Download as pptx, pdf, or txt
You might also like
- Organic Chemistry Board Exam QuestionsDocument10 pagesOrganic Chemistry Board Exam QuestionsRiza Joie Versales100% (1)
- One Day On The RoadDocument3 pagesOne Day On The RoadRichard Adam Sison74% (77)
- Machine Learning Lab Manual 06Document8 pagesMachine Learning Lab Manual 06Raheel Aslam100% (1)
- Black Drama Results: Act 1, Scene 1: Imprisonment of A ShadowDocument15 pagesBlack Drama Results: Act 1, Scene 1: Imprisonment of A Shadowjohn7tago100% (2)
- REGRESSIONDocument13 pagesREGRESSIONiemhardikNo ratings yet
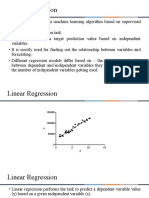
- Linear RegressionDocument36 pagesLinear RegressionSiddharth DoshiNo ratings yet
- INDUSTRY 2 AkshatDocument12 pagesINDUSTRY 2 AkshatKrish ParekhNo ratings yet
- 3 RegressionDocument23 pages3 RegressionJOJO100% (1)
- INDUSTRY 2 JaiminDocument14 pagesINDUSTRY 2 JaiminKrish ParekhNo ratings yet
- 1694600777-Unit2.2 Logistic Regression CU 2.0Document37 pages1694600777-Unit2.2 Logistic Regression CU 2.0prime9316586191100% (1)
- Logistic Regression AnalysisDocument16 pagesLogistic Regression AnalysisPIE TUTORSNo ratings yet
- Supply Chain PresentationDocument47 pagesSupply Chain PresentationosamaNo ratings yet
- 18EC56 Verilog HDL Module 3b 2020Document38 pages18EC56 Verilog HDL Module 3b 2020ece3a MITMNo ratings yet
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
- DMDW 5Document25 pagesDMDW 5Anu agarwalNo ratings yet
- Business Simulation - F2F 3Document27 pagesBusiness Simulation - F2F 3shiva kulshresthaNo ratings yet
- Supervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuDocument32 pagesSupervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuMohammed Danlami Yusuf100% (1)
- Regression in M.LDocument13 pagesRegression in M.LSaif JuttNo ratings yet
- E CommerceDocument20 pagesE CommerceChinmaya LenkaNo ratings yet
- Gradient Descent and Cost FunctionDocument14 pagesGradient Descent and Cost FunctionGaurav RautNo ratings yet
- ML - Unit 2Document155 pagesML - Unit 2cabhi7789No ratings yet
- Dimensionality ReductionDocument19 pagesDimensionality ReductionAtul PatilNo ratings yet
- 3-Logic RegressionDocument27 pages3-Logic RegressionsoniaNo ratings yet
- Machine Learning: Bilal KhanDocument20 pagesMachine Learning: Bilal KhanOsama Inayat100% (1)
- Basic Operation Research ModelDocument15 pagesBasic Operation Research ModelShebin ThampyNo ratings yet
- Real WorldDatabasePerformanceTechniquesDocument70 pagesReal WorldDatabasePerformanceTechniquesvaradhanpdyNo ratings yet
- Algorithms, Flowcharts & Program Design: ComproDocument39 pagesAlgorithms, Flowcharts & Program Design: Comprosudhakarm13No ratings yet
- Chapter Three Regression Network AnalysisDocument24 pagesChapter Three Regression Network AnalysisMohammed HuseiniNo ratings yet
- Types of Machine LearningDocument63 pagesTypes of Machine Learningwilliamkin14No ratings yet
- Chapter 1: Introduction To Results Postprocessing Results PostprocessingDocument49 pagesChapter 1: Introduction To Results Postprocessing Results PostprocessingarominorNo ratings yet
- Logistic RegressionDocument41 pagesLogistic RegressionSubodh KumarNo ratings yet
- Linear Regression - Jupyter NotebookDocument56 pagesLinear Regression - Jupyter NotebookUjwal Vajranabhaiah100% (3)
- Lecture 4Document33 pagesLecture 4Venkat ram ReddyNo ratings yet
- Integrated Supply Chain Analysis and Decision SupportDocument64 pagesIntegrated Supply Chain Analysis and Decision SupportNirav PatelNo ratings yet
- Regression With Panel DataDocument16 pagesRegression With Panel DataSudhansuSekharNo ratings yet
- Machine Learning PptsDocument38 pagesMachine Learning PptsSrujana PrasadiNo ratings yet
- UNIT-1 Regression vs. ClassificationDocument25 pagesUNIT-1 Regression vs. ClassificationHiiNo ratings yet
- Unit 7Document43 pagesUnit 7Yuvraj RanaNo ratings yet
- Data Science and Applications NotesDocument4 pagesData Science and Applications NotesShakil Reddy BhimavarapuNo ratings yet
- ML Hota Assign3Document4 pagesML Hota Assign3f20211088No ratings yet
- CSL0777 L17Document27 pagesCSL0777 L17Konkobo Ulrich ArthurNo ratings yet
- Module 4Document41 pagesModule 4beebeefathimabagum435No ratings yet
- Week 3Document2 pagesWeek 3MANISH PNo ratings yet
- MODULE 2 Deep LearningDocument26 pagesMODULE 2 Deep LearningENG20DS0040 SukruthaGNo ratings yet
- Feature Engineering For Machine LearningDocument41 pagesFeature Engineering For Machine LearningmngcezyvlmcpadgnpnNo ratings yet
- 02.data Preprocessing PDFDocument31 pages02.data Preprocessing PDFsunil100% (1)
- Batch Performance Analysis: Team BotsnbotsDocument14 pagesBatch Performance Analysis: Team BotsnbotsBhavishya GargNo ratings yet
- L 10 Principal Component Analysis 09052024 072206pmDocument37 pagesL 10 Principal Component Analysis 09052024 072206pmBahadar AyazNo ratings yet
- Week 15 21062021 030003pmDocument24 pagesWeek 15 21062021 030003pmMuhammad Abdul Rehman MustafaNo ratings yet
- Regression PPTDocument21 pagesRegression PPTRakesh bhukyaNo ratings yet
- Data Flow ModellingDocument55 pagesData Flow ModellingsruthiNo ratings yet
- ML NotesDocument14 pagesML NoteszomukozaNo ratings yet
- Accuracy Assessment and Confusion MatrixDocument23 pagesAccuracy Assessment and Confusion Matrixamrutamhetre9No ratings yet
- Concepts - Regression OverviewDocument14 pagesConcepts - Regression Overviewmtemp7489No ratings yet
- Unit IiiDocument27 pagesUnit Iiimahih16237No ratings yet
- DM Lab Cycle 2 1Document10 pagesDM Lab Cycle 2 1ispclxNo ratings yet
- Predicting ChurnDocument37 pagesPredicting ChurnSAHARUDIN BIN JAPARUDIN MoeNo ratings yet
- L4a - Supervised LearningDocument25 pagesL4a - Supervised LearningKinya KageniNo ratings yet
- Chapter 3 - DESCRIPTIVE ANALYSISDocument28 pagesChapter 3 - DESCRIPTIVE ANALYSISSimer FibersNo ratings yet
- Research Citation NotesDocument35 pagesResearch Citation NotesWeb Best WabiiNo ratings yet
- TIME SERIES FORECASTING. ARIMAX, ARCH AND GARCH MODELS FOR UNIVARIATE TIME SERIES ANALYSIS. Examples with MatlabFrom EverandTIME SERIES FORECASTING. ARIMAX, ARCH AND GARCH MODELS FOR UNIVARIATE TIME SERIES ANALYSIS. Examples with MatlabNo ratings yet
- Process Performance Models: Statistical, Probabilistic & SimulationFrom EverandProcess Performance Models: Statistical, Probabilistic & SimulationNo ratings yet
- Perception On CatcallingDocument19 pagesPerception On CatcallingJasmin Delos ReyesNo ratings yet
- 07 Hawt and VawtDocument10 pages07 Hawt and Vawtthisisanonymous6254No ratings yet
- METRIX AUTOCOMP - Company ProfileDocument2 pagesMETRIX AUTOCOMP - Company ProfileVaibhav AggarwalNo ratings yet
- Requirement and Specifications: Chapter - 3Document17 pagesRequirement and Specifications: Chapter - 3Chandrashekhar KuriNo ratings yet
- Dreams LuDocument325 pagesDreams Luscrib3030100% (1)
- Types of VolcanoesDocument10 pagesTypes of VolcanoesRobert MestiolaNo ratings yet
- Sensitive PracticeDocument122 pagesSensitive PracticeFederica FarfallaNo ratings yet
- What Is CommunicationDocument4 pagesWhat Is CommunicationsamsimNo ratings yet
- Jeab 1 PsDocument20 pagesJeab 1 PsDharmveer KumarNo ratings yet
- Lab 4 Intro To CSSDocument7 pagesLab 4 Intro To CSSMehwish PervaizNo ratings yet
- Walter2010 PDFDocument25 pagesWalter2010 PDFIpuk WidayantiNo ratings yet
- NSO Set-C Answer KeysDocument12 pagesNSO Set-C Answer KeysMota Chashma100% (1)
- Lab 4.2.3.3 Trace Internet ConnectivityDocument3 pagesLab 4.2.3.3 Trace Internet Connectivityonlycisco.tkNo ratings yet
- Technical InstructionsDocument6 pagesTechnical InstructionsSadinjana LakshanNo ratings yet
- Timeline Bendahara DesemberDocument2 pagesTimeline Bendahara DesemberSuci Ayu ChairunaNo ratings yet
- Solutions For The Extra Problems in Module 4Document3 pagesSolutions For The Extra Problems in Module 4Dev HalvawalaNo ratings yet
- JILG Students Learn by Serving Others.: Benton High School JILG ReportDocument4 pagesJILG Students Learn by Serving Others.: Benton High School JILG ReportjilgincNo ratings yet
- Lubricattng Oil For Marine EnginesDocument5 pagesLubricattng Oil For Marine Enginesemmsh71No ratings yet
- CDP+ Version 10 (Guide)Document124 pagesCDP+ Version 10 (Guide)Pew IcamenNo ratings yet
- Model QuestionsDocument27 pagesModel Questionskalyan555No ratings yet
- Importing Google Earth Data Into A GISDocument15 pagesImporting Google Earth Data Into A GISJONAMNo ratings yet
- Complete Research Ch1 5Document57 pagesComplete Research Ch1 5Angelie Regie J EstorqueNo ratings yet
- Title Business Partner Number Bus Part Cat Business Partner Role Category Business Partner GroupingDocument16 pagesTitle Business Partner Number Bus Part Cat Business Partner Role Category Business Partner GroupingRanjeet KumarNo ratings yet
- Vijaya DairyDocument65 pagesVijaya DairyAjay KumarNo ratings yet
- Using Powerpoint Effectively in Your PresentationDocument5 pagesUsing Powerpoint Effectively in Your PresentationEl Habib BidahNo ratings yet
- Liebherr Brochure Boom Pumps enDocument20 pagesLiebherr Brochure Boom Pumps enVikash PanditNo ratings yet
- Japanese TrifectaDocument9 pagesJapanese TrifectaJustin Lloyd FloroNo ratings yet