
Data Leakage Detection 123
Data Leakage Detection 123
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Hotel Reservation Android App ReportDocument27 pagesHotel Reservation Android App ReportdanielNo ratings yet
- 2 MasDocument29 pages2 MasVigneshInfotechNo ratings yet
- Numbers: 5 and 6 Digits: AnswersDocument37 pagesNumbers: 5 and 6 Digits: AnswersVigneshInfotechNo ratings yet
- CV SaberDocument3 pagesCV SaberVigneshInfotechNo ratings yet
- 1 EvsDocument30 pages1 EvsVigneshInfotechNo ratings yet
- An Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorDocument39 pagesAn Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorVigneshInfotechNo ratings yet
- 24-Mar-2019, CC, BZA - KZJDocument2 pages24-Mar-2019, CC, BZA - KZJVigneshInfotechNo ratings yet
- Date Employee Nam Accompanied by Visited Area School NameDocument4 pagesDate Employee Nam Accompanied by Visited Area School NameVigneshInfotechNo ratings yet
- 1 EngDocument32 pages1 EngVigneshInfotechNo ratings yet
- STUDENT Name:: Mundada Vinay Kumar EmailDocument2 pagesSTUDENT Name:: Mundada Vinay Kumar EmailVigneshInfotechNo ratings yet
- Implementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHDocument4 pagesImplementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHVigneshInfotechNo ratings yet
- Discrete Wavelet TransformDocument10 pagesDiscrete Wavelet TransformVigneshInfotechNo ratings yet
- Matlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'Document1 pageMatlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'VigneshInfotechNo ratings yet
- Project Documentation Guidelines - ECE - JITS2013Document4 pagesProject Documentation Guidelines - ECE - JITS2013VigneshInfotechNo ratings yet
- Title NO.: Acknowledgement List of FiguresDocument3 pagesTitle NO.: Acknowledgement List of FiguresVigneshInfotechNo ratings yet
- 2 Evs PDFDocument39 pages2 Evs PDFVigneshInfotechNo ratings yet
- Design of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsDocument3 pagesDesign of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsVigneshInfotechNo ratings yet
- Performance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MDocument5 pagesPerformance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MVigneshInfotechNo ratings yet
- Image Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorDocument13 pagesImage Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorVigneshInfotechNo ratings yet
- A New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmDocument8 pagesA New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmVigneshInfotechNo ratings yet
- High-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesDocument3 pagesHigh-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesVigneshInfotechNo ratings yet
- System DesignDocument6 pagesSystem DesignVigneshInfotechNo ratings yet
- Multi-Feature and Genetic AlgorithmDocument41 pagesMulti-Feature and Genetic AlgorithmVigneshInfotechNo ratings yet
- Inner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelDocument8 pagesInner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelVigneshInfotechNo ratings yet
- VTVL13 With ErrorDocument3 pagesVTVL13 With ErrorVigneshInfotechNo ratings yet
- Module DescriptionDocument1 pageModule DescriptionVigneshInfotechNo ratings yet
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument14 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument6 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- CA4101 Lecture 3 Business Architecture - BPMNDocument40 pagesCA4101 Lecture 3 Business Architecture - BPMNManoj VenkatNo ratings yet
- AM-929x Redundancy Control System PC-Software Manual: Amplus Communication Pte LTDDocument13 pagesAM-929x Redundancy Control System PC-Software Manual: Amplus Communication Pte LTDimbukhNo ratings yet
- dm00663511 How To Build A Simple Usbpd Sink Application With Stm32cubemx StmicroelectronicsDocument43 pagesdm00663511 How To Build A Simple Usbpd Sink Application With Stm32cubemx StmicroelectronicsBig BoyNo ratings yet
- Diat Certified Information Assurance Professional: An Online Training & Certification Programme byDocument4 pagesDiat Certified Information Assurance Professional: An Online Training & Certification Programme byV K BNo ratings yet
- 7.multi Threading NotesDocument16 pages7.multi Threading NotesrahulNo ratings yet
- D400 Configuration ManualDocument486 pagesD400 Configuration Manualmertoiu8658No ratings yet
- Environment For Efficient and Reusable SystemC Module Level VerificationDocument11 pagesEnvironment For Efficient and Reusable SystemC Module Level VerificationtarekmhamdiNo ratings yet
- Atualização Da IOS HP 3 COMDocument9 pagesAtualização Da IOS HP 3 COMHeimanton Guidine LopesNo ratings yet
- Cisco and WiresharkDocument8 pagesCisco and Wiresharkas7235740No ratings yet
- AWS Healthcare 19167008Document9 pagesAWS Healthcare 19167008rudy mythNo ratings yet
- Ai Prompt Templates TextDocument9 pagesAi Prompt Templates TextMaru BensusanNo ratings yet
- Laboratory 1 Sheet V5Document2 pagesLaboratory 1 Sheet V5Sahan KaushalyaNo ratings yet
- Function Module QR CodeDocument14 pagesFunction Module QR CodenstomarNo ratings yet
- Advance Steel 2020 Brochure enDocument4 pagesAdvance Steel 2020 Brochure enAyush KhannaNo ratings yet
- Submit For Assessment Administrative GuideDocument9 pagesSubmit For Assessment Administrative GuideNadia F. ZoppasNo ratings yet
- User Manual (EN)Document6 pagesUser Manual (EN)Juan Francisco Sanchez MassadiNo ratings yet
- System Analysis and Design: Fall 2021Document4 pagesSystem Analysis and Design: Fall 2021Ngọc TrâmNo ratings yet
- Datasheet M-Duino 38AR+ LoRaDocument5 pagesDatasheet M-Duino 38AR+ LoRaJuanFer AulesNo ratings yet
- Kuber Net EsDocument6 pagesKuber Net EsjayNo ratings yet
- Study Guide: NIST RMF: The BasicsDocument8 pagesStudy Guide: NIST RMF: The Basicsdisney007No ratings yet
- ASCII Art Generator - Online HD Color Image To Text ConverterDocument1 pageASCII Art Generator - Online HD Color Image To Text ConvertercitrusgarageNo ratings yet
- Vip SetpropDocument6 pagesVip Setproppipooyaii100% (1)
- UCBioBSP SDK Programmer's Guide v3.00 (Kor)Document346 pagesUCBioBSP SDK Programmer's Guide v3.00 (Kor)من لخبطهNo ratings yet
- Textbook Oracle Soa Suite 12C Handbook 1St Edition Jellema Ebook All Chapter PDFDocument53 pagesTextbook Oracle Soa Suite 12C Handbook 1St Edition Jellema Ebook All Chapter PDFlori.post940100% (9)
- CMP 466 Hci L1Document121 pagesCMP 466 Hci L1Joseph Daniel OchigaNo ratings yet
- Abap Programming For Sap Hana Ha400Document2 pagesAbap Programming For Sap Hana Ha400gaurav jainNo ratings yet
- دراسات قانونية - التزويرDocument34 pagesدراسات قانونية - التزويرal7usamNo ratings yet
- Dining Philosopher: ProblemDocument9 pagesDining Philosopher: ProblemAastha SinghNo ratings yet
- ReportDocument18 pagesReportial2000No ratings yet



















































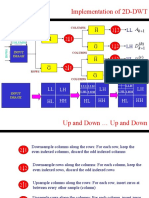












































Download as pptx, pdf, or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Hotel Reservation Android App ReportDocument27 pagesHotel Reservation Android App ReportdanielNo ratings yet
- 2 MasDocument29 pages2 MasVigneshInfotechNo ratings yet
- Numbers: 5 and 6 Digits: AnswersDocument37 pagesNumbers: 5 and 6 Digits: AnswersVigneshInfotechNo ratings yet
- CV SaberDocument3 pagesCV SaberVigneshInfotechNo ratings yet
- 1 EvsDocument30 pages1 EvsVigneshInfotechNo ratings yet
- An Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorDocument39 pagesAn Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorVigneshInfotechNo ratings yet
- 24-Mar-2019, CC, BZA - KZJDocument2 pages24-Mar-2019, CC, BZA - KZJVigneshInfotechNo ratings yet
- Date Employee Nam Accompanied by Visited Area School NameDocument4 pagesDate Employee Nam Accompanied by Visited Area School NameVigneshInfotechNo ratings yet
- 1 EngDocument32 pages1 EngVigneshInfotechNo ratings yet
- STUDENT Name:: Mundada Vinay Kumar EmailDocument2 pagesSTUDENT Name:: Mundada Vinay Kumar EmailVigneshInfotechNo ratings yet
- Implementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHDocument4 pagesImplementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHVigneshInfotechNo ratings yet
- Discrete Wavelet TransformDocument10 pagesDiscrete Wavelet TransformVigneshInfotechNo ratings yet
- Matlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'Document1 pageMatlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'VigneshInfotechNo ratings yet
- Project Documentation Guidelines - ECE - JITS2013Document4 pagesProject Documentation Guidelines - ECE - JITS2013VigneshInfotechNo ratings yet
- Title NO.: Acknowledgement List of FiguresDocument3 pagesTitle NO.: Acknowledgement List of FiguresVigneshInfotechNo ratings yet
- 2 Evs PDFDocument39 pages2 Evs PDFVigneshInfotechNo ratings yet
- Design of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsDocument3 pagesDesign of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsVigneshInfotechNo ratings yet
- Performance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MDocument5 pagesPerformance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MVigneshInfotechNo ratings yet
- Image Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorDocument13 pagesImage Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorVigneshInfotechNo ratings yet
- A New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmDocument8 pagesA New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmVigneshInfotechNo ratings yet
- High-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesDocument3 pagesHigh-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesVigneshInfotechNo ratings yet
- System DesignDocument6 pagesSystem DesignVigneshInfotechNo ratings yet
- Multi-Feature and Genetic AlgorithmDocument41 pagesMulti-Feature and Genetic AlgorithmVigneshInfotechNo ratings yet
- Inner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelDocument8 pagesInner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelVigneshInfotechNo ratings yet
- VTVL13 With ErrorDocument3 pagesVTVL13 With ErrorVigneshInfotechNo ratings yet
- Module DescriptionDocument1 pageModule DescriptionVigneshInfotechNo ratings yet
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument14 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument6 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- CA4101 Lecture 3 Business Architecture - BPMNDocument40 pagesCA4101 Lecture 3 Business Architecture - BPMNManoj VenkatNo ratings yet
- AM-929x Redundancy Control System PC-Software Manual: Amplus Communication Pte LTDDocument13 pagesAM-929x Redundancy Control System PC-Software Manual: Amplus Communication Pte LTDimbukhNo ratings yet
- dm00663511 How To Build A Simple Usbpd Sink Application With Stm32cubemx StmicroelectronicsDocument43 pagesdm00663511 How To Build A Simple Usbpd Sink Application With Stm32cubemx StmicroelectronicsBig BoyNo ratings yet
- Diat Certified Information Assurance Professional: An Online Training & Certification Programme byDocument4 pagesDiat Certified Information Assurance Professional: An Online Training & Certification Programme byV K BNo ratings yet
- 7.multi Threading NotesDocument16 pages7.multi Threading NotesrahulNo ratings yet
- D400 Configuration ManualDocument486 pagesD400 Configuration Manualmertoiu8658No ratings yet
- Environment For Efficient and Reusable SystemC Module Level VerificationDocument11 pagesEnvironment For Efficient and Reusable SystemC Module Level VerificationtarekmhamdiNo ratings yet
- Atualização Da IOS HP 3 COMDocument9 pagesAtualização Da IOS HP 3 COMHeimanton Guidine LopesNo ratings yet
- Cisco and WiresharkDocument8 pagesCisco and Wiresharkas7235740No ratings yet
- AWS Healthcare 19167008Document9 pagesAWS Healthcare 19167008rudy mythNo ratings yet
- Ai Prompt Templates TextDocument9 pagesAi Prompt Templates TextMaru BensusanNo ratings yet
- Laboratory 1 Sheet V5Document2 pagesLaboratory 1 Sheet V5Sahan KaushalyaNo ratings yet
- Function Module QR CodeDocument14 pagesFunction Module QR CodenstomarNo ratings yet
- Advance Steel 2020 Brochure enDocument4 pagesAdvance Steel 2020 Brochure enAyush KhannaNo ratings yet
- Submit For Assessment Administrative GuideDocument9 pagesSubmit For Assessment Administrative GuideNadia F. ZoppasNo ratings yet
- User Manual (EN)Document6 pagesUser Manual (EN)Juan Francisco Sanchez MassadiNo ratings yet
- System Analysis and Design: Fall 2021Document4 pagesSystem Analysis and Design: Fall 2021Ngọc TrâmNo ratings yet
- Datasheet M-Duino 38AR+ LoRaDocument5 pagesDatasheet M-Duino 38AR+ LoRaJuanFer AulesNo ratings yet
- Kuber Net EsDocument6 pagesKuber Net EsjayNo ratings yet
- Study Guide: NIST RMF: The BasicsDocument8 pagesStudy Guide: NIST RMF: The Basicsdisney007No ratings yet
- ASCII Art Generator - Online HD Color Image To Text ConverterDocument1 pageASCII Art Generator - Online HD Color Image To Text ConvertercitrusgarageNo ratings yet
- Vip SetpropDocument6 pagesVip Setproppipooyaii100% (1)
- UCBioBSP SDK Programmer's Guide v3.00 (Kor)Document346 pagesUCBioBSP SDK Programmer's Guide v3.00 (Kor)من لخبطهNo ratings yet
- Textbook Oracle Soa Suite 12C Handbook 1St Edition Jellema Ebook All Chapter PDFDocument53 pagesTextbook Oracle Soa Suite 12C Handbook 1St Edition Jellema Ebook All Chapter PDFlori.post940100% (9)
- CMP 466 Hci L1Document121 pagesCMP 466 Hci L1Joseph Daniel OchigaNo ratings yet
- Abap Programming For Sap Hana Ha400Document2 pagesAbap Programming For Sap Hana Ha400gaurav jainNo ratings yet
- دراسات قانونية - التزويرDocument34 pagesدراسات قانونية - التزويرal7usamNo ratings yet
- Dining Philosopher: ProblemDocument9 pagesDining Philosopher: ProblemAastha SinghNo ratings yet
- ReportDocument18 pagesReportial2000No ratings yet