Download as pptx, pdf, or txt
You might also like
- Integrated Marketing Communications Strategic Planning 5th Edition - MARK 3340 Textbook 2Document476 pagesIntegrated Marketing Communications Strategic Planning 5th Edition - MARK 3340 Textbook 2kyrstyn86% (7)
- BSBWOR301 Organise Personal Work Priorities AnddevelopmentDocument155 pagesBSBWOR301 Organise Personal Work Priorities AnddevelopmentStavros NathanailNo ratings yet
- 120 DS-With AnswerDocument32 pages120 DS-With AnswerAsim Mazin100% (1)
- Machine Learning Interview Questions.Document43 pagesMachine Learning Interview Questions.hari krishna reddy100% (1)
- Decision TreesDocument16 pagesDecision TreesAsemSaleh100% (2)
- Mathematical ModellingDocument29 pagesMathematical ModellingSujith DeepakNo ratings yet
- Servant Leadership Questionnaire and Adaptive Leadership QuestionnaireDocument4 pagesServant Leadership Questionnaire and Adaptive Leadership Questionnaireapi-322248033No ratings yet
- Csa202 Unit 2Document36 pagesCsa202 Unit 2vbknukwcysgycpmlzsNo ratings yet
- ML3 - EvaluationDocument65 pagesML3 - Evaluationparam_email100% (1)
- Understanding The Bias-Variance TradeoffDocument8 pagesUnderstanding The Bias-Variance TradeoffVignesh SenthilNo ratings yet
- Theory in Machine LearningDocument47 pagesTheory in Machine LearningSreetam Ganguly100% (2)
- Bias and VarianceDocument36 pagesBias and VarianceSwapnil BeraNo ratings yet
- Variance and BiasDocument14 pagesVariance and Biasprakash.cse20No ratings yet
- 15-The Bias - Variance - Trade-Off-08-04-2024Document23 pages15-The Bias - Variance - Trade-Off-08-04-2024Keshav ChhapoliaNo ratings yet
- Regularization and BiasDocument13 pagesRegularization and BiasYadav YadvendraNo ratings yet
- Lecture 7Document19 pagesLecture 7huichloemailNo ratings yet
- Bias VarianceDocument19 pagesBias VarianceCrypto GeniusNo ratings yet
- 10 AI Success Metric and Performance IndicatorsDocument30 pages10 AI Success Metric and Performance IndicatorsShampa NasrinNo ratings yet
- Lec 3Document13 pagesLec 3ShubhamNo ratings yet
- Overfitting in Machine LearningDocument23 pagesOverfitting in Machine LearningFasiha ZahidNo ratings yet
- Exploring The ModelDocument13 pagesExploring The Modelsst sharunNo ratings yet
- I. Models and Cost Functions: ML NotationsDocument13 pagesI. Models and Cost Functions: ML Notationssst sharunNo ratings yet
- Data Analysis (27 Questions) : 1. (Given A Dataset) Analyze This Dataset and Tell Me What You Can Learn From ItDocument28 pagesData Analysis (27 Questions) : 1. (Given A Dataset) Analyze This Dataset and Tell Me What You Can Learn From Itkumar kumarNo ratings yet
- Theory in Machine LearningDocument60 pagesTheory in Machine LearningRivujit DasNo ratings yet
- Module0 IntroductionDocument27 pagesModule0 Introductionrohan kalidindiNo ratings yet
- Dimension ReductionDocument38 pagesDimension ReductionapurvaNo ratings yet
- Bias and VarianceDocument6 pagesBias and VariancePrashant SahuNo ratings yet
- Unit Online 1.4Document132 pagesUnit Online 1.4Nitesh SainiNo ratings yet
- Ensemble Learning MethodsDocument24 pagesEnsemble Learning Methodskhatri81100% (1)
- ML Lec-7Document12 pagesML Lec-7BHARGAV RAONo ratings yet
- Cross-Validation in Machine LearningDocument18 pagesCross-Validation in Machine LearningPriya dharshini.GNo ratings yet
- Machine Learning ModelsDocument52 pagesMachine Learning ModelsBharathNo ratings yet
- Machine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingDocument26 pagesMachine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingMd Fazle Rabby100% (2)
- Data Splitting and Bias Variance TradeoffDocument14 pagesData Splitting and Bias Variance TradeoffEileen LovegoodNo ratings yet
- Section 1: Cross-Validation and Model PerformanceDocument33 pagesSection 1: Cross-Validation and Model Performancechandreshpadmani9993No ratings yet
- CSL0777 L08Document29 pagesCSL0777 L08Konkobo Ulrich ArthurNo ratings yet
- Lecture 05: Feature Engineering: Ms. Mehroz SadiqDocument69 pagesLecture 05: Feature Engineering: Ms. Mehroz SadiquxamaNo ratings yet
- Merge +1Document107 pagesMerge +1SHIKHA SHARMANo ratings yet
- Regression PDFDocument33 pagesRegression PDF波唐No ratings yet
- Supervised Machine LearningDocument25 pagesSupervised Machine Learningsyedmar3297No ratings yet
- Bias Varience Trade OffDocument35 pagesBias Varience Trade Offmobeen100% (1)
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
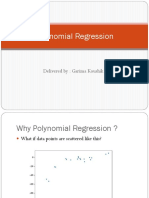
- Polynomial Regression: Delivered By: Garima KoushikDocument11 pagesPolynomial Regression: Delivered By: Garima KoushikGarima KaushikNo ratings yet
- Bias, Variance, and TradeoffDocument8 pagesBias, Variance, and Tradeoffhokijic810No ratings yet
- Bias and Variance in Machine LearningDocument7 pagesBias and Variance in Machine LearningSHIKHA SHARMANo ratings yet
- Churn Prediction ReportDocument4 pagesChurn Prediction ReportAuse ElNo ratings yet
- ML PDFDocument237 pagesML PDFKomi David ABOTSITSE100% (1)
- 02.data Preprocessing PDFDocument31 pages02.data Preprocessing PDFsunil100% (1)
- Kami Export - 13. Model EvaluationDocument25 pagesKami Export - 13. Model EvaluationYENI SRI MAHARANI -100% (1)
- 08 PracticalDocument24 pages08 Practical林山山No ratings yet
- Deep Learning (All in One)Document23 pagesDeep Learning (All in One)B BasitNo ratings yet
- CSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Document36 pagesCSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Being IITianNo ratings yet
- 8ad59658 1701235711480Document36 pages8ad59658 1701235711480kashyaputtam7No ratings yet
- Missing Data & How To Handle ItDocument32 pagesMissing Data & How To Handle ItGuja NagiNo ratings yet
- Model Selection: Dr.K.Murugan Assistant Professor Senior VIT, VelloreDocument35 pagesModel Selection: Dr.K.Murugan Assistant Professor Senior VIT, VelloreChidvi ReddyNo ratings yet
- Data Science Interview QuestionDocument23 pagesData Science Interview QuestionRoshan atulNo ratings yet
- Supervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuDocument32 pagesSupervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuMohammed Danlami Yusuf100% (1)
- Unit 2Document76 pagesUnit 221131A4232 CHUKKALA PRUDHVI RAJNo ratings yet
- Module 1 ML Mumbai UniversityDocument47 pagesModule 1 ML Mumbai University2021.shreya.pawaskarNo ratings yet
- Data Science Q&A - Latest Ed (2020) - 3 - 2Document2 pagesData Science Q&A - Latest Ed (2020) - 3 - 2M KNo ratings yet
- Choosing Model and TuningDocument20 pagesChoosing Model and Tuningkar20201214No ratings yet
- ML MU Unit 2Document84 pagesML MU Unit 2Paulos K100% (3)
- Readiness To Learn-LaudeDocument2 pagesReadiness To Learn-LaudeKathleen LaudeNo ratings yet
- Portfolio Section Three - Artifact SevenDocument6 pagesPortfolio Section Three - Artifact Sevenapi-419006824No ratings yet
- 63 - Ex 12B Distribution of Sample ProportionDocument12 pages63 - Ex 12B Distribution of Sample ProportionRalph Rezin MooreNo ratings yet
- Ace HRM ReportDocument32 pagesAce HRM ReportRajkishor YadavNo ratings yet
- Mullins L.J. Management and Organisational BehaviourDocument7 pagesMullins L.J. Management and Organisational Behaviourapi-2179215No ratings yet
- ResearchDocument14 pagesResearchFalo FayiaNo ratings yet
- Chicago Style Literature Review FormatDocument7 pagesChicago Style Literature Review Formatfihynakalej2100% (1)
- Samsung and IDP ModelDocument17 pagesSamsung and IDP ModelAnkush GuptaNo ratings yet
- ERC Data Collection Form For Intervention Reviews For RCTs Only 2Document9 pagesERC Data Collection Form For Intervention Reviews For RCTs Only 2Samreen JawaidNo ratings yet
- Graduate Seminar PresentationDocument17 pagesGraduate Seminar Presentationashebir abdoNo ratings yet
- Warren Practical Research FinalDocument13 pagesWarren Practical Research Finaldandoywarren46No ratings yet
- Zarei - 2016Document11 pagesZarei - 2016AMER MEHMOODNo ratings yet
- Exploring The Progression of Electronic Data Capture (EDC) in Clinical TrialsDocument5 pagesExploring The Progression of Electronic Data Capture (EDC) in Clinical TrialsClinical ResearchNo ratings yet
- Change Management Using AKDAR ModelDocument33 pagesChange Management Using AKDAR ModelNevets NonnacNo ratings yet
- Salvia Divinorum - Research Information Center PDFDocument622 pagesSalvia Divinorum - Research Information Center PDFShailesh GpNo ratings yet
- The ResearchDocument43 pagesThe ResearchronagishirlallynpfuentesNo ratings yet
- Primary Secondary and Tertiary Literature ReviewDocument8 pagesPrimary Secondary and Tertiary Literature ReviewjsmyxkvkgNo ratings yet
- Blockchain MarketDocument156 pagesBlockchain MarketSandeep BhagatNo ratings yet
- The Problem and Its SettingsDocument43 pagesThe Problem and Its SettingsPrince LanceNo ratings yet
- University of Surrey Thesis GuidelinesDocument8 pagesUniversity of Surrey Thesis Guidelinesezmrfsem100% (2)
- 13 Internal Audit-PrintedDocument9 pages13 Internal Audit-PrintedRii Edo SalNo ratings yet
- Sample of PHD Thesis PresentationDocument8 pagesSample of PHD Thesis PresentationSarah Morrow100% (2)
- Statistics P2 Sec B: MarkschemeDocument19 pagesStatistics P2 Sec B: MarkschemeDvay DvayNo ratings yet
- ISO 9001 - Awareness TrainingDocument27 pagesISO 9001 - Awareness TrainingKrunal Jani67% (3)
- Data Preparation: March 6, 2010Document17 pagesData Preparation: March 6, 2010Atisha JunejaNo ratings yet
- Mada Walabu UniversityDocument49 pagesMada Walabu UniversityAbreham AwokeNo ratings yet
- Animal Research Paper OutlineDocument4 pagesAnimal Research Paper Outlinevagipelez1z2100% (3)