Download as pptx, pdf, or txt
You might also like
- Algorithms For Calculating VarianceDocument11 pagesAlgorithms For Calculating Varianceisabella343No ratings yet
- AE4S01 Lecture Notes v2.04 TotalDocument425 pagesAE4S01 Lecture Notes v2.04 Totalpedro_astro100% (1)
- Activity Proposal - Trade Fair2018Document12 pagesActivity Proposal - Trade Fair2018Yuki Nakata100% (2)
- The Great TreeDocument186 pagesThe Great TreeFelippeNo ratings yet
- Ken Wilber - Sex, Ecology, Spirituality (Zen - Evolution.meditation - Enlightenment.philosophy - Psychology.science)Document498 pagesKen Wilber - Sex, Ecology, Spirituality (Zen - Evolution.meditation - Enlightenment.philosophy - Psychology.science)BernardoRepetto100% (8)
- GECC 104 ModuleDocument6 pagesGECC 104 ModuleMariel DepaudhonNo ratings yet
- Measures of DispersionDocument12 pagesMeasures of DispersionLea Marie PatindolNo ratings yet
- Math Written Reportgroup 4 PDFDocument18 pagesMath Written Reportgroup 4 PDFJaynerale EnriquezNo ratings yet
- Worksheet in GE Math: Wk-12 Statistics Measures of DispersionDocument4 pagesWorksheet in GE Math: Wk-12 Statistics Measures of DispersionAngel OreiroNo ratings yet
- Measures of VariabilityDocument5 pagesMeasures of VariabilityMs. Mary UmitenNo ratings yet
- Project in DSA JavaDocument5 pagesProject in DSA JavaHitesh ReddyNo ratings yet
- Measures of DispersionDocument16 pagesMeasures of DispersionEdesa JarabejoNo ratings yet
- G4-Measures of VariabilityDocument11 pagesG4-Measures of VariabilityMichael CalongcongNo ratings yet
- Note 02Document31 pagesNote 02Anonymous wlP4y7hz3No ratings yet
- Measures of Dispersion: ReportersDocument27 pagesMeasures of Dispersion: ReportersTulibas Karl Jade J - BSN 1ENo ratings yet
- Measures of DispersionDocument3 pagesMeasures of DispersionMarjorie AquinoNo ratings yet
- Standard DeviationDocument9 pagesStandard DeviationHarika KalluriNo ratings yet
- Measures of Spread or Dispersion (Mean, Variance, and Standard Deviation) Topic ContentsDocument9 pagesMeasures of Spread or Dispersion (Mean, Variance, and Standard Deviation) Topic Contentsjelyn bermudezNo ratings yet
- Measures of VariabilityDocument6 pagesMeasures of VariabilityNiña Mae DiazNo ratings yet
- Measures-of-Spread-or-Dispersion-Learning MaterialDocument9 pagesMeasures-of-Spread-or-Dispersion-Learning MaterialTOLENTINO, Joferose AluyenNo ratings yet
- Chapter 4 StatisticsDocument55 pagesChapter 4 StatisticsAlfa May BuracNo ratings yet
- Lesson 9: Measures of Variation: How Spread Out Is The Data?Document18 pagesLesson 9: Measures of Variation: How Spread Out Is The Data?Md Ibrahim MollaNo ratings yet
- Session 9Document23 pagesSession 9eframil landuanNo ratings yet
- 8.3 Measures of Dispersion: Standard DeviationDocument19 pages8.3 Measures of Dispersion: Standard Deviationbilal safiNo ratings yet
- Lecture 4. Measures of Variability (Part 1)Document13 pagesLecture 4. Measures of Variability (Part 1)ziadwageh74No ratings yet
- Barnfm10e PPT 8 3Document19 pagesBarnfm10e PPT 8 3Princess Melanie MelendezNo ratings yet
- Barnfm10e PPT 8 3Document19 pagesBarnfm10e PPT 8 3Princess Melanie MelendezNo ratings yet
- FINAL EXAM IN E-WPS OfficeDocument12 pagesFINAL EXAM IN E-WPS OfficeLorwel ReyesNo ratings yet
- Stats Lecture 03. Summarizing of Data - NewDocument20 pagesStats Lecture 03. Summarizing of Data - NewShair Muhammad hazaraNo ratings yet
- Business Statistics: Session 2Document60 pagesBusiness Statistics: Session 2HARI SINGH CHOUHANNo ratings yet
- 4 - Statistik DeskriptifDocument33 pages4 - Statistik DeskriptifDhe NurNo ratings yet
- Statistika Minggu 3Document9 pagesStatistika Minggu 3Nur Baiti100% (1)
- Topic 3 Measures of DispersionDocument5 pagesTopic 3 Measures of DispersionEll VNo ratings yet
- Handout 4: The Statistical ModelDocument17 pagesHandout 4: The Statistical ModelYUVISHAIS PAOLA PAYARES BALDIRISNo ratings yet
- Measures of Central Tendency and VariabilityDocument38 pagesMeasures of Central Tendency and Variabilityapi-619738021No ratings yet
- Statistics For Management - A2Document11 pagesStatistics For Management - A2Ayushi PrabhuNo ratings yet
- KWT 4.ukuran Keragaman Data 2013Document29 pagesKWT 4.ukuran Keragaman Data 2013AndiNo ratings yet
- Error and Uncertainty: General Statistical PrinciplesDocument8 pagesError and Uncertainty: General Statistical Principlesdéborah_rosalesNo ratings yet
- Sampling: The Act of Studying Only A Segment or Subset of The Population Representing The WholeDocument42 pagesSampling: The Act of Studying Only A Segment or Subset of The Population Representing The WholeKate BarilNo ratings yet
- Chapter Four: Curve FittingDocument58 pagesChapter Four: Curve FittingGirmole WorkuNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- Statistical Methods: 1. Pareto Diagrams and Dot DiagramsDocument48 pagesStatistical Methods: 1. Pareto Diagrams and Dot DiagramsArun VasanNo ratings yet
- Probability and Statistics in EngineeringDocument24 pagesProbability and Statistics in EngineeringasadNo ratings yet
- Measures of DispersionDocument28 pagesMeasures of DispersionMaria Jessa BruzaNo ratings yet
- 2-Statistical Measures of DataDocument61 pages2-Statistical Measures of Datajasonaguilon99No ratings yet
- Analisis Statistika: Materi 5 Inferensia Dari Contoh Besar (Inference From Large Samples)Document19 pagesAnalisis Statistika: Materi 5 Inferensia Dari Contoh Besar (Inference From Large Samples)Ma'ruf NurwantaraNo ratings yet
- Measures of Dispersion - Docx4.18.23Document3 pagesMeasures of Dispersion - Docx4.18.23Jericho TumazarNo ratings yet
- 2010 JNCASR Juniper Flow Instability Matlab HandoutDocument9 pages2010 JNCASR Juniper Flow Instability Matlab HandoutKhor Shu HengNo ratings yet
- Standard DeviationDocument9 pagesStandard DeviationPresana VisionNo ratings yet
- Module 4Document8 pagesModule 4kaizerkaletanNo ratings yet
- Frequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationDocument4 pagesFrequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationJmazingNo ratings yet
- Descriptive Measures PDFDocument27 pagesDescriptive Measures PDFCrystaline ShyneNo ratings yet
- Quantitative Methods For BusinessDocument16 pagesQuantitative Methods For BusinessabhirejanilNo ratings yet
- Central Tendency and DispersionDocument22 pagesCentral Tendency and Dispersionscropian 9997No ratings yet
- الواجب الأولDocument5 pagesالواجب الأولnawafNo ratings yet
- Lecture 05 - Measures of DispersionDocument17 pagesLecture 05 - Measures of Dispersionferassadadi10No ratings yet
- Topic 1 Numerical MeasureDocument11 pagesTopic 1 Numerical MeasureNedal AbuzwidaNo ratings yet
- AP ECON 2500 Session 2Document22 pagesAP ECON 2500 Session 2Thuỳ DungNo ratings yet
- Standard Deviation and Coefficient of Standard DeviationDocument4 pagesStandard Deviation and Coefficient of Standard Deviationvishnu krishnaNo ratings yet
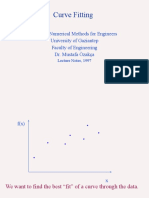
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocument171 pagesCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNo ratings yet
- Linear Models - Numeric PredictionDocument7 pagesLinear Models - Numeric Predictionar9vegaNo ratings yet
- Chapter4.2 FINALDocument6 pagesChapter4.2 FINALCmNo ratings yet
- Numerical Solution of Ordinary Differential Equations Part 4 - Approximation & InterpolationDocument58 pagesNumerical Solution of Ordinary Differential Equations Part 4 - Approximation & InterpolationMelih TecerNo ratings yet
- Practical Cost Saving Ideas For Design ProfessionalsDocument3 pagesPractical Cost Saving Ideas For Design ProfessionalsAnonymous JoB5ZxgNo ratings yet
- Lesson Plan English A-11aDocument4 pagesLesson Plan English A-11aDeejayF1No ratings yet
- 2018 LGU Training Program Design NCCA PCEPDocument4 pages2018 LGU Training Program Design NCCA PCEPMicca AldoverNo ratings yet
- Numerical Control of Machine Tool (De) ME453 Unit 2Document96 pagesNumerical Control of Machine Tool (De) ME453 Unit 2mohd mansoorNo ratings yet
- Dropbox (Service) - WikipediaDocument15 pagesDropbox (Service) - WikipediaglennNo ratings yet
- Light Triggering Thyristor For HVDC and Other Applications.Document6 pagesLight Triggering Thyristor For HVDC and Other Applications.IDESNo ratings yet
- Solving Quadratic Equation by Using Extarcting Square Roots DLPDocument19 pagesSolving Quadratic Equation by Using Extarcting Square Roots DLPLealyn IbanezNo ratings yet
- Reliability Centered MaintenanceDocument116 pagesReliability Centered MaintenanceantonNo ratings yet
- Neuro PhoneDocument14 pagesNeuro PhoneLuis Carlos BarreraNo ratings yet
- Win Amp Shortcut KeyDocument3 pagesWin Amp Shortcut KeyuyopalkasNo ratings yet
- The Decomposition of H2O2 Using CatalaseDocument6 pagesThe Decomposition of H2O2 Using CatalasebenholdsworthNo ratings yet
- Scaling: Business Research MethodsDocument23 pagesScaling: Business Research MethodsSatyajit GhoshNo ratings yet
- Chapter 9 Social Stratification Part 2 - PalmesDocument12 pagesChapter 9 Social Stratification Part 2 - PalmesEdgar PeninsulaNo ratings yet
- Laboratory Experiment No. 5 Theodolite 1. Objective: 2. Intended Learning Outcomes (Ilos)Document5 pagesLaboratory Experiment No. 5 Theodolite 1. Objective: 2. Intended Learning Outcomes (Ilos)mae-maeNo ratings yet
- Mastering Advanced Analytics With Apache SparkDocument75 pagesMastering Advanced Analytics With Apache SparkAgMa HuNo ratings yet
- Assignment - Critical ReviewDocument12 pagesAssignment - Critical Reviewduan4evaNo ratings yet
- CM - Ndungane ExerciseDocument30 pagesCM - Ndungane ExerciseCoryNo ratings yet
- Habits of High Performance Marketing Teams PDFDocument30 pagesHabits of High Performance Marketing Teams PDFBlîndu Alexandru Petru0% (1)
- Algorithm Lab ReportDocument15 pagesAlgorithm Lab Reportthe.nubeNo ratings yet
- Deb Genealogy 10-10-17Document245 pagesDeb Genealogy 10-10-17superm0mof6No ratings yet
- Broad and Narrow Abilities List HandoutDocument11 pagesBroad and Narrow Abilities List HandoutGlade EggettNo ratings yet
- The Golden Mean by Maria Christelle ReodicaDocument5 pagesThe Golden Mean by Maria Christelle ReodicaKl HumiwatNo ratings yet
- Brewer ThesisDocument66 pagesBrewer ThesistugaddanNo ratings yet
- ANALOGYDocument7 pagesANALOGYJANICE ESTABILLONo ratings yet
- Public AdminDocument8 pagesPublic AdminMitra IshanNo ratings yet
- Elm490-Evaluation 3Document12 pagesElm490-Evaluation 3api-435463170No ratings yet