Download as ppt, pdf, or txt
You might also like
- Group 3 CFEV 5th Assignment-Hansson-Private-LabelDocument10 pagesGroup 3 CFEV 5th Assignment-Hansson-Private-LabelShashwat JhaNo ratings yet
- Spring 12 ECON-E370 IU Exam 1 ReviewDocument27 pagesSpring 12 ECON-E370 IU Exam 1 ReviewTutoringZoneNo ratings yet
- Ch1 Prob&Stat NEWDocument35 pagesCh1 Prob&Stat NEWlokasfokaas42No ratings yet
- Chapter-04: Measures of Central TendencyDocument71 pagesChapter-04: Measures of Central TendencySamir SiddiqueNo ratings yet
- Descriptive StatisticsDocument83 pagesDescriptive StatisticsVishvajit KumbharNo ratings yet
- CH 31Document3 pagesCH 31meelas123No ratings yet
- Descriptive Statistics PDFDocument40 pagesDescriptive Statistics PDFKavitha B Pujar100% (1)
- STT 201-20212022Document20 pagesSTT 201-20212022adedejidamilare2019No ratings yet
- Ch03 Statistics For Economic & MGTDocument81 pagesCh03 Statistics For Economic & MGTabdirizaqmohomed2No ratings yet
- Statistics Chapter 3Document103 pagesStatistics Chapter 3hi i'm tunieNo ratings yet
- Chapter 12Document46 pagesChapter 12lehoangson220801No ratings yet
- Chapter 01Document37 pagesChapter 01Stanly Olivien Hisar LinggaNo ratings yet
- Prem Mann, Introductory Statistics, 7/EDocument30 pagesPrem Mann, Introductory Statistics, 7/EZihad hasanNo ratings yet
- Data Analytics in The Hospitality Industry HMPE 201Document23 pagesData Analytics in The Hospitality Industry HMPE 201Venice EspinozaNo ratings yet
- Day 01-Basic Statistics - Part (I)Document29 pagesDay 01-Basic Statistics - Part (I)Sparsh VijayvargiaNo ratings yet
- Prem Mann, Introductory Statistics, 7/EDocument44 pagesPrem Mann, Introductory Statistics, 7/EMadia MujibNo ratings yet
- 4.2 Data DescriptionDocument12 pages4.2 Data DescriptionAngela 18 PhotosNo ratings yet
- BSTAT HANDOUTS - DESCRIPTIVE ONLY Handouts 3Document18 pagesBSTAT HANDOUTS - DESCRIPTIVE ONLY Handouts 3Clint ParzanNo ratings yet
- Descriptive Stat Lec 1Document32 pagesDescriptive Stat Lec 1xrose254No ratings yet
- Introduction & Descriptive StatisticsDocument53 pagesIntroduction & Descriptive StatisticsArga pratamaaNo ratings yet
- Chapter 3 Numerical Descriptive MeasuresDocument65 pagesChapter 3 Numerical Descriptive MeasuresKhouloud bn16No ratings yet
- Descriptive Statistics Unit 2Document72 pagesDescriptive Statistics Unit 2Daniel AtiehNo ratings yet
- Module HandbookDocument31 pagesModule HandbookMG ManuppakNo ratings yet
- Essentials of Statistics For The Behavioral Sciences 3Rd Edition Nolan Solutions Manual Full Chapter PDFDocument30 pagesEssentials of Statistics For The Behavioral Sciences 3Rd Edition Nolan Solutions Manual Full Chapter PDFkelly.adams280100% (11)
- Essentials of Statistics For The Behavioral Sciences 3rd Edition Nolan Solutions Manual 1Document9 pagesEssentials of Statistics For The Behavioral Sciences 3rd Edition Nolan Solutions Manual 1marsha100% (41)
- Descriptive Statistics - Note1Document75 pagesDescriptive Statistics - Note1Shaheed MorweNo ratings yet
- Introduction To Stats, DatasetsDocument86 pagesIntroduction To Stats, DatasetsAnkush ChaudharyNo ratings yet
- Statistical Techniques in BusinessDocument8 pagesStatistical Techniques in BusinessyuginNo ratings yet
- Applied Business Statistics, 7 Ed. by Ken BlackDocument24 pagesApplied Business Statistics, 7 Ed. by Ken BlackKaustubh SaksenaNo ratings yet
- Midterm LessonDocument26 pagesMidterm Lessonhyunsuk fhebieNo ratings yet
- Business Statistics: A First Course: 6 EditionDocument16 pagesBusiness Statistics: A First Course: 6 EditionPeterNo ratings yet
- Chapter 3Document17 pagesChapter 3immoonliqhtNo ratings yet
- Quantitative MethodsDocument33 pagesQuantitative Methodscouragemutamba3No ratings yet
- Chapter 01Document56 pagesChapter 01Anikk HassanNo ratings yet
- Unit - II Data PreprocessingDocument35 pagesUnit - II Data PreprocessingANITHA AMMUNo ratings yet
- ElemStat - Module 3 - Introduction To Statistics - W3 PortraitDocument21 pagesElemStat - Module 3 - Introduction To Statistics - W3 PortraitDebbie FernandezNo ratings yet
- Solution Manual For Statistics Data Analysis and Decision Modeling 5th Edition Evans 0132744287 9780132744287Document7 pagesSolution Manual For Statistics Data Analysis and Decision Modeling 5th Edition Evans 0132744287 9780132744287tiffanybreweridearcpxmz100% (30)
- It B.tech II Year II Sem DV (R18a0555)Document73 pagesIt B.tech II Year II Sem DV (R18a0555)kandocrush2004No ratings yet
- Business Statistics KMBN-104 - Q - AnsDocument30 pagesBusiness Statistics KMBN-104 - Q - AnsRizwan SaifiNo ratings yet
- Basics of StatsDocument49 pagesBasics of StatsDISHA SARAFNo ratings yet
- Calculate Mean, Median, Mode, Variance and Standard Deviation For Column ADocument22 pagesCalculate Mean, Median, Mode, Variance and Standard Deviation For Column AAmol VirbhadreNo ratings yet
- Estimation of The Mean and Proportion: Prem Mann, Introductory Statistics, 8/EDocument78 pagesEstimation of The Mean and Proportion: Prem Mann, Introductory Statistics, 8/Ejago dishNo ratings yet
- Marketing Research: Ninth EditionDocument44 pagesMarketing Research: Ninth EditionSara DassouliNo ratings yet
- Lecture 1 Data Overview and Introduction To SPSS VJUDocument49 pagesLecture 1 Data Overview and Introduction To SPSS VJUdoandn77uelNo ratings yet
- Chapter 1 - Events and Probability of Events - StudentDocument54 pagesChapter 1 - Events and Probability of Events - Studentphuongnguyen050104No ratings yet
- STAT MODULE 2 PopulationSampleMeasures of Central TendencyDocument8 pagesSTAT MODULE 2 PopulationSampleMeasures of Central TendencyDrieya KadiNo ratings yet
- 7 QC ToolsDocument40 pages7 QC ToolssuhasNo ratings yet
- Initial Data Analysis: Central TendencyDocument20 pagesInitial Data Analysis: Central Tendencypravin_gondhaleNo ratings yet
- CHAPTER 1 (1) 9878خ7ف765876ق876Document16 pagesCHAPTER 1 (1) 9878خ7ف765876ق876swap99482No ratings yet
- BUSD2027 QualityMgmt Module2Document168 pagesBUSD2027 QualityMgmt Module2Nyko Martin MartinNo ratings yet
- Meharaj Khan (BS)Document7 pagesMeharaj Khan (BS)RebelNo ratings yet
- Define StatisticsDocument89 pagesDefine StatisticskhanjiNo ratings yet
- Chap 4 Part1 Intro Measures of Central Tendency of Ungrouped Data 1Document74 pagesChap 4 Part1 Intro Measures of Central Tendency of Ungrouped Data 1Janelle Dela CruzNo ratings yet
- Phase 3 Sakshi+Jain 20MBA1608 PDFDocument14 pagesPhase 3 Sakshi+Jain 20MBA1608 PDFAshutosh prakashNo ratings yet
- 08 Handout 1Document5 pages08 Handout 1Luke VenturaNo ratings yet
- Data ManagementDocument25 pagesData ManagementHubert John TabogocNo ratings yet
- Ch03 Numerical Measures PDFDocument29 pagesCh03 Numerical Measures PDFAndrew NaguibNo ratings yet
- Lecture 3. Descriptive StatisticsDocument10 pagesLecture 3. Descriptive Statisticsmia palacioNo ratings yet
- PED-6 Joebert AciertoDocument4 pagesPED-6 Joebert AciertoJoebert AciertoNo ratings yet
- All The Statistical Concept You Required For Data ScienceDocument26 pagesAll The Statistical Concept You Required For Data ScienceAshwin ChaudhariNo ratings yet
- Statistics Grade 12Document24 pagesStatistics Grade 12Reitumetse MolefeNo ratings yet
- DDM Print MTDocument21 pagesDDM Print MTShashwat JhaNo ratings yet
- Introduction To ServicesDocument19 pagesIntroduction To ServicesShashwat JhaNo ratings yet
- XLS249 XLS EngDocument4 pagesXLS249 XLS EngShashwat JhaNo ratings yet
- Samsung IOTDocument13 pagesSamsung IOTShashwat JhaNo ratings yet
- Session 2 Cluster Analysis For SegmentationDocument19 pagesSession 2 Cluster Analysis For SegmentationShashwat JhaNo ratings yet
- Shashwat RM SelectionsDocument4 pagesShashwat RM SelectionsShashwat JhaNo ratings yet
- Study Id12773 Starbucks-Statista-DossierDocument32 pagesStudy Id12773 Starbucks-Statista-DossierShashwat JhaNo ratings yet
- DAODocument52 pagesDAOShashwat JhaNo ratings yet
- SFI Session 11 Blue Ocean StrategyDocument22 pagesSFI Session 11 Blue Ocean StrategyShashwat JhaNo ratings yet
- LifestyleDocument18 pagesLifestyleShashwat JhaNo ratings yet
- G10 Sticks Kebob Assignment - Answers - DDMDocument15 pagesG10 Sticks Kebob Assignment - Answers - DDMShashwat JhaNo ratings yet
- SFI Session 14 - InnovationDocument79 pagesSFI Session 14 - InnovationShashwat JhaNo ratings yet
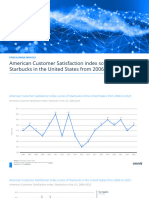
- Statistic - Id216719 - American Customer Satisfaction Index - Starbucks in The Us 2006 2023Document8 pagesStatistic - Id216719 - American Customer Satisfaction Index - Starbucks in The Us 2006 2023Shashwat JhaNo ratings yet
- Mergers and Acquisitions MT PrintDocument1 pageMergers and Acquisitions MT PrintShashwat JhaNo ratings yet
- Results r03Document25 pagesResults r03Shashwat JhaNo ratings yet
- Results r05Document25 pagesResults r05Shashwat JhaNo ratings yet
- G3 Research Data Impact of Inflation On Stock Market Regression Time Series and ForecastingDocument38 pagesG3 Research Data Impact of Inflation On Stock Market Regression Time Series and ForecastingShashwat JhaNo ratings yet
- Group 7 Decision Sciences Project Topic ProposalDocument4 pagesGroup 7 Decision Sciences Project Topic ProposalShashwat JhaNo ratings yet
- G8 Final Project PresentationDocument14 pagesG8 Final Project PresentationShashwat JhaNo ratings yet
- Group3 Corporate Finance Rent Vs Buy ExplanationDocument4 pagesGroup3 Corporate Finance Rent Vs Buy ExplanationShashwat JhaNo ratings yet
- Course Outline - SBMDocument4 pagesCourse Outline - SBMShashwat JhaNo ratings yet
- DS S9-10Document2 pagesDS S9-10Shashwat JhaNo ratings yet
- Decision Sciences S4 Solver UseDocument3 pagesDecision Sciences S4 Solver UseShashwat JhaNo ratings yet
- Business Communication ET MaterialDocument10 pagesBusiness Communication ET MaterialShashwat JhaNo ratings yet
- DS Final Project Data Group 7Document2 pagesDS Final Project Data Group 7Shashwat JhaNo ratings yet
- CFEV Practice 19Document3 pagesCFEV Practice 19Shashwat JhaNo ratings yet
- Pre-Read 1 - Structure of A Consulting Case InterviewDocument3 pagesPre-Read 1 - Structure of A Consulting Case InterviewShashwat JhaNo ratings yet
- DS Sesion 12 Shortest Route ProblemDocument5 pagesDS Sesion 12 Shortest Route ProblemShashwat JhaNo ratings yet
- IL&FS COrporate Fraud Q7Document2 pagesIL&FS COrporate Fraud Q7Shashwat JhaNo ratings yet
- Assignment - 2: Topic(s) Included: Measures of Central Tendency, Measure of DispersionDocument2 pagesAssignment - 2: Topic(s) Included: Measures of Central Tendency, Measure of DispersionIam AlisiddiquiNo ratings yet
- CH 01 TestDocument22 pagesCH 01 TestNeeti GurunathNo ratings yet
- Soluciones Libro DanielDocument273 pagesSoluciones Libro DanielStacey RamosNo ratings yet
- M3L12Document13 pagesM3L12abimana100% (1)
- Notes On Exer 3: Part 1. The Ovicidal/Larvicidal (OL) Trap Is A Tool Which Aims To Reduce The Population of DengueDocument2 pagesNotes On Exer 3: Part 1. The Ovicidal/Larvicidal (OL) Trap Is A Tool Which Aims To Reduce The Population of DengueCyrene MBolañosNo ratings yet
- L MomentsDocument39 pagesL MomentsJavier Senent AparicioNo ratings yet
- Application of Variography To The Control of Species in Material Process Streams: in An Iron Ore ProductDocument14 pagesApplication of Variography To The Control of Species in Material Process Streams: in An Iron Ore ProductsaeedhoseiniNo ratings yet
- Output 5555Document24 pagesOutput 5555nurica266No ratings yet
- A Case StudyDocument7 pagesA Case Studyadarshrai9792No ratings yet
- AP Statistics - Summary of Confidence Intervals and Hypothesis TestsDocument5 pagesAP Statistics - Summary of Confidence Intervals and Hypothesis TestsThảo VânNo ratings yet
- Stats Statistical Diagrams NotesDocument11 pagesStats Statistical Diagrams NotesPavit SinghNo ratings yet
- QBUS6320 Individual Assignment 2 - 2021S1 - 500601765Document11 pagesQBUS6320 Individual Assignment 2 - 2021S1 - 500601765刘文雨杰No ratings yet
- Statistics Introduction: Dr. Sudeep MallickDocument73 pagesStatistics Introduction: Dr. Sudeep MallickVishalRathoreNo ratings yet
- Final PPT Ped 4Document33 pagesFinal PPT Ped 4Axel Rosemarie PlecesNo ratings yet
- QBM 101 Business Statistics: Department of Business Studies Faculty of Business, Economics & Accounting HE LP UniversityDocument34 pagesQBM 101 Business Statistics: Department of Business Studies Faculty of Business, Economics & Accounting HE LP UniversityVân HảiNo ratings yet
- 1 PDFDocument44 pages1 PDFAftab KhanNo ratings yet
- Questions Short Concept QuestionsDocument61 pagesQuestions Short Concept QuestionsNg Win WwaNo ratings yet
- Measures of Skewness and KurtosisDocument24 pagesMeasures of Skewness and Kurtosismikmik Rxs100% (1)
- JantinaDocument8 pagesJantinaHAYATINo ratings yet
- Measures of DispersionDocument52 pagesMeasures of DispersionPanma Patel0% (1)
- Nursing Research Quiz 1Document5 pagesNursing Research Quiz 1Diane Smith-LevineNo ratings yet
- DiameterJ - ImageJDocument10 pagesDiameterJ - ImageJsamiaNo ratings yet
- Chapter - Three - Graphical Data Analysis v3Document38 pagesChapter - Three - Graphical Data Analysis v3Sahar SanaNo ratings yet
- The Stat 43 AssignmentDocument3 pagesThe Stat 43 Assignmentbajaman1234No ratings yet
- MCC Final Exam For Assesstment of LearningDocument43 pagesMCC Final Exam For Assesstment of LearningMAYLON MANALOTONo ratings yet
- Summative TestDocument1 pageSummative TestAlice JamesNo ratings yet
- Test 1 November 2017 STA104Document4 pagesTest 1 November 2017 STA104Faten Zara100% (1)
- Note Buad806 Mod1 3buhumcr6wxmrreDocument251 pagesNote Buad806 Mod1 3buhumcr6wxmrreAdetunji Babatunde TaiwoNo ratings yet
- Skewness and KutosisDocument7 pagesSkewness and KutosisDog VenturesNo ratings yet