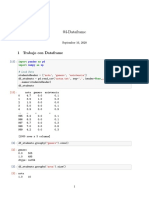
Download as pptx, pdf, or txt
You might also like
- Exploring The Titanic TextDocument12 pagesExploring The Titanic TextRawda Damra100% (1)
- Introduction To Data MiningDocument3 pagesIntroduction To Data MiningQuân PhạmNo ratings yet
- 6475 - Railway Reservation SystemDocument26 pages6475 - Railway Reservation Systemhimanshu100% (1)
- Q 2Document3 pagesQ 2Mohit JainNo ratings yet
- WEEK 14 Hours 1&3 CLASS MATERIALDocument4 pagesWEEK 14 Hours 1&3 CLASS MATERIALJaime CarddozoNo ratings yet
- Ai Platform Qwik StartDocument27 pagesAi Platform Qwik StartVaibhav BhardwajNo ratings yet
- 2.2.1 DataframeDocument5 pages2.2.1 DataframeJavier ChandíaNo ratings yet
- Data Assigment 1Document32 pagesData Assigment 1Sukhwinder Kaur100% (2)
- 20BCE1779 - Web Mining - Lab-5Document8 pages20BCE1779 - Web Mining - Lab-5Patel VedantNo ratings yet
- Import Import As Import As: #Default To CSVDocument6 pagesImport Import As Import As: #Default To CSVNekomancer DavionNo ratings yet
- Decision Tree Algorithm 1677030641Document9 pagesDecision Tree Algorithm 1677030641juanNo ratings yet
- ML AssignmentDocument8 pagesML AssignmentHimalaya SagarNo ratings yet
- IP Practical 2023-24 (1 To 34)Document32 pagesIP Practical 2023-24 (1 To 34)Epic Person100% (1)
- Data AnalysisDocument12 pagesData AnalysisVikramAditya RattanNo ratings yet
- List Code Project Assessment Using RDocument12 pagesList Code Project Assessment Using RHazel RahmaddioNo ratings yet
- IterationDocument40 pagesIterationSidhu WorldwideNo ratings yet
- NLP PDFDocument17 pagesNLP PDFvlmohammedadnan9No ratings yet
- Assignment No - 10Document3 pagesAssignment No - 10Sid ChabukswarNo ratings yet
- Methodes Pour DataframesDocument10 pagesMethodes Pour DataframesWalid MaheriNo ratings yet
- Coding TitanicmainDocument58 pagesCoding Titanicmainnaderaqistina23No ratings yet
- Praktikum IVDocument6 pagesPraktikum IVPujiyantiNo ratings yet
- EmployeeMgmt XII IP ProjectReprot 2022 23Document16 pagesEmployeeMgmt XII IP ProjectReprot 2022 23ushavalsaNo ratings yet
- Final Assignment Cardiogood FitnessDocument31 pagesFinal Assignment Cardiogood FitnessHaritika ChhatwalNo ratings yet
- Abhi NeetDocument36 pagesAbhi NeetAnitha SathiaseelanNo ratings yet
- Data Pre PracticeDocument9 pagesData Pre Practicessakhare2001No ratings yet
- HorseDocument25 pagesHorsejoshkek1942No ratings yet
- MongoDB Chapter3Document30 pagesMongoDB Chapter3massywebNo ratings yet
- Kubamamasoza BaxazuxefujuDocument2 pagesKubamamasoza BaxazuxefujuManasvi SutharNo ratings yet
- R CommandDocument52 pagesR Commandkoustav nahaNo ratings yet
- 017) Pandas - Batch 2 - Day 017Document47 pages017) Pandas - Batch 2 - Day 017saaraappambuNo ratings yet
- Journal 12Document54 pagesJournal 12Be xNo ratings yet
- Problem: Write A Kids Play Program That Prints The Capital of A Country Given The Name of The CountryDocument28 pagesProblem: Write A Kids Play Program That Prints The Capital of A Country Given The Name of The CountryluckyNo ratings yet
- Part A Assignment 10Document3 pagesPart A Assignment 10B49 Pravin TeliNo ratings yet
- Computer Project Spiral FileDocument21 pagesComputer Project Spiral FileTanvir MohdNo ratings yet
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Lab7.ipynb - ColaboratoryDocument5 pagesLab7.ipynb - ColaboratoryPRAGASM PROG100% (1)
- Set 2Document2 pagesSet 2Saksham BajpayiNo ratings yet
- Passing Structs To FunctionsDocument24 pagesPassing Structs To FunctionsTheja ThejeshNo ratings yet
- Ip-12-2023-24 Practical FileDocument19 pagesIp-12-2023-24 Practical FilekashinathchandakNo ratings yet
- Intro To Py and ML - Part 2Document10 pagesIntro To Py and ML - Part 2KAORU AmaneNo ratings yet
- Problem: Write A Kids Play Program That Prints The Capital of A Country Given The Name of The CountryDocument31 pagesProblem: Write A Kids Play Program That Prints The Capital of A Country Given The Name of The CountryVhan DarshNo ratings yet
- Reagrding Lab TestDocument8 pagesReagrding Lab Testaman rajNo ratings yet
- Pandas Library - Ipynb - ColaboratoryDocument2 pagesPandas Library - Ipynb - ColaboratoryMayank SagwekarNo ratings yet
- Fowd Javascript LibrariesDocument35 pagesFowd Javascript LibrariespapankbbNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- 1Document19 pages1HarsimranKaurBindraNo ratings yet
- Sheetalkumar Biswal Assignment 5 R PRGMDocument6 pagesSheetalkumar Biswal Assignment 5 R PRGMGovind VishwakarmaNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Viraj NGT PracticalDocument14 pagesViraj NGT Practicalnighotviraj55No ratings yet
- 数据科学导论 数据科学导论HW4Document4 pages数据科学导论 数据科学导论HW4zzzzzzzzzzzzzzNo ratings yet
- Blood DonationDocument31 pagesBlood DonationSaniya AttarNo ratings yet
- 3a Data Frame - Jupyter NotebookDocument5 pages3a Data Frame - Jupyter Notebookvenkatesh mNo ratings yet
- Quora Question Pair Similarity ProblemDocument41 pagesQuora Question Pair Similarity Problemaggarwal nNo ratings yet
- Pandas Advance Quiz - Data Science Masters - PW SkillsDocument5 pagesPandas Advance Quiz - Data Science Masters - PW SkillsShashi Kamal Chakraborty100% (1)
- Python Data Structure-Dictionary PDFDocument12 pagesPython Data Structure-Dictionary PDFRajendra BuchadeNo ratings yet
- 9.dictionary Data StructureDocument12 pages9.dictionary Data StructureashutoshNo ratings yet
- HOTEL MANAGEMENT PROJECT Print Final-1 ConvDocument26 pagesHOTEL MANAGEMENT PROJECT Print Final-1 ConvAtharva MaheshwariNo ratings yet
- Experiment No 6 PythonDocument14 pagesExperiment No 6 PythonShubham PalavNo ratings yet
- The Series Data Structure: Import Pandas As PDDocument8 pagesThe Series Data Structure: Import Pandas As PDBhanu JhaNo ratings yet
- MongoDB ManualDocument25 pagesMongoDB ManualScreen AgersNo ratings yet
- TITANIC ReadingDocument2 pagesTITANIC ReadingYuliana PaolaNo ratings yet
- The Titanic Is Sinking - Primary SourceDocument3 pagesThe Titanic Is Sinking - Primary SourceHayley WongNo ratings yet
- British Council - BBC: The Sinking of The TitanicDocument3 pagesBritish Council - BBC: The Sinking of The TitanicAdrian LanzNo ratings yet
- Local Titanic Survivor's Story: in Her Own WordsDocument11 pagesLocal Titanic Survivor's Story: in Her Own WordsAJ StokerNo ratings yet
- Titanic Script With Name'sDocument5 pagesTitanic Script With Name'ssulNo ratings yet
- A. Reading ComprehensionDocument24 pagesA. Reading Comprehensionart_gbNo ratings yet
- AfresgthdfjkglioéluikujhtDocument2 pagesAfresgthdfjkglioéluikujhtFanny SuzearNo ratings yet
- Short Story of The Titanic: Www.5pe Rcangol - HuDocument2 pagesShort Story of The Titanic: Www.5pe Rcangol - HuMaylin SamaniegoNo ratings yet
- TitanicDocument28 pagesTitanicsportbullarigiaNo ratings yet
- Millvina Dean, Titanic's Last Survivor, Dies at 97Document5 pagesMillvina Dean, Titanic's Last Survivor, Dies at 97Алена ХитрукNo ratings yet
- TestsDocument4 pagesTestsLearn EnglishNo ratings yet
- Reading Exercise Unit 3Document2 pagesReading Exercise Unit 3Emanuel sarracinoNo ratings yet
- Hoimanti Dutta - A2 - 59 - Book ReviewDocument21 pagesHoimanti Dutta - A2 - 59 - Book ReviewHoimanti DuttaNo ratings yet
- Titanic Presentation 4Document26 pagesTitanic Presentation 4SushilchaudharyNo ratings yet
- AK TitanicDocument2 pagesAK TitanicAlican FidanNo ratings yet
- Ingles: Parte I: Read The Text Carefully and Translate: (Lea El Texto Cuidadosamente y Traducir)Document3 pagesIngles: Parte I: Read The Text Carefully and Translate: (Lea El Texto Cuidadosamente y Traducir)Leidanyelis HernándezNo ratings yet
- NHD Source LedgerDocument11 pagesNHD Source Ledgerapi-533884820No ratings yet
- Dothihhuukh: 4A PredictionsDocument5 pagesDothihhuukh: 4A PredictionsMarce GonzalezNo ratings yet
- IELTS Simulation Reading Test 1 - STUDY4Document1 pageIELTS Simulation Reading Test 1 - STUDY4khoinguyen182206No ratings yet
- Sai LeshDocument162 pagesSai LeshSalman DalpotraNo ratings yet
- LessonDocument35 pagesLessonViệt AnhNo ratings yet
- RMS Titanic Was A British Passenger: Olympic - Class Ocean LinersDocument1 pageRMS Titanic Was A British Passenger: Olympic - Class Ocean Linersandreea uNo ratings yet
- Liste Des Passagers TitanicDocument91 pagesListe Des Passagers TitanicAllen WalkerNo ratings yet
- DATA SET Titanic Passenger List 2020Document63 pagesDATA SET Titanic Passenger List 2020Tamba KendemaNo ratings yet
- The Titanic: Sinking & Facts - HISTORYDocument2 pagesThe Titanic: Sinking & Facts - HISTORYPricelda Villa-BorreNo ratings yet
- Final ProjectDocument23 pagesFinal Projectکمال کتابتونNo ratings yet
- Activity WorksheetsDocument4 pagesActivity WorksheetsLearn EnglishNo ratings yet
- Battleship Row Card Printing Tool v2Document49 pagesBattleship Row Card Printing Tool v2Doug BirtlesNo ratings yet