
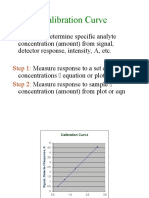
Risk
Risk
You might also like
- CQF Module 2 Examination: InstructionsDocument3 pagesCQF Module 2 Examination: InstructionsPrathameshSagareNo ratings yet
- Additional Exercises For Vectors, Matrices, and Least SquaresDocument41 pagesAdditional Exercises For Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraNo ratings yet
- Worksheet # 4 - SolutionDocument7 pagesWorksheet # 4 - Solutionahmed wahshaNo ratings yet
- George Stephanopoulos-Chemical Process Control - An Introduction To Theory and Practice (1984)Document358 pagesGeorge Stephanopoulos-Chemical Process Control - An Introduction To Theory and Practice (1984)Tina Dinh100% (1)
- CS137Part03 Floats Mathlib Root Finding PostDocument51 pagesCS137Part03 Floats Mathlib Root Finding PostNikunj JayasNo ratings yet
- Vmls - 103exercisesDocument50 pagesVmls - 103exercisessalnasuNo ratings yet
- Problem Set 1 Solution Numerical MethodsDocument32 pagesProblem Set 1 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- Unit1 Topic1 Digital Logic IntroductionDocument33 pagesUnit1 Topic1 Digital Logic IntroductionHari Kumar N CNo ratings yet
- MA122F23L10 SolnsDocument2 pagesMA122F23L10 Solnsyuxufk.004No ratings yet
- Assignment 12: Introduction To Machine Learning Prof. B. RavindranDocument4 pagesAssignment 12: Introduction To Machine Learning Prof. B. RavindranPraveen Kumar Kandhala100% (1)
- Tutorial Test 2016 Slot2+SolnDocument3 pagesTutorial Test 2016 Slot2+SolnKatitja MoleleNo ratings yet
- Research AssignmentDocument8 pagesResearch AssignmentAbdusalam IdirisNo ratings yet
- Assignment 3Document5 pagesAssignment 3Kalpit AgarwalNo ratings yet
- Quantitative Methods MM ZG515 / QM ZG515: L6: Probability DistributionsDocument22 pagesQuantitative Methods MM ZG515 / QM ZG515: L6: Probability DistributionsROHIT SINGHNo ratings yet
- Frequency Response and Bode PlotsDocument43 pagesFrequency Response and Bode Plotszulusiphosi9No ratings yet
- Homework 3 SolDocument3 pagesHomework 3 SolAlison LeeNo ratings yet
- Test02 2017 MemoDocument9 pagesTest02 2017 MemoMuzz HarryNo ratings yet
- 07au MidtermDocument17 pages07au MidtermEman AsemNo ratings yet
- FT Mba Section 4b Probability SvaDocument26 pagesFT Mba Section 4b Probability Svacons theNo ratings yet
- Tutorial 1Document21 pagesTutorial 1Amanda WangNo ratings yet
- MS Excel BiochemistryDocument5 pagesMS Excel BiochemistryMarie St. Louis100% (1)
- 154 Unstable Solutions of A Class of Hill Differential Equations HORVAY (1947)Document12 pages154 Unstable Solutions of A Class of Hill Differential Equations HORVAY (1947)Mariela TisseraNo ratings yet
- Mmte 007Document5 pagesMmte 007sonukonbir048No ratings yet
- DAA Unit 4Document24 pagesDAA Unit 4hari karanNo ratings yet
- Curves I: Curvature and TorsionDocument7 pagesCurves I: Curvature and TorsionAbdur Rauf AlamNo ratings yet
- Homework02 Withsolutions 1 PDFDocument5 pagesHomework02 Withsolutions 1 PDFVarmenUchihaNo ratings yet
- Transform Coding of Image Feature DescriptorsDocument9 pagesTransform Coding of Image Feature DescriptorsVarun PrakashNo ratings yet
- الواجب الأولDocument5 pagesالواجب الأولnawafNo ratings yet
- IIP Midterm SolDocument7 pagesIIP Midterm SolSacky SackNo ratings yet
- Mfin514 3 1Document18 pagesMfin514 3 1judbavNo ratings yet
- Lecture 2 Number SystemsDocument16 pagesLecture 2 Number Systems凌芷婕 LING ZHI JIE C44101175No ratings yet
- RintroDocument33 pagesRintroFranco CalleNo ratings yet
- Chapter 0 - Introduction To ComputingDocument43 pagesChapter 0 - Introduction To ComputingBuket CüvelenkNo ratings yet
- Lecture 6Document15 pagesLecture 6ZUHAL TUGRULNo ratings yet
- COE301 T232 Midterm Exam Key LatestDocument15 pagesCOE301 T232 Midterm Exam Key Latestb9lah10No ratings yet
- Final 2008 FDocument18 pagesFinal 2008 FMuhammad MurtazaNo ratings yet
- 1주차 강의자료Document31 pages1주차 강의자료ohjihun1028No ratings yet
- Calibration CurveDocument13 pagesCalibration Curvecinvehbi711No ratings yet
- Chapter Four: Curve FittingDocument58 pagesChapter Four: Curve FittingGirmole WorkuNo ratings yet
- Bacs HW2Document11 pagesBacs HW2brian2000890714No ratings yet
- Exam121022 SolDocument6 pagesExam121022 Solchiedzad madondoNo ratings yet
- L09 - Floating-Point & LogicDocument59 pagesL09 - Floating-Point & Logicitheachtholly1227No ratings yet
- Solving Equations 1.1 Bisection Method 1Document44 pagesSolving Equations 1.1 Bisection Method 1Raksmey SangNo ratings yet
- Precalculus q2 Module 3 FinalDocument17 pagesPrecalculus q2 Module 3 FinaldaniellerosedelossantosNo ratings yet
- Task 02: Example of Analysing Data and Residual Volatility and Estimating ARCH and GARCH ModelsDocument12 pagesTask 02: Example of Analysing Data and Residual Volatility and Estimating ARCH and GARCH ModelsJustina SasnauskaiteNo ratings yet
- Statap Practicetest 27Document7 pagesStatap Practicetest 27Hoa Dinh NguyenNo ratings yet
- Sol6 PDFDocument8 pagesSol6 PDFMichael ARKNo ratings yet
- CS 231A Computer Vision Midterm: 1 Multiple Choice (22 Points)Document20 pagesCS 231A Computer Vision Midterm: 1 Multiple Choice (22 Points)Goel MakagNo ratings yet
- Midterm SolutionDocument11 pagesMidterm Solutionfrozenfire310803No ratings yet
- Lecture 15 - Graph Data Structures and TraversalsDocument37 pagesLecture 15 - Graph Data Structures and TraversalsNovelyn RabinoNo ratings yet
- Digital Integrated Circuits: Traian Tulbure NII13Document55 pagesDigital Integrated Circuits: Traian Tulbure NII13boymatterNo ratings yet
- Probability Statistics and Random Processes For Engineers 4Th Edition Stark Solutions Manual Full Chapter PDFDocument46 pagesProbability Statistics and Random Processes For Engineers 4Th Edition Stark Solutions Manual Full Chapter PDFkarinawarrenpkmgsxdfrc100% (10)
- Probability Statistics and Random Processes For Engineers 4th Edition Stark Solutions ManualDocument38 pagesProbability Statistics and Random Processes For Engineers 4th Edition Stark Solutions Manualjacobdnjames100% (17)
- Complement G: One-Dimensional Gaussian Wave Packet: Spreading of The Wave PacketDocument16 pagesComplement G: One-Dimensional Gaussian Wave Packet: Spreading of The Wave PacketAntonio MarcosNo ratings yet
- Lecture 12Document20 pagesLecture 12ankiosaNo ratings yet
- Practical Solution of Partial Differential Equations in Finance PDFDocument27 pagesPractical Solution of Partial Differential Equations in Finance PDFyuzukiebaNo ratings yet
- Modeling and Simulation of RLC Circuit (Band Pass Filter)Document25 pagesModeling and Simulation of RLC Circuit (Band Pass Filter)elneelNo ratings yet
- HW 1Document3 pagesHW 1雷承慶No ratings yet
- Let's Practise: Maths Workbook Coursebook 6From EverandLet's Practise: Maths Workbook Coursebook 6No ratings yet
- Standard-Slope Integration: A New Approach to Numerical IntegrationFrom EverandStandard-Slope Integration: A New Approach to Numerical IntegrationNo ratings yet
- Let's Practise: Maths Workbook Coursebook 7From EverandLet's Practise: Maths Workbook Coursebook 7No ratings yet
- Lec14. Stacks, Queues, DequeDocument34 pagesLec14. Stacks, Queues, DequeMajd AL KawaasNo ratings yet
- Simplex Method in Tabular Form: Construct The Initial Simplex TableauDocument10 pagesSimplex Method in Tabular Form: Construct The Initial Simplex TableauSachin MailareNo ratings yet
- Monday 24 June 2019: Statistics S2Document24 pagesMonday 24 June 2019: Statistics S2Rahyan AshrafNo ratings yet
- Ruin Probability in A Threshold Insurance Risk Model: Isaac K. M. Kwan and Hailiang YangDocument9 pagesRuin Probability in A Threshold Insurance Risk Model: Isaac K. M. Kwan and Hailiang YangPetya ValchevaNo ratings yet
- Effects of Windowing On The Spectral Content of A Signal by P. WickramarachiDocument2 pagesEffects of Windowing On The Spectral Content of A Signal by P. Wickramarachikandela lightNo ratings yet
- 4 IIR Filter Design by YBP 22-09-2014Document69 pages4 IIR Filter Design by YBP 22-09-2014Pramiti ParasharNo ratings yet
- Control System Engineering - FinalDocument2 pagesControl System Engineering - FinalLuciferNo ratings yet
- MTech 2014 Full SyllabusDocument44 pagesMTech 2014 Full SyllabusanjanbsNo ratings yet
- NLP MCQsDocument15 pagesNLP MCQsKRISHNA TEJA K SNo ratings yet
- Digital Control: Mohammed Nour A. AhmedDocument20 pagesDigital Control: Mohammed Nour A. AhmedSamuel AdamuNo ratings yet
- Different Paradigms of Pattern RecognitionDocument8 pagesDifferent Paradigms of Pattern RecognitionAnkur KumarNo ratings yet
- CTV Extreme ValuesDocument8 pagesCTV Extreme ValuessumarjayaNo ratings yet
- 2Ch404-Chemical Engineering Thermodynamics: Tutorial-1 21BCH021Document6 pages2Ch404-Chemical Engineering Thermodynamics: Tutorial-1 21BCH021Harvin PatelNo ratings yet
- Uber Cracker SheetDocument39 pagesUber Cracker SheetAbhishek SoodNo ratings yet
- Preparing Grids For MAGMAP FFT ProcessingDocument8 pagesPreparing Grids For MAGMAP FFT ProcessingPratama AbimanyuNo ratings yet
- HaskellDocument15 pagesHaskellalxdanNo ratings yet
- 21 Yu2019Document5 pages21 Yu2019bukhtawar zamirNo ratings yet
- Minimum Mean Square Error EstimationDocument2 pagesMinimum Mean Square Error EstimationUpasana SaikiaNo ratings yet
- Quantitative Techniques For Managerial Decision - 1 (Qtmd1G21-1)Document26 pagesQuantitative Techniques For Managerial Decision - 1 (Qtmd1G21-1)banmaliNo ratings yet
- XII Determinants AssignmentDocument2 pagesXII Determinants AssignmentCRPF SchoolNo ratings yet
- Algoritmo Di Dijkstra - C++Document2 pagesAlgoritmo Di Dijkstra - C++Alex Michael Quintos PinedoNo ratings yet
- Video Steganography With Perturbed Motion EstimationDocument24 pagesVideo Steganography With Perturbed Motion EstimationkrishnithyanNo ratings yet
- HW 3Document3 pagesHW 3Ashley FullerNo ratings yet
- Fundamental Simulation Concepts (Chapter 2)Document46 pagesFundamental Simulation Concepts (Chapter 2)Yến Oanh Nguyễn LêNo ratings yet
- 2 NACAWingTutorialDocument16 pages2 NACAWingTutorialJesthyn VCNo ratings yet
- Cryptography Engineering: CSIC30040 Spring 2023 Lecture 6Document218 pagesCryptography Engineering: CSIC30040 Spring 2023 Lecture 6王皓平No ratings yet
- Recursion and Recursively Defined Geometry Objects - COMSOL BlogDocument10 pagesRecursion and Recursively Defined Geometry Objects - COMSOL BlogSumanth KoyilakondaNo ratings yet
- Day10 Mathematical FoundationsDocument4 pagesDay10 Mathematical FoundationskishnaNo ratings yet
- A Novel Technique For Cardiac Arrhythmia Classification Using Spectral Correlation and Support Vector MachinesDocument8 pagesA Novel Technique For Cardiac Arrhythmia Classification Using Spectral Correlation and Support Vector MachinesBruno LeppeNo ratings yet
























































































Download as pptx, pdf, or txt
You might also like
- CQF Module 2 Examination: InstructionsDocument3 pagesCQF Module 2 Examination: InstructionsPrathameshSagareNo ratings yet
- Additional Exercises For Vectors, Matrices, and Least SquaresDocument41 pagesAdditional Exercises For Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraNo ratings yet
- Worksheet # 4 - SolutionDocument7 pagesWorksheet # 4 - Solutionahmed wahshaNo ratings yet
- George Stephanopoulos-Chemical Process Control - An Introduction To Theory and Practice (1984)Document358 pagesGeorge Stephanopoulos-Chemical Process Control - An Introduction To Theory and Practice (1984)Tina Dinh100% (1)
- CS137Part03 Floats Mathlib Root Finding PostDocument51 pagesCS137Part03 Floats Mathlib Root Finding PostNikunj JayasNo ratings yet
- Vmls - 103exercisesDocument50 pagesVmls - 103exercisessalnasuNo ratings yet
- Problem Set 1 Solution Numerical MethodsDocument32 pagesProblem Set 1 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- Unit1 Topic1 Digital Logic IntroductionDocument33 pagesUnit1 Topic1 Digital Logic IntroductionHari Kumar N CNo ratings yet
- MA122F23L10 SolnsDocument2 pagesMA122F23L10 Solnsyuxufk.004No ratings yet
- Assignment 12: Introduction To Machine Learning Prof. B. RavindranDocument4 pagesAssignment 12: Introduction To Machine Learning Prof. B. RavindranPraveen Kumar Kandhala100% (1)
- Tutorial Test 2016 Slot2+SolnDocument3 pagesTutorial Test 2016 Slot2+SolnKatitja MoleleNo ratings yet
- Research AssignmentDocument8 pagesResearch AssignmentAbdusalam IdirisNo ratings yet
- Assignment 3Document5 pagesAssignment 3Kalpit AgarwalNo ratings yet
- Quantitative Methods MM ZG515 / QM ZG515: L6: Probability DistributionsDocument22 pagesQuantitative Methods MM ZG515 / QM ZG515: L6: Probability DistributionsROHIT SINGHNo ratings yet
- Frequency Response and Bode PlotsDocument43 pagesFrequency Response and Bode Plotszulusiphosi9No ratings yet
- Homework 3 SolDocument3 pagesHomework 3 SolAlison LeeNo ratings yet
- Test02 2017 MemoDocument9 pagesTest02 2017 MemoMuzz HarryNo ratings yet
- 07au MidtermDocument17 pages07au MidtermEman AsemNo ratings yet
- FT Mba Section 4b Probability SvaDocument26 pagesFT Mba Section 4b Probability Svacons theNo ratings yet
- Tutorial 1Document21 pagesTutorial 1Amanda WangNo ratings yet
- MS Excel BiochemistryDocument5 pagesMS Excel BiochemistryMarie St. Louis100% (1)
- 154 Unstable Solutions of A Class of Hill Differential Equations HORVAY (1947)Document12 pages154 Unstable Solutions of A Class of Hill Differential Equations HORVAY (1947)Mariela TisseraNo ratings yet
- Mmte 007Document5 pagesMmte 007sonukonbir048No ratings yet
- DAA Unit 4Document24 pagesDAA Unit 4hari karanNo ratings yet
- Curves I: Curvature and TorsionDocument7 pagesCurves I: Curvature and TorsionAbdur Rauf AlamNo ratings yet
- Homework02 Withsolutions 1 PDFDocument5 pagesHomework02 Withsolutions 1 PDFVarmenUchihaNo ratings yet
- Transform Coding of Image Feature DescriptorsDocument9 pagesTransform Coding of Image Feature DescriptorsVarun PrakashNo ratings yet
- الواجب الأولDocument5 pagesالواجب الأولnawafNo ratings yet
- IIP Midterm SolDocument7 pagesIIP Midterm SolSacky SackNo ratings yet
- Mfin514 3 1Document18 pagesMfin514 3 1judbavNo ratings yet
- Lecture 2 Number SystemsDocument16 pagesLecture 2 Number Systems凌芷婕 LING ZHI JIE C44101175No ratings yet
- RintroDocument33 pagesRintroFranco CalleNo ratings yet
- Chapter 0 - Introduction To ComputingDocument43 pagesChapter 0 - Introduction To ComputingBuket CüvelenkNo ratings yet
- Lecture 6Document15 pagesLecture 6ZUHAL TUGRULNo ratings yet
- COE301 T232 Midterm Exam Key LatestDocument15 pagesCOE301 T232 Midterm Exam Key Latestb9lah10No ratings yet
- Final 2008 FDocument18 pagesFinal 2008 FMuhammad MurtazaNo ratings yet
- 1주차 강의자료Document31 pages1주차 강의자료ohjihun1028No ratings yet
- Calibration CurveDocument13 pagesCalibration Curvecinvehbi711No ratings yet
- Chapter Four: Curve FittingDocument58 pagesChapter Four: Curve FittingGirmole WorkuNo ratings yet
- Bacs HW2Document11 pagesBacs HW2brian2000890714No ratings yet
- Exam121022 SolDocument6 pagesExam121022 Solchiedzad madondoNo ratings yet
- L09 - Floating-Point & LogicDocument59 pagesL09 - Floating-Point & Logicitheachtholly1227No ratings yet
- Solving Equations 1.1 Bisection Method 1Document44 pagesSolving Equations 1.1 Bisection Method 1Raksmey SangNo ratings yet
- Precalculus q2 Module 3 FinalDocument17 pagesPrecalculus q2 Module 3 FinaldaniellerosedelossantosNo ratings yet
- Task 02: Example of Analysing Data and Residual Volatility and Estimating ARCH and GARCH ModelsDocument12 pagesTask 02: Example of Analysing Data and Residual Volatility and Estimating ARCH and GARCH ModelsJustina SasnauskaiteNo ratings yet
- Statap Practicetest 27Document7 pagesStatap Practicetest 27Hoa Dinh NguyenNo ratings yet
- Sol6 PDFDocument8 pagesSol6 PDFMichael ARKNo ratings yet
- CS 231A Computer Vision Midterm: 1 Multiple Choice (22 Points)Document20 pagesCS 231A Computer Vision Midterm: 1 Multiple Choice (22 Points)Goel MakagNo ratings yet
- Midterm SolutionDocument11 pagesMidterm Solutionfrozenfire310803No ratings yet
- Lecture 15 - Graph Data Structures and TraversalsDocument37 pagesLecture 15 - Graph Data Structures and TraversalsNovelyn RabinoNo ratings yet
- Digital Integrated Circuits: Traian Tulbure NII13Document55 pagesDigital Integrated Circuits: Traian Tulbure NII13boymatterNo ratings yet
- Probability Statistics and Random Processes For Engineers 4Th Edition Stark Solutions Manual Full Chapter PDFDocument46 pagesProbability Statistics and Random Processes For Engineers 4Th Edition Stark Solutions Manual Full Chapter PDFkarinawarrenpkmgsxdfrc100% (10)
- Probability Statistics and Random Processes For Engineers 4th Edition Stark Solutions ManualDocument38 pagesProbability Statistics and Random Processes For Engineers 4th Edition Stark Solutions Manualjacobdnjames100% (17)
- Complement G: One-Dimensional Gaussian Wave Packet: Spreading of The Wave PacketDocument16 pagesComplement G: One-Dimensional Gaussian Wave Packet: Spreading of The Wave PacketAntonio MarcosNo ratings yet
- Lecture 12Document20 pagesLecture 12ankiosaNo ratings yet
- Practical Solution of Partial Differential Equations in Finance PDFDocument27 pagesPractical Solution of Partial Differential Equations in Finance PDFyuzukiebaNo ratings yet
- Modeling and Simulation of RLC Circuit (Band Pass Filter)Document25 pagesModeling and Simulation of RLC Circuit (Band Pass Filter)elneelNo ratings yet
- HW 1Document3 pagesHW 1雷承慶No ratings yet
- Let's Practise: Maths Workbook Coursebook 6From EverandLet's Practise: Maths Workbook Coursebook 6No ratings yet
- Standard-Slope Integration: A New Approach to Numerical IntegrationFrom EverandStandard-Slope Integration: A New Approach to Numerical IntegrationNo ratings yet
- Let's Practise: Maths Workbook Coursebook 7From EverandLet's Practise: Maths Workbook Coursebook 7No ratings yet
- Lec14. Stacks, Queues, DequeDocument34 pagesLec14. Stacks, Queues, DequeMajd AL KawaasNo ratings yet
- Simplex Method in Tabular Form: Construct The Initial Simplex TableauDocument10 pagesSimplex Method in Tabular Form: Construct The Initial Simplex TableauSachin MailareNo ratings yet
- Monday 24 June 2019: Statistics S2Document24 pagesMonday 24 June 2019: Statistics S2Rahyan AshrafNo ratings yet
- Ruin Probability in A Threshold Insurance Risk Model: Isaac K. M. Kwan and Hailiang YangDocument9 pagesRuin Probability in A Threshold Insurance Risk Model: Isaac K. M. Kwan and Hailiang YangPetya ValchevaNo ratings yet
- Effects of Windowing On The Spectral Content of A Signal by P. WickramarachiDocument2 pagesEffects of Windowing On The Spectral Content of A Signal by P. Wickramarachikandela lightNo ratings yet
- 4 IIR Filter Design by YBP 22-09-2014Document69 pages4 IIR Filter Design by YBP 22-09-2014Pramiti ParasharNo ratings yet
- Control System Engineering - FinalDocument2 pagesControl System Engineering - FinalLuciferNo ratings yet
- MTech 2014 Full SyllabusDocument44 pagesMTech 2014 Full SyllabusanjanbsNo ratings yet
- NLP MCQsDocument15 pagesNLP MCQsKRISHNA TEJA K SNo ratings yet
- Digital Control: Mohammed Nour A. AhmedDocument20 pagesDigital Control: Mohammed Nour A. AhmedSamuel AdamuNo ratings yet
- Different Paradigms of Pattern RecognitionDocument8 pagesDifferent Paradigms of Pattern RecognitionAnkur KumarNo ratings yet
- CTV Extreme ValuesDocument8 pagesCTV Extreme ValuessumarjayaNo ratings yet
- 2Ch404-Chemical Engineering Thermodynamics: Tutorial-1 21BCH021Document6 pages2Ch404-Chemical Engineering Thermodynamics: Tutorial-1 21BCH021Harvin PatelNo ratings yet
- Uber Cracker SheetDocument39 pagesUber Cracker SheetAbhishek SoodNo ratings yet
- Preparing Grids For MAGMAP FFT ProcessingDocument8 pagesPreparing Grids For MAGMAP FFT ProcessingPratama AbimanyuNo ratings yet
- HaskellDocument15 pagesHaskellalxdanNo ratings yet
- 21 Yu2019Document5 pages21 Yu2019bukhtawar zamirNo ratings yet
- Minimum Mean Square Error EstimationDocument2 pagesMinimum Mean Square Error EstimationUpasana SaikiaNo ratings yet
- Quantitative Techniques For Managerial Decision - 1 (Qtmd1G21-1)Document26 pagesQuantitative Techniques For Managerial Decision - 1 (Qtmd1G21-1)banmaliNo ratings yet
- XII Determinants AssignmentDocument2 pagesXII Determinants AssignmentCRPF SchoolNo ratings yet
- Algoritmo Di Dijkstra - C++Document2 pagesAlgoritmo Di Dijkstra - C++Alex Michael Quintos PinedoNo ratings yet
- Video Steganography With Perturbed Motion EstimationDocument24 pagesVideo Steganography With Perturbed Motion EstimationkrishnithyanNo ratings yet
- HW 3Document3 pagesHW 3Ashley FullerNo ratings yet
- Fundamental Simulation Concepts (Chapter 2)Document46 pagesFundamental Simulation Concepts (Chapter 2)Yến Oanh Nguyễn LêNo ratings yet
- 2 NACAWingTutorialDocument16 pages2 NACAWingTutorialJesthyn VCNo ratings yet
- Cryptography Engineering: CSIC30040 Spring 2023 Lecture 6Document218 pagesCryptography Engineering: CSIC30040 Spring 2023 Lecture 6王皓平No ratings yet
- Recursion and Recursively Defined Geometry Objects - COMSOL BlogDocument10 pagesRecursion and Recursively Defined Geometry Objects - COMSOL BlogSumanth KoyilakondaNo ratings yet
- Day10 Mathematical FoundationsDocument4 pagesDay10 Mathematical FoundationskishnaNo ratings yet
- A Novel Technique For Cardiac Arrhythmia Classification Using Spectral Correlation and Support Vector MachinesDocument8 pagesA Novel Technique For Cardiac Arrhythmia Classification Using Spectral Correlation and Support Vector MachinesBruno LeppeNo ratings yet