
Wykład 1
Wykład 1
You might also like
- Statystyka Opisowa W Zadaniach PDFDocument159 pagesStatystyka Opisowa W Zadaniach PDFKasia KulkaNo ratings yet
- Semestr1 TeoriaDocument17 pagesSemestr1 TeoriarfksNo ratings yet
- Jermakowicz 24032024144219 Statystyka 2Document41 pagesJermakowicz 24032024144219 Statystyka 2ewa kedzioraNo ratings yet
- Statystyka WykładyDocument17 pagesStatystyka WykładyAnna KośmiderNo ratings yet
- EstymacjaDocument25 pagesEstymacjaBarbara KowalczykNo ratings yet
- Wyk. - Wprowadzenie Do Analizy Danych SpołecznychDocument5 pagesWyk. - Wprowadzenie Do Analizy Danych SpołecznychMarta KramerNo ratings yet
- StatystykaDocument55 pagesStatystykaRNiNo ratings yet
- STAT - OPIS - ĆW 12 NewDocument8 pagesSTAT - OPIS - ĆW 12 NewPatryk ObrębskiNo ratings yet
- Metodologia Badań Ze StatystykaDocument12 pagesMetodologia Badań Ze StatystykaDominika XNo ratings yet
- StatystykaDocument10 pagesStatystykadominika siemkowiczNo ratings yet
- Statystyka Matematyczna 2023 2024Document56 pagesStatystyka Matematyczna 2023 2024dziarczykowskaNo ratings yet
- Statystyka - NotatkiDocument6 pagesStatystyka - NotatkiIza GrzebakNo ratings yet
- EstymacjaDocument32 pagesEstymacjaNadia DanylickaNo ratings yet
- III Miary RozproszeniaDocument8 pagesIII Miary RozproszeniaKAROLINANo ratings yet
- PodstawyDocument10 pagesPodstawyjuliaNo ratings yet
- Problem BadawczyDocument9 pagesProblem BadawczyJulia DrosińskaNo ratings yet
- Analiza DyskryminacyjnaDocument13 pagesAnaliza DyskryminacyjnaBobiOneeNo ratings yet
- Laboratorium 4 Statystyka StatisticaDocument16 pagesLaboratorium 4 Statystyka StatisticaPipek PipekejNo ratings yet
- Wyklad SMDocument120 pagesWyklad SMJoanna ZwierzyckaNo ratings yet
- Wyklad 10 Elementy Statysytki OpisowejDocument18 pagesWyklad 10 Elementy Statysytki OpisowejAneta WróblewskaNo ratings yet
- Teoria-Statystyka MatematycznaDocument19 pagesTeoria-Statystyka Matematycznakrzysiu101No ratings yet
- Statystyka Opisowa (18 Stron)Document19 pagesStatystyka Opisowa (18 Stron)MJLovettNo ratings yet
- Statystyka Wykłady OpisDocument13 pagesStatystyka Wykłady OpisAnna KośmiderNo ratings yet
- Stat 1 BiałyDocument14 pagesStat 1 BiałyAdrian WodaraNo ratings yet
- Mateusz Zięba - Biostatyka Temat 2Document18 pagesMateusz Zięba - Biostatyka Temat 2Mateusz ZiębaNo ratings yet
- Statystyka PodstawyDocument27 pagesStatystyka PodstawyDawid PękałaNo ratings yet
- Nieparametryczne Odpowiedniki Testów StatystycznychDocument4 pagesNieparametryczne Odpowiedniki Testów StatystycznychMaciek GrzegorczykNo ratings yet
- Podstawy Metodologii Badan Psychologicznych Cwiczenia 2Document53 pagesPodstawy Metodologii Badan Psychologicznych Cwiczenia 2Piotr BińczykNo ratings yet
- METODA REPREZENTACYJNA DrukDocument5 pagesMETODA REPREZENTACYJNA DrukOla GorskaNo ratings yet
- Estymacja - Materiały Do ĆwiczeńDocument6 pagesEstymacja - Materiały Do ĆwiczeńFilipNo ratings yet
- Statystyka Opisowa (Prezentacja)Document123 pagesStatystyka Opisowa (Prezentacja)nowyflauerNo ratings yet
- Statystyka Opisowa 1Document47 pagesStatystyka Opisowa 1Marcelina ŁobodaNo ratings yet
- Statytyka MateriałyDocument29 pagesStatytyka Materiałyjuliakunaszyk44No ratings yet
- Ćwiczenia 5Document5 pagesĆwiczenia 5Patryk ObrębskiNo ratings yet
- Rozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieDocument9 pagesRozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieOlaNo ratings yet
- Ekonometria - Wyklad - 2 - 2020Document26 pagesEkonometria - Wyklad - 2 - 2020Patryk ObrębskiNo ratings yet
- Lab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychDocument10 pagesLab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychYehor MalakhovNo ratings yet
- Zasoby Wykład 1Document15 pagesZasoby Wykład 1OlaNo ratings yet
- STAT - Wprowadzanie Danych - 2Document24 pagesSTAT - Wprowadzanie Danych - 2Natalia WróbelNo ratings yet
- Statystyka PracaDocument26 pagesStatystyka PracaDagmara OwocNo ratings yet
- Wykład 2SDocument8 pagesWykład 2Serykowca2004No ratings yet
- 2 PowtarzanepomiaryDocument81 pages2 PowtarzanepomiaryJulia OrłowskaNo ratings yet
- Statystyka Opisowa TeoriaDocument11 pagesStatystyka Opisowa TeoriaMarcelina ŁobodaNo ratings yet
- Jermakowicz 05042024110036 Statystyka 4Document41 pagesJermakowicz 05042024110036 Statystyka 4ewa kedzioraNo ratings yet
- Lab. 2 - Błędy Pomiarowe W Pomiarach BezpośrednichDocument17 pagesLab. 2 - Błędy Pomiarowe W Pomiarach BezpośrednichYehor MalakhovNo ratings yet
- 2023 01 Statystyki Opisowe I Normalnosc RozkladuDocument3 pages2023 01 Statystyki Opisowe I Normalnosc RozkladuJustyna WcisłoNo ratings yet
- MetodologiaDocument20 pagesMetodologiaAsia SzmyłaNo ratings yet
- Testowanie Fkcji Decyzyjnej AlgorDocument22 pagesTestowanie Fkcji Decyzyjnej AlgorjolygeekNo ratings yet
- Combining ClassifiersDocument22 pagesCombining ClassifiersMichal SiemaszkiewiczNo ratings yet
- Statystyka OpisowaDocument81 pagesStatystyka OpisowaVonTorettoNo ratings yet
- Zagadnienie nr3Document22 pagesZagadnienie nr3rinamarua13No ratings yet
- Final Boss StatystykaDocument18 pagesFinal Boss Statystykakncfzz4rcjNo ratings yet
- Labfizcw 1Document17 pagesLabfizcw 1Fordon FordonNo ratings yet
- BMS23 24C5Document63 pagesBMS23 24C5julkaswiech04No ratings yet
- Projekt Informatyczny IiE - w4Document37 pagesProjekt Informatyczny IiE - w4klooc klooc (klocuu)No ratings yet
- Podstawy Metodologii I StatystykiDocument10 pagesPodstawy Metodologii I StatystykiBarbara StafiniakNo ratings yet
- Egz 2012 IIIDocument4 pagesEgz 2012 IIIAndré KuczaraNo ratings yet
- Uczenie NadzorowaneDocument24 pagesUczenie NadzorowaneJoanna ŻabińskaNo ratings yet
- AzotDocument4 pagesAzotFilipNo ratings yet
- Wyniki Watpliwe - DaneDocument2 pagesWyniki Watpliwe - DaneFilipNo ratings yet
- Wyniki Watpliwe - ZadaniaDocument1 pageWyniki Watpliwe - ZadaniaFilipNo ratings yet
- Odnowa Wody RemixDocument5 pagesOdnowa Wody RemixFilipNo ratings yet

















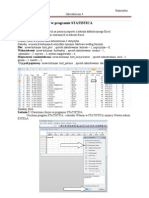












































Download as ppt, pdf, or txt
You might also like
- Statystyka Opisowa W Zadaniach PDFDocument159 pagesStatystyka Opisowa W Zadaniach PDFKasia KulkaNo ratings yet
- Semestr1 TeoriaDocument17 pagesSemestr1 TeoriarfksNo ratings yet
- Jermakowicz 24032024144219 Statystyka 2Document41 pagesJermakowicz 24032024144219 Statystyka 2ewa kedzioraNo ratings yet
- Statystyka WykładyDocument17 pagesStatystyka WykładyAnna KośmiderNo ratings yet
- EstymacjaDocument25 pagesEstymacjaBarbara KowalczykNo ratings yet
- Wyk. - Wprowadzenie Do Analizy Danych SpołecznychDocument5 pagesWyk. - Wprowadzenie Do Analizy Danych SpołecznychMarta KramerNo ratings yet
- StatystykaDocument55 pagesStatystykaRNiNo ratings yet
- STAT - OPIS - ĆW 12 NewDocument8 pagesSTAT - OPIS - ĆW 12 NewPatryk ObrębskiNo ratings yet
- Metodologia Badań Ze StatystykaDocument12 pagesMetodologia Badań Ze StatystykaDominika XNo ratings yet
- StatystykaDocument10 pagesStatystykadominika siemkowiczNo ratings yet
- Statystyka Matematyczna 2023 2024Document56 pagesStatystyka Matematyczna 2023 2024dziarczykowskaNo ratings yet
- Statystyka - NotatkiDocument6 pagesStatystyka - NotatkiIza GrzebakNo ratings yet
- EstymacjaDocument32 pagesEstymacjaNadia DanylickaNo ratings yet
- III Miary RozproszeniaDocument8 pagesIII Miary RozproszeniaKAROLINANo ratings yet
- PodstawyDocument10 pagesPodstawyjuliaNo ratings yet
- Problem BadawczyDocument9 pagesProblem BadawczyJulia DrosińskaNo ratings yet
- Analiza DyskryminacyjnaDocument13 pagesAnaliza DyskryminacyjnaBobiOneeNo ratings yet
- Laboratorium 4 Statystyka StatisticaDocument16 pagesLaboratorium 4 Statystyka StatisticaPipek PipekejNo ratings yet
- Wyklad SMDocument120 pagesWyklad SMJoanna ZwierzyckaNo ratings yet
- Wyklad 10 Elementy Statysytki OpisowejDocument18 pagesWyklad 10 Elementy Statysytki OpisowejAneta WróblewskaNo ratings yet
- Teoria-Statystyka MatematycznaDocument19 pagesTeoria-Statystyka Matematycznakrzysiu101No ratings yet
- Statystyka Opisowa (18 Stron)Document19 pagesStatystyka Opisowa (18 Stron)MJLovettNo ratings yet
- Statystyka Wykłady OpisDocument13 pagesStatystyka Wykłady OpisAnna KośmiderNo ratings yet
- Stat 1 BiałyDocument14 pagesStat 1 BiałyAdrian WodaraNo ratings yet
- Mateusz Zięba - Biostatyka Temat 2Document18 pagesMateusz Zięba - Biostatyka Temat 2Mateusz ZiębaNo ratings yet
- Statystyka PodstawyDocument27 pagesStatystyka PodstawyDawid PękałaNo ratings yet
- Nieparametryczne Odpowiedniki Testów StatystycznychDocument4 pagesNieparametryczne Odpowiedniki Testów StatystycznychMaciek GrzegorczykNo ratings yet
- Podstawy Metodologii Badan Psychologicznych Cwiczenia 2Document53 pagesPodstawy Metodologii Badan Psychologicznych Cwiczenia 2Piotr BińczykNo ratings yet
- METODA REPREZENTACYJNA DrukDocument5 pagesMETODA REPREZENTACYJNA DrukOla GorskaNo ratings yet
- Estymacja - Materiały Do ĆwiczeńDocument6 pagesEstymacja - Materiały Do ĆwiczeńFilipNo ratings yet
- Statystyka Opisowa (Prezentacja)Document123 pagesStatystyka Opisowa (Prezentacja)nowyflauerNo ratings yet
- Statystyka Opisowa 1Document47 pagesStatystyka Opisowa 1Marcelina ŁobodaNo ratings yet
- Statytyka MateriałyDocument29 pagesStatytyka Materiałyjuliakunaszyk44No ratings yet
- Ćwiczenia 5Document5 pagesĆwiczenia 5Patryk ObrębskiNo ratings yet
- Rozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieDocument9 pagesRozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieOlaNo ratings yet
- Ekonometria - Wyklad - 2 - 2020Document26 pagesEkonometria - Wyklad - 2 - 2020Patryk ObrębskiNo ratings yet
- Lab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychDocument10 pagesLab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychYehor MalakhovNo ratings yet
- Zasoby Wykład 1Document15 pagesZasoby Wykład 1OlaNo ratings yet
- STAT - Wprowadzanie Danych - 2Document24 pagesSTAT - Wprowadzanie Danych - 2Natalia WróbelNo ratings yet
- Statystyka PracaDocument26 pagesStatystyka PracaDagmara OwocNo ratings yet
- Wykład 2SDocument8 pagesWykład 2Serykowca2004No ratings yet
- 2 PowtarzanepomiaryDocument81 pages2 PowtarzanepomiaryJulia OrłowskaNo ratings yet
- Statystyka Opisowa TeoriaDocument11 pagesStatystyka Opisowa TeoriaMarcelina ŁobodaNo ratings yet
- Jermakowicz 05042024110036 Statystyka 4Document41 pagesJermakowicz 05042024110036 Statystyka 4ewa kedzioraNo ratings yet
- Lab. 2 - Błędy Pomiarowe W Pomiarach BezpośrednichDocument17 pagesLab. 2 - Błędy Pomiarowe W Pomiarach BezpośrednichYehor MalakhovNo ratings yet
- 2023 01 Statystyki Opisowe I Normalnosc RozkladuDocument3 pages2023 01 Statystyki Opisowe I Normalnosc RozkladuJustyna WcisłoNo ratings yet
- MetodologiaDocument20 pagesMetodologiaAsia SzmyłaNo ratings yet
- Testowanie Fkcji Decyzyjnej AlgorDocument22 pagesTestowanie Fkcji Decyzyjnej AlgorjolygeekNo ratings yet
- Combining ClassifiersDocument22 pagesCombining ClassifiersMichal SiemaszkiewiczNo ratings yet
- Statystyka OpisowaDocument81 pagesStatystyka OpisowaVonTorettoNo ratings yet
- Zagadnienie nr3Document22 pagesZagadnienie nr3rinamarua13No ratings yet
- Final Boss StatystykaDocument18 pagesFinal Boss Statystykakncfzz4rcjNo ratings yet
- Labfizcw 1Document17 pagesLabfizcw 1Fordon FordonNo ratings yet
- BMS23 24C5Document63 pagesBMS23 24C5julkaswiech04No ratings yet
- Projekt Informatyczny IiE - w4Document37 pagesProjekt Informatyczny IiE - w4klooc klooc (klocuu)No ratings yet
- Podstawy Metodologii I StatystykiDocument10 pagesPodstawy Metodologii I StatystykiBarbara StafiniakNo ratings yet
- Egz 2012 IIIDocument4 pagesEgz 2012 IIIAndré KuczaraNo ratings yet
- Uczenie NadzorowaneDocument24 pagesUczenie NadzorowaneJoanna ŻabińskaNo ratings yet
- AzotDocument4 pagesAzotFilipNo ratings yet
- Wyniki Watpliwe - DaneDocument2 pagesWyniki Watpliwe - DaneFilipNo ratings yet
- Wyniki Watpliwe - ZadaniaDocument1 pageWyniki Watpliwe - ZadaniaFilipNo ratings yet
- Odnowa Wody RemixDocument5 pagesOdnowa Wody RemixFilipNo ratings yet