Download as ppt, pdf, or txt
You might also like
- Assembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageFrom EverandAssembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageRating: 5 out of 5 stars5/5 (1)
- Still RX 60 80 Operator's ManualDocument372 pagesStill RX 60 80 Operator's ManualОлег Складремонт100% (1)
- SARMIENTO Lesson 3 Exercises Problem 1 - 1838923253Document3 pagesSARMIENTO Lesson 3 Exercises Problem 1 - 1838923253Leyzer MalumayNo ratings yet
- Endianness: Endian FirewallDocument13 pagesEndianness: Endian FirewallSumit KoleNo ratings yet
- EndiannessDocument14 pagesEndiannesssanchi.varmaNo ratings yet
- DDES Lecture 2 Computer OrganisationDocument40 pagesDDES Lecture 2 Computer OrganisationJanaka Chathuranga AbeywardenaNo ratings yet
- Architecture L1Document135 pagesArchitecture L1Aditya Chaudhary IIT MandiNo ratings yet
- Endianness: From Wikipedia, The Free EncyclopediaDocument8 pagesEndianness: From Wikipedia, The Free EncyclopediaAnderson Corrêa de MoraesNo ratings yet
- Intel ArchitectureDocument114 pagesIntel ArchitectureMd. Jahid HasanNo ratings yet
- ch2 PDFDocument66 pagesch2 PDFYousef MomaniNo ratings yet
- 06 Computer ArchitectureDocument4 pages06 Computer ArchitectureKhatia IvanovaNo ratings yet
- 1.1.1 (SL) Computer Architecture - Revision PackDocument29 pages1.1.1 (SL) Computer Architecture - Revision PackQWERTYNo ratings yet
- EndiannessDocument5 pagesEndiannessNandagopal SivakumarNo ratings yet
- Von Neuman Model-Part-1Document25 pagesVon Neuman Model-Part-1G.PranithaNo ratings yet
- Introduction To x64 AssemblyDocument13 pagesIntroduction To x64 AssemblyCristhofer Candia MamaniNo ratings yet
- Digital Assignment - 1 Microprocessor and InterfacingDocument5 pagesDigital Assignment - 1 Microprocessor and InterfacingYellow MoustacheNo ratings yet
- Characteristics of MicroprocessorsDocument12 pagesCharacteristics of Microprocessorscp3y2000-scribdNo ratings yet
- CS2100 Computer Organisation: MIPS ProgrammingDocument175 pagesCS2100 Computer Organisation: MIPS ProgrammingamandaNo ratings yet
- Microprocessor and Assembly Language Lecture Note For Ndii Computer EngineeringDocument25 pagesMicroprocessor and Assembly Language Lecture Note For Ndii Computer EngineeringAbdulhamid DaudaNo ratings yet
- Organization of MemoryDocument27 pagesOrganization of MemoryAlain Marvin Alon IlanoNo ratings yet
- KTMT HN - Ch05.assembly BasicsDocument21 pagesKTMT HN - Ch05.assembly BasicsNguyênNo ratings yet
- 3 Microprocessor 8086Document27 pages3 Microprocessor 8086Munazza FatmaNo ratings yet
- 1062 PDFDocument84 pages1062 PDFPrachi OberaiNo ratings yet
- Microprocessor 2Document24 pagesMicroprocessor 2Shehab KhaderNo ratings yet
- INTEL 8086 MicroprocessorDocument85 pagesINTEL 8086 MicroprocessorsaiNo ratings yet
- Microcontroller 8051Document31 pagesMicrocontroller 8051Munazza FatmaNo ratings yet
- Design of A General Purpose 8 Bit RISC Processor For Computer Architecture LearningDocument30 pagesDesign of A General Purpose 8 Bit RISC Processor For Computer Architecture LearningGuillermo Esqueda SilvaNo ratings yet
- 8086 Memory & Interfacing PDFDocument39 pages8086 Memory & Interfacing PDFAnnamalai SelvarajanNo ratings yet
- NasmDocument56 pagesNasmAbhijeet Gupta50% (2)
- MIPS 32 in BriefDocument29 pagesMIPS 32 in BriefPooja VashisthNo ratings yet
- AOR 2 (2) - PipeliningDocument43 pagesAOR 2 (2) - PipeliningVukan TaskovNo ratings yet
- Chapter-4A (Transforming Data Into Information)Document38 pagesChapter-4A (Transforming Data Into Information)api-3774277No ratings yet
- Computer Architecture I: Digital DesignDocument56 pagesComputer Architecture I: Digital DesignHari K Priya TirumalarajuNo ratings yet
- CHP 3 HoodDocument7 pagesCHP 3 Hoodmagesmail7563No ratings yet
- 32 BitDocument3 pages32 BitEdinen UdofiaNo ratings yet
- 8086 Microprocessor: J Srinivasa Rao Govt Polytechnic Kothagudem KhammamDocument129 pages8086 Microprocessor: J Srinivasa Rao Govt Polytechnic Kothagudem KhammamAnonymous J32rzNf6ONo ratings yet
- Ia OsDocument316 pagesIa OsIndium SmithNo ratings yet
- 06 Computer Architecture PDFDocument4 pages06 Computer Architecture PDFgparya009No ratings yet
- Nti C and Embedded C ContentsDocument8 pagesNti C and Embedded C ContentsMohamed Youssif FaroukNo ratings yet
- 18 Processor ArchitecturesDocument8 pages18 Processor ArchitecturesSreejith KarunakaranpillaiNo ratings yet
- Parallel Processing Chapter 1 2024Document22 pagesParallel Processing Chapter 1 2024Just SomeoneNo ratings yet
- Organisasi Sistem Komputer: Bahrin Dahlan., S.Kom.,MtDocument19 pagesOrganisasi Sistem Komputer: Bahrin Dahlan., S.Kom.,MtwilyantoNo ratings yet
- Introduction To x64 AssemblyDocument13 pagesIntroduction To x64 AssemblyriverajluizNo ratings yet
- Simulation and Fpga ImplementationDocument8 pagesSimulation and Fpga ImplementationToon ManNo ratings yet
- Computer Peripherals & InterfacingDocument128 pagesComputer Peripherals & InterfacingMd MianNo ratings yet
- Microprocessor 8086 Cheat SheetDocument3 pagesMicroprocessor 8086 Cheat Sheetaziz ahmadNo ratings yet
- SIMD PresentationDocument28 pagesSIMD PresentationHuzaifaNo ratings yet
- Introduction To Microcontroller Architectures: Nithin S. EEE DeptDocument29 pagesIntroduction To Microcontroller Architectures: Nithin S. EEE DeptDave AssangeNo ratings yet
- Coa CT 1 QBDocument43 pagesCoa CT 1 QBNilesh bibhutiNo ratings yet
- Hsslive XI - ComputerScience ShortNotes - SajanMathew SignedDocument10 pagesHsslive XI - ComputerScience ShortNotes - SajanMathew SignedLiya Mariya SajiNo ratings yet
- MP PR - OR Question Bank (AutoRecovered)Document13 pagesMP PR - OR Question Bank (AutoRecovered)vaishnavisaraf303No ratings yet
- Escondo SG 2Document3 pagesEscondo SG 2Will Stephenson SyNo ratings yet
- CA231-Microprocessors and Its Applications Short AnswersDocument15 pagesCA231-Microprocessors and Its Applications Short Answersapi-3770232100% (3)
- Chapter 3.1.1 3.1.2Document53 pagesChapter 3.1.1 3.1.2zainlemonadeNo ratings yet
- Computer Organisation (Short Answers 2pm)Document3 pagesComputer Organisation (Short Answers 2pm)spacekiller98No ratings yet
- Memory Basics: Emt 235 Digital Electronic Principles 2Document58 pagesMemory Basics: Emt 235 Digital Electronic Principles 2gurdianskyNo ratings yet
- Cap 11 - RISC-V - Parte IDocument22 pagesCap 11 - RISC-V - Parte IGuidoNo ratings yet
- Fundamentals of Microcontroller & Its Application: Unit-IDocument19 pagesFundamentals of Microcontroller & Its Application: Unit-IRajan PatelNo ratings yet
- Mic ProjectDocument15 pagesMic Projectsudarshan sonawaneNo ratings yet
- Structure of Computer SystemsDocument37 pagesStructure of Computer SystemsPop RuxiNo ratings yet
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationFrom EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNo ratings yet
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960From EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960No ratings yet
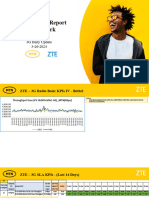
- ZTE MSOP Report - 3G Daily Update - 03262024Document5 pagesZTE MSOP Report - 3G Daily Update - 03262024olakunlea3185No ratings yet
- Exp 2.3 Java WSDocument4 pagesExp 2.3 Java WSmadhu jhaNo ratings yet
- G.a.drawing - Y-Gbv - 001 PDFDocument1 pageG.a.drawing - Y-Gbv - 001 PDFArman MominNo ratings yet
- Research Methodology and ProcedureDocument4 pagesResearch Methodology and ProcedureJhom Andrei ApolinarNo ratings yet
- Acceptance of Concrete Test ResultsDocument5 pagesAcceptance of Concrete Test ResultsMani Raj NNo ratings yet
- Calculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschDocument10 pagesCalculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschlapuNo ratings yet
- To The Learners: Consuelo M. Delima Elizabeth M. RuralDocument9 pagesTo The Learners: Consuelo M. Delima Elizabeth M. RuralMyla MillapreNo ratings yet
- Workmode API in FRUNDocument16 pagesWorkmode API in FRUNGuillaume LavoixNo ratings yet
- An Introduction to VR: Vincent 徐崇哲 Gdi Inc 上海曼恒数字Document32 pagesAn Introduction to VR: Vincent 徐崇哲 Gdi Inc 上海曼恒数字Vincent HsuNo ratings yet
- A Multilevel Consideration of Service Design ConditionsDocument24 pagesA Multilevel Consideration of Service Design ConditionsLiza LayaNo ratings yet
- Reference Manual: ADEPT Automatic Video Trackers Edition 4BDocument136 pagesReference Manual: ADEPT Automatic Video Trackers Edition 4Bing jya100% (1)
- Research Method in Technology (It542) Assignment 2 Section IiDocument14 pagesResearch Method in Technology (It542) Assignment 2 Section Iimelesse bisemaNo ratings yet
- Lecture 3 CADDocument10 pagesLecture 3 CADdesubie bireNo ratings yet
- WriteLikeAnArchitect Templates 201909A4Document6 pagesWriteLikeAnArchitect Templates 201909A4Nor Eddine BahhaNo ratings yet
- Edexcel IAL Pure Mathematics P4 June 2022 Wma14-01-Que-20220602Document32 pagesEdexcel IAL Pure Mathematics P4 June 2022 Wma14-01-Que-20220602Nikolas MarselliNo ratings yet
- Review On Different Types of DigesterDocument10 pagesReview On Different Types of Digestercharmy rockzz100% (1)
- 155 New Good Morning Images, Pictures & Photos Do 4Document8 pages155 New Good Morning Images, Pictures & Photos Do 4Aparna ParmarNo ratings yet
- Adidas ZDHC List Feb2017 FinalDocument28 pagesAdidas ZDHC List Feb2017 FinalRatu FirnaNo ratings yet
- Abrasive Jet Machining (AJM) : Unit 3Document54 pagesAbrasive Jet Machining (AJM) : Unit 3Satish SatiNo ratings yet
- Com Power Lvmkt215enDocument70 pagesCom Power Lvmkt215enCbdtxd PcbtrNo ratings yet
- Model Paralel ProsesorDocument12 pagesModel Paralel ProsesorKompetisi UI UXNo ratings yet
- Advantages and Disadvantages of Mobile PhonesDocument12 pagesAdvantages and Disadvantages of Mobile PhonesMuhammad QasimNo ratings yet
- CF-48H Technical DataDocument2 pagesCF-48H Technical DataromariozulistyaNo ratings yet
- Week 3, Nana KitiaDocument3 pagesWeek 3, Nana Kitiaნანა კიტიაNo ratings yet
- Open Document ArchitectureDocument1 pageOpen Document ArchitectureAdrian BermeaNo ratings yet
- Self Defending NetworksDocument10 pagesSelf Defending NetworksIJRASETPublicationsNo ratings yet
- 65B ApplicationDocument3 pages65B Applicationkanampalli1971No ratings yet