Download as ppt, pdf, or txt
You might also like
- Supervised Machine Learning Algorithms For Credit Card Fraudulent Transaction Detection: A Comparative StudyDocument4 pagesSupervised Machine Learning Algorithms For Credit Card Fraudulent Transaction Detection: A Comparative StudybalachandNo ratings yet
- I2ml3e Chap6Document37 pagesI2ml3e Chap6EMS Metalworking MachineryNo ratings yet
- Ruiz Modified I2ml3e Chap6Document38 pagesRuiz Modified I2ml3e Chap6Akshaya AshokNo ratings yet
- Lec 7Document21 pagesLec 7Perike Chandra SekharNo ratings yet
- Linear Classifiers: The ProblemDocument47 pagesLinear Classifiers: The ProblemVaishali DNo ratings yet
- 1 Characteristics of Time Series 1.3 Measures of DependenceDocument10 pages1 Characteristics of Time Series 1.3 Measures of DependenceTrịnh TâmNo ratings yet
- QuestionsDocument3 pagesQuestionssanmitrazNo ratings yet
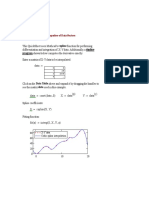
- Final Formula SheetDocument6 pagesFinal Formula SheethcxNo ratings yet
- Three Derivations of Principal Component AnalysisDocument2 pagesThree Derivations of Principal Component Analysisritesh sinhaNo ratings yet
- Slides Amari IG3Document138 pagesSlides Amari IG3anurag sahayNo ratings yet
- 03Document34 pages03Gagan JainNo ratings yet
- Lecture5 PartitionspectralDocument14 pagesLecture5 Partitionspectralapi-3834272No ratings yet
- Chpt03 Mabel Fem For TrussesDocument33 pagesChpt03 Mabel Fem For TrussesgagagaNo ratings yet
- Lecture NotesDocument54 pagesLecture NotesSohail AhmedNo ratings yet
- Finite Element Modeling of Beam Bending VibrationDocument26 pagesFinite Element Modeling of Beam Bending VibrationrasoolNo ratings yet
- Week 12Document15 pagesWeek 12Vu Quoc TrungNo ratings yet
- Prestige Institute of Engineering & Science Indore (M.P.)Document3 pagesPrestige Institute of Engineering & Science Indore (M.P.)SagarManjrekarNo ratings yet
- Apsp1 PDFDocument22 pagesApsp1 PDFJingwei ChenNo ratings yet
- Fundamentals For Finite Element MethodDocument34 pagesFundamentals For Finite Element MethodnaderNo ratings yet
- Homework 2Document1 pageHomework 2Hlophe Nathoe NkosinathiNo ratings yet
- Lec7matrixnorm Part4Document13 pagesLec7matrixnorm Part4Somnath DasNo ratings yet
- !!en5 Discrete Signals DTFT TZ v06Document11 pages!!en5 Discrete Signals DTFT TZ v06Marcela DobreNo ratings yet
- Today: - CalculusDocument61 pagesToday: - CalculusJose Ramon VillatuyaNo ratings yet
- Gradient Descent Based LearnersDocument11 pagesGradient Descent Based LearnerssandtNo ratings yet
- Double Integrals and Change of Order of IntegrationDocument12 pagesDouble Integrals and Change of Order of IntegrationC.Lokesh Kumar100% (4)
- 06.derivarea Si Integrarea Datelor VectorialeDocument4 pages06.derivarea Si Integrarea Datelor VectorialeNelu CheluNo ratings yet
- Deep Regression EnsemblesDocument27 pagesDeep Regression EnsemblesDainXBNo ratings yet
- Lec 11: Linear Dimensionality Reduction: 11.33.1 Minimizing VarianceDocument3 pagesLec 11: Linear Dimensionality Reduction: 11.33.1 Minimizing VarianceshreNo ratings yet
- K0842000012015400304-05 Projective Geometry and Transformations of 3DDocument30 pagesK0842000012015400304-05 Projective Geometry and Transformations of 3DjeasdsdasdaNo ratings yet
- Principal Component AnalysisDocument16 pagesPrincipal Component AnalysisAdityaShekharNo ratings yet
- ECE232 DTFT PropertiesDocument1 pageECE232 DTFT PropertiesistegNo ratings yet
- 4-3 Gaussian Random VectorDocument20 pages4-3 Gaussian Random VectorTemp PersonNo ratings yet
- MATH 219: Fall 2018Document14 pagesMATH 219: Fall 2018Saad KhanNo ratings yet
- 10 Wave Equations 20 Sept 2016Document36 pages10 Wave Equations 20 Sept 2016Faisal Khotibul AmriNo ratings yet
- Successive Quadratic ProgrammingDocument33 pagesSuccessive Quadratic Programmingsathish22No ratings yet
- Mathematical Economics: 1 What To StudyDocument23 pagesMathematical Economics: 1 What To Studyjrvv2013gmailNo ratings yet
- Sta 301 NotesDocument9 pagesSta 301 NotesbaniNo ratings yet
- Indefinite Integration - Workbook Pattern 2Document10 pagesIndefinite Integration - Workbook Pattern 2Aniruddh GhewadeNo ratings yet
- FA Chap1 1-4Document4 pagesFA Chap1 1-4ThangNo ratings yet
- Longitudinal Vibration of A Bar ": Presentation OnDocument17 pagesLongitudinal Vibration of A Bar ": Presentation OnamitpatelNo ratings yet
- Chapter 02Document50 pagesChapter 02Jack Ignacio NahmíasNo ratings yet
- Lesson 8 VC.06 Day2Document16 pagesLesson 8 VC.06 Day2Sri RaghavanNo ratings yet
- PCA Dr. Pawan Kumar TiwariDocument19 pagesPCA Dr. Pawan Kumar TiwariRudrakshitaNo ratings yet
- Manifolds, Tensor Analysis and Applications, 3rd Ed - J E Marsden, T Ratiu, R Abraham, 2002 - Homework Sets & SolutionsDocument154 pagesManifolds, Tensor Analysis and Applications, 3rd Ed - J E Marsden, T Ratiu, R Abraham, 2002 - Homework Sets & SolutionsmiguelgomezleonNo ratings yet
- 17-18 Spring FinalDocument9 pages17-18 Spring FinalAmeer Hazim Ghazi Assa’dNo ratings yet
- Mathematical Association of AmericaDocument9 pagesMathematical Association of AmericathonguyenNo ratings yet
- Homework Assignment #2Document2 pagesHomework Assignment #2Snoop celevNo ratings yet
- Slide chpt04Document27 pagesSlide chpt04shambel kipNo ratings yet
- Appendix: Mathematical BackgroundDocument132 pagesAppendix: Mathematical BackgroundDominik SchmidtNo ratings yet
- MA 201: One Dimensional Wave Equation Lecture - 13Document16 pagesMA 201: One Dimensional Wave Equation Lecture - 13Sahrish AsifNo ratings yet
- Statistics For Applications 9: Principal Component Analysis (PCA)Document17 pagesStatistics For Applications 9: Principal Component Analysis (PCA)MateoQuiguiríNo ratings yet
- ECS171: Machine Learning: Lecture 3: Linear Models I (LFD 3.2, 3.3)Document48 pagesECS171: Machine Learning: Lecture 3: Linear Models I (LFD 3.2, 3.3)svwnerlgwrNo ratings yet
- I2ml3e Chap5Document26 pagesI2ml3e Chap5EMS Metalworking MachineryNo ratings yet
- Vu HPSC2012 02Document25 pagesVu HPSC2012 02Quốc Đông VũNo ratings yet
- 4 Spline MethodDocument29 pages4 Spline MethodEmdad HossainNo ratings yet
- Ma6468-Probability and Statistics Unit I - Random Variables Ma6468-Probability and Statistics Unit I - Random VariablesDocument110 pagesMa6468-Probability and Statistics Unit I - Random Variables Ma6468-Probability and Statistics Unit I - Random VariablesMahendran KNo ratings yet
- Linear Programming DualityDocument17 pagesLinear Programming DualityDr-Junaid ShajuNo ratings yet
- Dimension Reduction and Hidden Structure: 1.1 Principal Component Analysis (PCA)Document40 pagesDimension Reduction and Hidden Structure: 1.1 Principal Component Analysis (PCA)SNo ratings yet
- Advanced Quantum Mechanics, Fall 2017 Assignment 2 (Path Integrals in Quantum Mechanics)Document3 pagesAdvanced Quantum Mechanics, Fall 2017 Assignment 2 (Path Integrals in Quantum Mechanics)Anonymous tjckgoWNeNo ratings yet
- Variational Inference in Graphical Models: December 1, 2020Document77 pagesVariational Inference in Graphical Models: December 1, 2020GeelonSoNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- PDF EngDocument14 pagesPDF EngSgt HardanNo ratings yet
- Impact of Artificial Intelligence, Robotics, and Machine Learning On Sales and MarketingDocument3 pagesImpact of Artificial Intelligence, Robotics, and Machine Learning On Sales and MarketingNiel Frankluh ChavezNo ratings yet
- PDF 3Document4 pagesPDF 3TemesgenNo ratings yet
- Handbook of Big Data Analytics, - Vadlamani Ravi, Aswani Kumar ChV2Document419 pagesHandbook of Big Data Analytics, - Vadlamani Ravi, Aswani Kumar ChV2Huy Thông NguyễnNo ratings yet
- Cognates in SIDocument37 pagesCognates in SIJoanna SmithsonNo ratings yet
- AIA 6600 - Module 2Document6 pagesAIA 6600 - Module 2nwauzomakcNo ratings yet
- Support Vector Machine (SVM)Document2 pagesSupport Vector Machine (SVM)PAWAN TIWARINo ratings yet
- Assignment Week 4-Deep-Learning PDFDocument7 pagesAssignment Week 4-Deep-Learning PDFashish kumar100% (1)
- Jahiri PanaritDocument37 pagesJahiri Panarit0529ionutNo ratings yet
- Artificial Intelligence in FinanceDocument8 pagesArtificial Intelligence in FinancealainvaloisNo ratings yet
- Research 2Document48 pagesResearch 2ruadoanjeanette08No ratings yet
- Bugs in Our PocketsDocument46 pagesBugs in Our PocketscacaolesNo ratings yet
- Libro Nuevo MLDocument577 pagesLibro Nuevo MLSebastián Nicolás Jara CifuentesNo ratings yet
- Data Mining Classification and PredictionDocument17 pagesData Mining Classification and PredictionIT. ComNo ratings yet
- The Third Age of Artificial Intelligence: Field Actions Science ReportsDocument7 pagesThe Third Age of Artificial Intelligence: Field Actions Science ReportsThandolwetu SipuyeNo ratings yet
- AWS-IDC Executive Summary FinalDocument4 pagesAWS-IDC Executive Summary FinalzaaaawarNo ratings yet
- Department of Information Technology: SyllabusDocument38 pagesDepartment of Information Technology: SyllabusVaishnavi HatekarNo ratings yet
- Software Project Management: Assignment #1 (B)Document9 pagesSoftware Project Management: Assignment #1 (B)ammarNo ratings yet
- AAAI Poster TAC PDFDocument1 pageAAAI Poster TAC PDFSaikiran NaiduNo ratings yet
- Epid Klinik 6 ValiduitasDocument71 pagesEpid Klinik 6 ValiduitasHalim SyahrilNo ratings yet
- Top Links July 2018Document79 pagesTop Links July 2018Andrew Richard ThompsonNo ratings yet
- FulltextDocument123 pagesFulltextAAYUSH VARSHNEYNo ratings yet
- Enhancing The Government Accounting Information Sys - 2023 - International JournDocument19 pagesEnhancing The Government Accounting Information Sys - 2023 - International JournEllishya KhirudinNo ratings yet
- Six Steps To Master Machine Learning With Data PreparationDocument44 pagesSix Steps To Master Machine Learning With Data PreparationPoorna28No ratings yet
- Stock Market Prediction Using Machine Learning Classifiers and Social Media, NewsDocument24 pagesStock Market Prediction Using Machine Learning Classifiers and Social Media, NewsMarcus ViniciusNo ratings yet
- Python Self Study MaterialDocument9 pagesPython Self Study MaterialSrividhya ManikandanNo ratings yet
- Performance Analysis of Machine Learning Algorithms For Prediction of Liver DiseaseDocument7 pagesPerformance Analysis of Machine Learning Algorithms For Prediction of Liver DiseaseatpolankaraNo ratings yet
- KITL Legal Aspects of AI v. 3.0Document41 pagesKITL Legal Aspects of AI v. 3.0Shaima ShariffNo ratings yet
- ShashankDocument20 pagesShashankShashank K GNo ratings yet