Download as ppt, pdf, or txt
You might also like
- Bimm143 FindageneprojectfinalDocument15 pagesBimm143 Findageneprojectfinalapi-583354477No ratings yet
- BPCL Case StudyDocument10 pagesBPCL Case StudyRimjhim ShrivastavaNo ratings yet
- Training 2021 - APACDocument204 pagesTraining 2021 - APACAlbert Nguyen100% (2)
- Electronic Service ToolDocument199 pagesElectronic Service ToolEzequiel ZetaNo ratings yet
- Travel Project: The Sixth Century B.C.E. (Marcuse 197)Document3 pagesTravel Project: The Sixth Century B.C.E. (Marcuse 197)Daisy SandersNo ratings yet
- Lecture 1&2Document46 pagesLecture 1&2powerites009No ratings yet
- Week 11 Data AnalyticsDocument36 pagesWeek 11 Data AnalyticsJoya Labao Macario-BalquinNo ratings yet
- PDF DocumentDocument41 pagesPDF DocumentShane HunterNo ratings yet
- DKP Advanced Excel and R - Session 1-2Document52 pagesDKP Advanced Excel and R - Session 1-2kanika gargNo ratings yet
- Evans Analytics2e PPT 01Document48 pagesEvans Analytics2e PPT 01Thanh TrucNo ratings yet
- Source: Books by Tan, Steinbach, Kumar Han, Kamber & Pei Evans Dinesh Kumar + Experiential KnowledgeDocument31 pagesSource: Books by Tan, Steinbach, Kumar Han, Kamber & Pei Evans Dinesh Kumar + Experiential KnowledgeGaurav BeniwalNo ratings yet
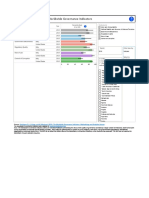
- Graph ViewDocument1 pageGraph Viewapi-348431251No ratings yet
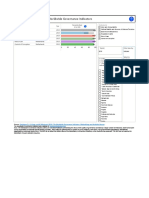
- Graph ViewDocument1 pageGraph Viewapi-348434437No ratings yet
- Lect-1 PPT - 01Document40 pagesLect-1 PPT - 01Usama NajamNo ratings yet
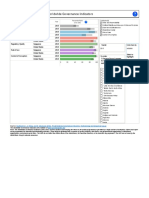
- Worl Dwi de Governance I Ndi Cators: Per Cent I L e RankDocument1 pageWorl Dwi de Governance I Ndi Cators: Per Cent I L e Rankapi-348334596No ratings yet
- Seismic Bracing Catalog Isatphd - Cable Electrical For TenderDocument16 pagesSeismic Bracing Catalog Isatphd - Cable Electrical For TenderArif RusyanaNo ratings yet
- Fbana 1Document19 pagesFbana 1Puti TaeNo ratings yet
- Graph ViewDocument1 pageGraph Viewapi-348431301No ratings yet
- DWX 2018 Survey PDFDocument25 pagesDWX 2018 Survey PDFyasirNo ratings yet
- Lesson 9 - Business Growth 2 1Document20 pagesLesson 9 - Business Growth 2 1herrannicNo ratings yet
- Climathon Generic Flyer2017Document4 pagesClimathon Generic Flyer2017Hans uelNo ratings yet
- Surface TensionDocument15 pagesSurface TensionGregNo ratings yet
- PDF Line Pipes Factory Acceptance Test Checklist - CompressDocument1 pagePDF Line Pipes Factory Acceptance Test Checklist - CompressTùng ĐặngNo ratings yet
- Sim ResultDocument1 pageSim ResultHeizyl ann VelascoNo ratings yet
- Simatic Pcs Neo v4 0 Flyer enDocument1 pageSimatic Pcs Neo v4 0 Flyer enFinito TheEndNo ratings yet
- Practical Statistical Signal Processing Using MATLABDocument31 pagesPractical Statistical Signal Processing Using MATLABalexverde3No ratings yet
- Efect GubernDocument1 pageEfect Gubernjuan jesus castro abadNo ratings yet
- AP Guides1Document388 pagesAP Guides1chandan_infotech100% (1)
- Good Practice Guide 272 - Lighting For PeopleDocument22 pagesGood Practice Guide 272 - Lighting For Peopletreelam100% (1)
- Third Quarter Update ReviewDocument26 pagesThird Quarter Update Reviewelong3102No ratings yet
- Oracle BI Publisher 11g R1 Fundamentals (Student Guide - Volume I) (101-200) PDFDocument100 pagesOracle BI Publisher 11g R1 Fundamentals (Student Guide - Volume I) (101-200) PDFangel_ceruz20No ratings yet
- Job Situation in The Recession: April 2009Document34 pagesJob Situation in The Recession: April 2009Khawaja_FaisalNo ratings yet
- StorageDocument7 pagesStorageMohamed SolimanNo ratings yet
- User Manual Oracle Banking Digital Experience Retail Peer To PeerDocument146 pagesUser Manual Oracle Banking Digital Experience Retail Peer To PeerSoll HaileNo ratings yet
- Complete Green Item FileDocument196 pagesComplete Green Item FileExecutive Computer ProductsNo ratings yet
- Cisco 827 Router Cabling and Setup Quick Start Guide: Parts ListDocument12 pagesCisco 827 Router Cabling and Setup Quick Start Guide: Parts ListCarlos Alberto Paez TNo ratings yet
- Big Data D86898GC10 Sg2Document446 pagesBig Data D86898GC10 Sg2Mohamed FathallahNo ratings yet
- Audit ProceduresDocument3 pagesAudit ProceduresOkasha AliNo ratings yet
- Thai 11203514 AsmDocument22 pagesThai 11203514 AsmThái TranNo ratings yet
- Vi Vekanandacol L Egeofengi Neer I Ng&Technol OgyDocument2 pagesVi Vekanandacol L Egeofengi Neer I Ng&Technol OgySushanth PoojaryNo ratings yet
- Raci Matrix TemplateDocument10 pagesRaci Matrix TemplateAbdiel RiveraNo ratings yet
- Control Objectives: Information CriteriaDocument32 pagesControl Objectives: Information Criteriasekoy20122827No ratings yet
- Cobit ModelDocument32 pagesCobit Modelsekoy20122827No ratings yet
- TCM Forklifts Range BrochureDocument4 pagesTCM Forklifts Range BrochureGeorge YapNo ratings yet
- Devil's Staircase WildernessDocument1 pageDevil's Staircase WildernessStatesman JournalNo ratings yet
- Session 1 SVDocument50 pagesSession 1 SVfelinethienpontNo ratings yet
- APEX Rev 02B EntireDocument133 pagesAPEX Rev 02B EntirePiman MiriNo ratings yet
- Chart Title: Complaint Type No: of Complaints % Cumulative %Document2 pagesChart Title: Complaint Type No: of Complaints % Cumulative %Blossom KaurNo ratings yet
- Value Innovation and Blue Oceans: Andrea TracognaDocument9 pagesValue Innovation and Blue Oceans: Andrea TracognaNandar Swe TintNo ratings yet
- Big Data D86898GC10 Sg1Document436 pagesBig Data D86898GC10 Sg1Mohamed FathallahNo ratings yet
- Chap - 1 - Data AnalyticsDocument29 pagesChap - 1 - Data Analyticsjoumana.r.daherNo ratings yet
- Mymulti Fare MapDocument1 pageMymulti Fare MapanandnagsNo ratings yet
- Channel Performance TrackerDocument91 pagesChannel Performance TrackerMuhammad ReyhanNo ratings yet
- Route 292 6 22 03 MAPDocument1 pageRoute 292 6 22 03 MAPJason BentleyNo ratings yet
- Rnug Domino On DockerDocument46 pagesRnug Domino On DockerPIngNo ratings yet
- Itil-213 8.03 Eng Learnit Ifo IsDocument322 pagesItil-213 8.03 Eng Learnit Ifo IscskijanjeNo ratings yet
- Protemoi ListDocument2 pagesProtemoi ListTrần HuyNo ratings yet
- Chapter 3 LedgerDocument86 pagesChapter 3 LedgerrhapsodizenNo ratings yet
- Kristopher Otis-Hayward: TIJ1O1Document1 pageKristopher Otis-Hayward: TIJ1O1krishayward08No ratings yet
- C5 Data GatheringDocument13 pagesC5 Data GatheringWilson LimNo ratings yet
- SQL2Document22 pagesSQL2Lakshmi Bhramara Mutte AP21111200002No ratings yet
- Cloud Computing Case StudyDocument4 pagesCloud Computing Case StudySherlin BrittoNo ratings yet
- HIM Evidence-Based Operations PDFDocument5 pagesHIM Evidence-Based Operations PDFGladstone SamuelNo ratings yet
- Concept: Central Vendor Data Migration ApproachDocument4 pagesConcept: Central Vendor Data Migration Approachnileshgupta11112756No ratings yet
- ACN3511-course ContentDocument3 pagesACN3511-course ContentXin TungNo ratings yet
- A New Approach For Data Conversion From CAD To GISDocument8 pagesA New Approach For Data Conversion From CAD To GIShosam shokriNo ratings yet
- 8 Graphs and Charts As InfographicsDocument29 pages8 Graphs and Charts As InfographicsAngel CahiligNo ratings yet
- JAVA Development: Databases - SQLDocument38 pagesJAVA Development: Databases - SQLCosmin GrosuNo ratings yet
- Citation & Referencing ToolsDocument42 pagesCitation & Referencing ToolsMohamedNo ratings yet
- Practice Transactions CC SolDocument7 pagesPractice Transactions CC Solbilo044No ratings yet
- Data Science in Meteorology - Weather Forecast: S.Y. Mechanical DepartmentDocument25 pagesData Science in Meteorology - Weather Forecast: S.Y. Mechanical DepartmentcapNo ratings yet
- The NASA Astrophysics Data System: Overview: Astronomy and Astrophysics Supplement Series February 2000Document20 pagesThe NASA Astrophysics Data System: Overview: Astronomy and Astrophysics Supplement Series February 2000Arthur WalkerNo ratings yet
- GIS Based Projects Information System For ConstrucDocument11 pagesGIS Based Projects Information System For ConstrucAvadesh palNo ratings yet
- WIF2003 Team Project Report Guidelines 2019Document3 pagesWIF2003 Team Project Report Guidelines 2019Callme E-oneNo ratings yet
- DBDM 16 Marks All 5 UnitsDocument74 pagesDBDM 16 Marks All 5 Unitsathirayan85No ratings yet
- Project Proposal: Library Management SystemDocument8 pagesProject Proposal: Library Management SystemAmogh MaxNo ratings yet
- Dbms Mini Project TemplateDocument8 pagesDbms Mini Project TemplateRuheena SNo ratings yet
- Conceptual FrameworkDocument4 pagesConceptual FrameworkKaren AlbaricoNo ratings yet
- Tourism TicsDocument355 pagesTourism TicsVasiliniuc IonutNo ratings yet
- SQL Technical INterview PDFDocument13 pagesSQL Technical INterview PDFGuru100% (1)
- Week 1 Analytics in PracticeDocument12 pagesWeek 1 Analytics in Practicepalacpac jefferson100% (1)
- NCM 110 - Nursing InformaticsDocument2 pagesNCM 110 - Nursing InformaticsRANo ratings yet
- Introduction To SAP ERP: True-False QuestionsDocument4 pagesIntroduction To SAP ERP: True-False QuestionsDoan Thi Thanh ThuyNo ratings yet
- Pio KoreaDocument5 pagesPio KoreaKey Nie MayrindaNo ratings yet
- Applies To:: EBS Data Model Comparison Report Overview (VIDEO) (Doc ID 1290886.1)Document10 pagesApplies To:: EBS Data Model Comparison Report Overview (VIDEO) (Doc ID 1290886.1)herculean2010No ratings yet
- TR 3929Document10 pagesTR 3929hsnelNo ratings yet
- Correction Application in Birth Teor+certificateDocument3 pagesCorrection Application in Birth Teor+certificateParesh NaikNo ratings yet
- TVH Fuses - Fuse - HoldersDocument52 pagesTVH Fuses - Fuse - HoldersMelwyn FernandesNo ratings yet