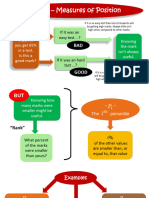
Download as pptx, pdf, or txt
You might also like
- Gender-Responsive Lgu (Gerl) Assessment ToolDocument42 pagesGender-Responsive Lgu (Gerl) Assessment ToolDyanne Kristine Almirante Sideño100% (8)
- Returns To Education: Chapter 1: Defining and Collecting DataDocument13 pagesReturns To Education: Chapter 1: Defining and Collecting DataTyler 2k1100% (1)
- The Bidirectional Movement of The Frontalis Muscle: Introducing The Line of Convergence and Its Potential Clinical RelevanceDocument8 pagesThe Bidirectional Movement of The Frontalis Muscle: Introducing The Line of Convergence and Its Potential Clinical RelevanceBruna RochaNo ratings yet
- Basic Statistics Terms and CalculationsDocument4 pagesBasic Statistics Terms and CalculationsSagir Musa SaniNo ratings yet
- STK110 Chapter 7Document57 pagesSTK110 Chapter 7Londiwe MsimangoNo ratings yet
- Sampling Distribution and EstimationDocument46 pagesSampling Distribution and EstimationPrinceNo ratings yet
- 03 Statistical & Internal ValidityDocument58 pages03 Statistical & Internal ValidityAssan AchibatNo ratings yet
- Lesson 2: Parameter and Statistic: Sampling and Sampling DistributionDocument6 pagesLesson 2: Parameter and Statistic: Sampling and Sampling DistributionNikki AlquinoNo ratings yet
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- Statprob Finals 4THDocument8 pagesStatprob Finals 4THJuswa MagtanggolNo ratings yet
- Statistical Methodology Step of Scientific Research Important Parametric Tests Important Nonparametric Tests Example Using Excel Program Using Excel For Statistics in Gateway Cases - Office 2007Document42 pagesStatistical Methodology Step of Scientific Research Important Parametric Tests Important Nonparametric Tests Example Using Excel Program Using Excel For Statistics in Gateway Cases - Office 2007Rodjan MoscosoNo ratings yet
- CombinepdfDocument2 pagesCombinepdfgaming accountNo ratings yet
- Chapter Two - Estimation (STA408)Document46 pagesChapter Two - Estimation (STA408)BadnazNo ratings yet
- Mean, Median, Mode, Variance & Standard Deviation: Subject: Statistics Created By: Marija Stanojcic Revised: 10/9/2018Document3 pagesMean, Median, Mode, Variance & Standard Deviation: Subject: Statistics Created By: Marija Stanojcic Revised: 10/9/2018samuel mechNo ratings yet
- 2 Central TendencyDocument36 pages2 Central TendencyJuhi Vaswani0% (1)
- AP ECON 2500 Session 2Document22 pagesAP ECON 2500 Session 2Thuỳ DungNo ratings yet
- Stats Cheat Sheet (Size 11)Document5 pagesStats Cheat Sheet (Size 11)HongHaNguyenNo ratings yet
- Data Notes For IN3Document66 pagesData Notes For IN3Lyse NdifoNo ratings yet
- Ecological Statistics Review: Sampling StrategiesDocument14 pagesEcological Statistics Review: Sampling StrategiesMATHIXNo ratings yet
- Unit 1: Measures of Central Tendency: Module 6: Descriptive Statistical MeasuresDocument10 pagesUnit 1: Measures of Central Tendency: Module 6: Descriptive Statistical MeasuresABAGAEL CACHONo ratings yet
- Chapter 5 EstimationDocument17 pagesChapter 5 EstimationYolanda DescallarNo ratings yet
- Q4 Math 7 Week 6Document8 pagesQ4 Math 7 Week 6JEWEL LUCKY LYN GUINTONo ratings yet
- CQE Academy Equation Cheat Sheet - DDocument15 pagesCQE Academy Equation Cheat Sheet - DAmr AlShenawyNo ratings yet
- Math2101Stat 1Document8 pagesMath2101Stat 1iamtawhidhassanNo ratings yet
- Lecture 10Document13 pagesLecture 10YashikaNo ratings yet
- Sec 2.8 - 2021Document20 pagesSec 2.8 - 2021sthembisoandile059No ratings yet
- Statistics Midterm ReviewDocument21 pagesStatistics Midterm ReviewMai NguyenNo ratings yet
- WK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadDocument12 pagesWK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadLIAW ANN YINo ratings yet
- View PDFDocument48 pagesView PDFone and only channelNo ratings yet
- Statistics en Phase I 11th NotesDocument48 pagesStatistics en Phase I 11th NotesDR.TARIQ AHMADNo ratings yet
- Statistics Help Card FormulasDocument3 pagesStatistics Help Card Formulas2tzf9tqpfpNo ratings yet
- Practice Sheet Mean Median Mode STD Var v1Document17 pagesPractice Sheet Mean Median Mode STD Var v1ธมนพรรญอัศวสันติชัยNo ratings yet
- Descriptive Statistics IIDocument24 pagesDescriptive Statistics IIJoseDSantosNo ratings yet
- Stats101A - Chapter 2Document59 pagesStats101A - Chapter 2Zhen WangNo ratings yet
- Probability and StatisticsDocument53 pagesProbability and Statisticsvinita sandriNo ratings yet
- Central Tendency - Fall 20Document38 pagesCentral Tendency - Fall 20RupalNo ratings yet
- 5 - Measures of VariationDocument8 pages5 - Measures of Variationfretzel meNo ratings yet
- Stat 115 - Chapter 1Document156 pagesStat 115 - Chapter 1Chisei MeadowNo ratings yet
- 3.2 Measures of Dispersion (Ungrouped)Document15 pages3.2 Measures of Dispersion (Ungrouped)kzw898zfffNo ratings yet
- Cambridge AS Biology 9700 Practical NotesDocument2 pagesCambridge AS Biology 9700 Practical NotesSafiya Naina100% (1)
- 1 - Chapter (1) Analysis of Data and Its Types ExerciseDocument10 pages1 - Chapter (1) Analysis of Data and Its Types ExerciseAlaa FaroukNo ratings yet
- Module 4 Measures of VariabilityDocument9 pagesModule 4 Measures of VariabilityNiema Tejano FloroNo ratings yet
- Chapter 4 StatisticsDocument16 pagesChapter 4 StatisticsGerckey RasonabeNo ratings yet
- Lecture 2 - Descriptive StatisticsDocument40 pagesLecture 2 - Descriptive StatisticsShuYunNo ratings yet
- Measures of Dispersion and Relative StandingDocument11 pagesMeasures of Dispersion and Relative StandingirtexafarooqNo ratings yet
- Measures of VariabilityDocument6 pagesMeasures of VariabilityNiña Mae DiazNo ratings yet
- Unit 4Document66 pagesUnit 4MananNo ratings yet
- Data Collection and DisplayDocument34 pagesData Collection and Displaykemigishapatience369No ratings yet
- RN6 - BEEA StatPro RN - Student's T-Distribution - SJ - MP - FINALDocument15 pagesRN6 - BEEA StatPro RN - Student's T-Distribution - SJ - MP - FINALkopii utoyyNo ratings yet
- Statistik Deskriptif - 2016 BIRUDocument64 pagesStatistik Deskriptif - 2016 BIRUCahyaNo ratings yet
- Generalized Ratio Estimators in Two RevisedDocument18 pagesGeneralized Ratio Estimators in Two Revisediaset123No ratings yet
- Fe Statistics ReviewDocument66 pagesFe Statistics Reviewfem mece3381No ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Measures of TendencyDocument12 pagesMeasures of Tendencythyrany cattelNo ratings yet
- Hotelling's One-Sample T2Document8 pagesHotelling's One-Sample T2scjofyWFawlroa2r06YFVabfbaj100% (1)
- Philippine Christian University: Statistics and Probability (G 11) W 1 M 9-13, 2020Document51 pagesPhilippine Christian University: Statistics and Probability (G 11) W 1 M 9-13, 2020sample sampleNo ratings yet
- Notas EstadisticaDocument20 pagesNotas EstadisticaCristian CanazaNo ratings yet
- GB Academy Equation ListDocument16 pagesGB Academy Equation ListfaysalnaeemNo ratings yet
- A Level Maths - Statistics Revision NotesDocument9 pagesA Level Maths - Statistics Revision NotesAftab AhmadNo ratings yet
- 9 SamplingDocument5 pages9 SamplingTasbir HasanNo ratings yet
- HYPERLIPIDEMIADocument33 pagesHYPERLIPIDEMIAatiqullah tarmiziNo ratings yet
- Immune ResponseDocument21 pagesImmune Responseatiqullah tarmiziNo ratings yet
- Inflammation and HealingDocument23 pagesInflammation and Healingatiqullah tarmiziNo ratings yet
- Pathophysiology For Health Sciences BHS415: Rozzana Mohd Said, PHDDocument20 pagesPathophysiology For Health Sciences BHS415: Rozzana Mohd Said, PHDatiqullah tarmiziNo ratings yet
- Ethics - Case AnalysisDocument1 pageEthics - Case AnalysisDiana Rose DalitNo ratings yet
- Prak ParuDocument17 pagesPrak Paruhan jisungNo ratings yet
- Love vs. Sexual Attraction: David Tian, PH.D., and Aura Transformation PresentDocument18 pagesLove vs. Sexual Attraction: David Tian, PH.D., and Aura Transformation PresentRicky KarmakarNo ratings yet
- Riverside Medical College College of Nursing Professor: Jessie Daclis Topic: Communicable Diseases Day 1Document2 pagesRiverside Medical College College of Nursing Professor: Jessie Daclis Topic: Communicable Diseases Day 1Trixie Adaley Xen HeirenciaNo ratings yet
- Confidential User ResumeDocument6 pagesConfidential User ResumeParam SinhaNo ratings yet
- Physical Development of Infants and ToddlersDocument31 pagesPhysical Development of Infants and ToddlersNeth CaparosNo ratings yet
- HESI Women's Health:Newborn DrugsDocument8 pagesHESI Women's Health:Newborn Drugsisapatrick8126No ratings yet
- Body Fat Percentage PDFDocument23 pagesBody Fat Percentage PDFmcvelli40No ratings yet
- Gram-Color Modified (Phenol-Free) Staining Kit For Gram Staining Method On Bacteriological SmearsDocument2 pagesGram-Color Modified (Phenol-Free) Staining Kit For Gram Staining Method On Bacteriological Smearsaisyah annisa rahma hidayahNo ratings yet
- Early Detection of Alzheimers Disease With Blood Plasma Proteins Using Support Vector MachinesDocument9 pagesEarly Detection of Alzheimers Disease With Blood Plasma Proteins Using Support Vector MachinesDhanusNo ratings yet
- Memo-1 HRDocument2 pagesMemo-1 HRMukhammadbobur ShamirbaevNo ratings yet
- Incidence of Recurrent Laryngeal Nerve Palsy Following Thyroid SurgeryDocument25 pagesIncidence of Recurrent Laryngeal Nerve Palsy Following Thyroid SurgeryAshokNo ratings yet
- Sections of Lab - EssayDocument3 pagesSections of Lab - EssayhalamanNo ratings yet
- Revisi Provincial Team Leader New For HabibaDocument19 pagesRevisi Provincial Team Leader New For HabibaFagi KarimNo ratings yet
- Study Guide 43 PDFDocument5 pagesStudy Guide 43 PDFОлександр ЛебедєвNo ratings yet
- AzSPU Environmental and Social Impact Assessment (ESIA) Management ProcessDocument8 pagesAzSPU Environmental and Social Impact Assessment (ESIA) Management ProcessEl KhanNo ratings yet
- Concept of Intentional Injuries and Its TypesDocument6 pagesConcept of Intentional Injuries and Its TypesDomenique Aldrin RestauroNo ratings yet
- Heart Failure PredictionDocument24 pagesHeart Failure PredictionritubajajNo ratings yet
- Liquid Love Zygmunt Baumans Thesis On Sex RevisitDocument17 pagesLiquid Love Zygmunt Baumans Thesis On Sex RevisitCihenNo ratings yet
- JMYKo OncologyReports 2014Document12 pagesJMYKo OncologyReports 2014vikram413No ratings yet
- Rider Medical WaiverDocument2 pagesRider Medical Waiverapi-197492077No ratings yet
- Parole AgreementDocument6 pagesParole AgreementKUTV 2News100% (1)
- Module 2 Community Organizing - 2140354780 PDFDocument10 pagesModule 2 Community Organizing - 2140354780 PDFAlyssa marieNo ratings yet
- Sharp HazardDocument3 pagesSharp HazardJaden QuimsonNo ratings yet
- Water Pollution, Causes and EffectsDocument28 pagesWater Pollution, Causes and EffectsRuchir Gupta67% (3)
- TCE Safety Pocket Manual-11 PDFDocument41 pagesTCE Safety Pocket Manual-11 PDFqamar sayed100% (1)
- Comm Med AIIMS Nov 2019 v2Document17 pagesComm Med AIIMS Nov 2019 v2NokiaNo ratings yet
- Toothpaste IngredientsDocument10 pagesToothpaste Ingredientsjaxine labialNo ratings yet