WongDocument50 pagesCarbon Nanotube Computing: Subhasish Mitra Collaborator: H.-S. Philip WongnanoteraCHNo ratings yet
- Lecture 6 CNN - DetectionDocument48 pagesLecture 6 CNN - DetectionAbdou AbdelaliNo ratings yet
- NN 07Document24 pagesNN 07youssef husseinNo ratings yet
- Architecture HandbookDocument19 pagesArchitecture HandbookAnonymous fqvjeG008BNo ratings yet
- Literature Review On Image Classification ArchitectureDocument14 pagesLiterature Review On Image Classification ArchitectureMahiNo ratings yet
- ENGG1015 Tutorial 5 HandoutDocument8 pagesENGG1015 Tutorial 5 HandoutAnonymous K4n797INo ratings yet
- Light Pipes For MatlabDocument113 pagesLight Pipes For MatlabHaripriya MuralikrishnanNo ratings yet
- Assignment 3Document5 pagesAssignment 3SaurabhNo ratings yet
- Convolution Neural Network: CP - 6 Machine Learning M S PrasadDocument37 pagesConvolution Neural Network: CP - 6 Machine Learning M S PrasadMani S Prasad100% (1)
- Sequential Monte Carlo Methods: A Survey: Elise ArnaudDocument43 pagesSequential Monte Carlo Methods: A Survey: Elise ArnaudneilwuNo ratings yet
- Deepirisnet: Deep Iris Representation With Applications in Iris Recognition and Cross-Sensor Iris RecognitionDocument5 pagesDeepirisnet: Deep Iris Representation With Applications in Iris Recognition and Cross-Sensor Iris RecognitionpedroNo ratings yet
- Lead CompensatorDocument13 pagesLead CompensatorMohammed MohsinNo ratings yet
- Convolutional Neural Network ReportDocument5 pagesConvolutional Neural Network ReportNatasha HanafiNo ratings yet
- Fast Fourier Transform: VLSI Architectures: Vladimir StojanovićDocument26 pagesFast Fourier Transform: VLSI Architectures: Vladimir StojanovićTharun ThampanNo ratings yet
- Lecture 3Document12 pagesLecture 3aly869556No ratings yet
- Lab 6: Quality of Service: DCNI-2Document20 pagesLab 6: Quality of Service: DCNI-2h3d0nistNo ratings yet
- a-GIST CNNs Quicksummary HyungukDocument25 pagesa-GIST CNNs Quicksummary Hyunguk최희욱No ratings yet
- CNN IitkgpDocument112 pagesCNN Iitkgpamrutamhetre9No ratings yet
- HYPERMESHDocument19 pagesHYPERMESHSharan AnnapuraNo ratings yet
- Hardware Accelerated Convolutional Neural Networks For Synthetic Vision SystemsDocument4 pagesHardware Accelerated Convolutional Neural Networks For Synthetic Vision Systemsddatdh1No ratings yet
- Apprentissage Automatique Et Apprentissage Profond: Réseaux de Neurones Profonds (Deep Neural Network)Document20 pagesApprentissage Automatique Et Apprentissage Profond: Réseaux de Neurones Profonds (Deep Neural Network)MehdiNo ratings yet
- Pattern Classification Using Simplified Neural Networks With Pruning AlgorithmDocument7 pagesPattern Classification Using Simplified Neural Networks With Pruning AlgorithmThái SơnNo ratings yet
- Video Processing Communications Yao Wang Chapter6bDocument32 pagesVideo Processing Communications Yao Wang Chapter6bAshoka VanjareNo ratings yet
- Week 7 - Network FlowDocument47 pagesWeek 7 - Network FlowHaris AhmedNo ratings yet
- DSE 5251 Insem1 SchemeDocument8 pagesDSE 5251 Insem1 SchemeBalathrinath ReddyNo ratings yet
- Imp Questions For Ci - UpdateDocument8 pagesImp Questions For Ci - Updaterajeshwari64.yNo ratings yet
- Introduction To Management Science: Session 13Document26 pagesIntroduction To Management Science: Session 13Haris AliNo ratings yet
- Motion Estimtion and Motion Compensated (Video) CodingDocument41 pagesMotion Estimtion and Motion Compensated (Video) CodingPravin MuliyashiyaNo ratings yet
- hw2Document2 pageshw2RavindraSamriaNo ratings yet
- CNN 22mar2017Document110 pagesCNN 22mar2017Rahul AryanNo ratings yet
- Video Coding (VC-1)Document35 pagesVideo Coding (VC-1)Kholidiyah Masykuroh YusufNo ratings yet
- Digital Mobile Communications and the TETRA SystemFrom EverandDigital Mobile Communications and the TETRA SystemRating: 5 out of 5 stars5/5 (1)
- Regression and Regularization V4.1Document48 pagesRegression and Regularization V4.1Eman zakriaNo ratings yet
- Introduction To: Support Vector MachinesDocument53 pagesIntroduction To: Support Vector MachinesEman zakriaNo ratings yet
- Face Detection and Recognition 2019Document20 pagesFace Detection and Recognition 2019Eman zakriaNo ratings yet
- Verification CVSDocument97 pagesVerification CVSEman zakriaNo ratings yet
- Lec7 OOPDocument31 pagesLec7 OOPEman zakriaNo ratings yet
- Types of TestBench and Fork JoinDocument46 pagesTypes of TestBench and Fork JoinEman zakriaNo ratings yet
- VerifyDocument44 pagesVerifyEman zakriaNo ratings yet
- Real-Time Human Tracking Using Multi-Features Visual With CNN-LSTM and Q-LearningDocument15 pagesReal-Time Human Tracking Using Multi-Features Visual With CNN-LSTM and Q-LearningEDARA KEERTHI LAHARINo ratings yet
- A Hybrid Analysis-Based Approach To Android Malware Family ClassificationDocument23 pagesA Hybrid Analysis-Based Approach To Android Malware Family ClassificationDanh Nguyễn CôngNo ratings yet
- L10 - Intro - To - Deep - LearningDocument75 pagesL10 - Intro - To - Deep - LearningNALE SVPMEnggNo ratings yet
- Asian Face Recognition Improving Robustness and Performance Using YOLODocument5 pagesAsian Face Recognition Improving Robustness and Performance Using YOLOmohamed aliNo ratings yet
- 50 Most Important CNN Interview QuestionsDocument18 pages50 Most Important CNN Interview QuestionsDeepak KumarNo ratings yet
- Iceberg Ship Classification of Satellite Radar ImagesDocument25 pagesIceberg Ship Classification of Satellite Radar ImagesKaran UpareNo ratings yet
- Facial Recognition of Cattle Based On SK-ResNetDocument10 pagesFacial Recognition of Cattle Based On SK-ResNetWaleed AhmedNo ratings yet
- Res Net 2Document40 pagesRes Net 2jaffar bikatNo ratings yet
- Age Group and Gender Estimation in The Wild With Deep Ror ArchitectureDocument11 pagesAge Group and Gender Estimation in The Wild With Deep Ror ArchitectureAnil Kumar BNo ratings yet
- Pus Algebraic Statistics Volume 13 Issue 3Document12 pagesPus Algebraic Statistics Volume 13 Issue 3TefeNo ratings yet
- SPLN Proc 2311Document11 pagesSPLN Proc 2311yaofeiyu10No ratings yet
- Technical Answers For Real World Problems Digital Assignment 2Document7 pagesTechnical Answers For Real World Problems Digital Assignment 2Raj AryanNo ratings yet
- Xuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural NetworkDocument9 pagesXuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural Networkbigliang98No ratings yet
- Detectionof Cotton Plant DiseseDocument20 pagesDetectionof Cotton Plant DiseseAdarsh ChauhanNo ratings yet
- (Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Document12 pages(Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Aman JalanNo ratings yet
- Difference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceDocument14 pagesDifference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceShrivathsatv ShriNo ratings yet
- Yolo Fruit RipenessDocument18 pagesYolo Fruit RipenessAyush MishraNo ratings yet
- Face Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniDocument67 pagesFace Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniShruti DeshmukhNo ratings yet
- He Deep Residual Learning CVPR 2016 Paper PDFDocument9 pagesHe Deep Residual Learning CVPR 2016 Paper PDFVimarshNo ratings yet
- Ahmad Et Al. - 2023Document19 pagesAhmad Et Al. - 2023apatzNo ratings yet
- Shopee Code League 2021 Administrative Guide V1Document11 pagesShopee Code League 2021 Administrative Guide V1Arif PrayogaNo ratings yet
- Explaining How Resnet-50 Works and Why It Is So PopularDocument15 pagesExplaining How Resnet-50 Works and Why It Is So PopularAbhishek SanapNo ratings yet
- A Real-Time Collision Detection System For VehiclesDocument6 pagesA Real-Time Collision Detection System For VehiclesMayank LovanshiNo ratings yet
- The Art of Reinforcement Learning Michael Hu Full ChapterDocument67 pagesThe Art of Reinforcement Learning Michael Hu Full Chapterlillian.tirado682100% (8)
- Perbandingan Arsitektur Resnet50 Dan Resnet101 Dalam Klasifikasi Kanker Serviks Pada Citra Pap SmearDocument8 pagesPerbandingan Arsitektur Resnet50 Dan Resnet101 Dalam Klasifikasi Kanker Serviks Pada Citra Pap SmearJamil Al-idrusNo ratings yet
- Underwater Target Detection Algorithm Based On YOLO and Swin Transformer For Sonar ImagesDocument7 pagesUnderwater Target Detection Algorithm Based On YOLO and Swin Transformer For Sonar Imagesdeshmukhneha833No ratings yet
- 17 J MST 88 2023 131 138 1671Document8 pages17 J MST 88 2023 131 138 1671k3proNo ratings yet
- Mask RCNNDocument6 pagesMask RCNNsudhanshu2198No ratings yet
- A Survey and Performance Evaluation of Deep Learning Methods For Small 2021Document14 pagesA Survey and Performance Evaluation of Deep Learning Methods For Small 2021sadeqNo ratings yet