
Chapter 1
Chapter 1
You might also like
- Modern JavaScript Learning Path 2020Document1 pageModern JavaScript Learning Path 2020Java ManNo ratings yet
- Customer Base Management NTCDocument12 pagesCustomer Base Management NTChanaaNo ratings yet
- CDSS Day-3Document207 pagesCDSS Day-3junitasariNo ratings yet
- POSTER - Laboratory Software That Connects To Your Labs EcosystemDocument1 pagePOSTER - Laboratory Software That Connects To Your Labs Ecosystemmicrobehunter007No ratings yet
- Invest IndiaDocument1 pageInvest IndiaKhushi BerryNo ratings yet
- 2018 KOREA PAVILION in TEXWORLD USADocument30 pages2018 KOREA PAVILION in TEXWORLD USAHelen Oh100% (1)
- Ashk Lawal - LinkedInDocument4 pagesAshk Lawal - LinkedInsrivatsaNo ratings yet
- Visit More Resumes at WWW Pages/resumes/resum Es - HTMLDocument7 pagesVisit More Resumes at WWW Pages/resumes/resum Es - HTMLAbde VilliersNo ratings yet
- Kmbit 04 Dbms Unit 5Document7 pagesKmbit 04 Dbms Unit 5Shruti NigamNo ratings yet
- ABC Rapid Prototyping Implementation Method Model No 0Document4 pagesABC Rapid Prototyping Implementation Method Model No 0Sağlık YönetimiNo ratings yet
- Vishnu CompressedDocument1 pageVishnu CompressedVichu DummyNo ratings yet
- Advanced Fixed Asset ReportingDocument28 pagesAdvanced Fixed Asset ReportingreymranNo ratings yet
- IS ModelDocument17 pagesIS Modelsoumys19No ratings yet
- Total Content Map SQLDocument1 pageTotal Content Map SQLGaurav SalunkheNo ratings yet
- The Difference Between Structured, Unstructured and Semi-Structured DataDocument2 pagesThe Difference Between Structured, Unstructured and Semi-Structured DataDivy PatelNo ratings yet
- CC Unit 4Document16 pagesCC Unit 4anishNo ratings yet
- DWM Unit 1Document20 pagesDWM Unit 1Mohan ganesh MothukuriNo ratings yet
- Taming Big DataDocument268 pagesTaming Big DatascottavedaNo ratings yet
- Chapter11 - Database ManagementDocument39 pagesChapter11 - Database ManagementXaronAngelNo ratings yet
- Principles of Data Management and Mining: CS 504 Spring 2020Document28 pagesPrinciples of Data Management and Mining: CS 504 Spring 2020bijaysubediNo ratings yet
- Taobao Case Study PDFDocument33 pagesTaobao Case Study PDFklarascomNo ratings yet
- Taobao Case Study PDFDocument33 pagesTaobao Case Study PDFAnonymous zpitrB80oNo ratings yet
- Hostel Management SystemDocument18 pagesHostel Management SystemNamrita Sundarraj50% (6)
- 2024 Meeting 1 - Data Warehouse FundamentalsDocument47 pages2024 Meeting 1 - Data Warehouse Fundamentalsu19236931No ratings yet
- Virtuoso Characterization Suite PDFDocument8 pagesVirtuoso Characterization Suite PDFtestNo ratings yet
- Welcome To IST 380 !: Data Science ProgrammingDocument73 pagesWelcome To IST 380 !: Data Science Programmingshabir AhmadNo ratings yet
- SImA 1.3 Customer Facing (HCS) DraftDocument17 pagesSImA 1.3 Customer Facing (HCS) DraftcloudsforestNo ratings yet
- Data Structures & Algorithms: Learn To Code Interactively Using Only Your Browser. Practice Labs and ProjectsDocument1 pageData Structures & Algorithms: Learn To Code Interactively Using Only Your Browser. Practice Labs and ProjectsAshish CharlesNo ratings yet
- TH Et Ea M: Ta Ba SeDocument24 pagesTH Et Ea M: Ta Ba SeSuchitraNo ratings yet
- Data WarehousingDocument48 pagesData WarehousingPravah ShuklaNo ratings yet
- LoC (Letter of Credit) EnhancementsDocument21 pagesLoC (Letter of Credit) EnhancementssomusatishNo ratings yet
- EIP Flashcards PDFDocument6 pagesEIP Flashcards PDFjimbeam2No ratings yet
- DBMS (Unit - 1)Document17 pagesDBMS (Unit - 1)divyanshi kansalNo ratings yet
- Lab3 Data EngineeringDocument12 pagesLab3 Data EngineeringTiagoNo ratings yet
- Dsbda Unit 1Document25 pagesDsbda Unit 1403 Chaudhari Sanika SagarNo ratings yet
- Data Structure PDFDocument1 pageData Structure PDFTHULASINo ratings yet
- BigStreamer For BankingDocument2 pagesBigStreamer For BankingPaulNo ratings yet
- MDG For Finance DeckDocument9 pagesMDG For Finance Deckrahul_agrawal165No ratings yet
- Status WFH / Wfo Process About Process Job Title Office LoctnDocument27 pagesStatus WFH / Wfo Process About Process Job Title Office LoctnNaik PremoNo ratings yet
- DBMS NotesDocument11 pagesDBMS NotesNikhilNo ratings yet
- Gadchiroli 5Document290 pagesGadchiroli 5Nilesh PathakNo ratings yet
- Toad Data Point Datasheet 68635 PDFDocument2 pagesToad Data Point Datasheet 68635 PDFAshrafulNo ratings yet
- Copy of DFD Diagram - Blank ERD & Data Flow PDFDocument1 pageCopy of DFD Diagram - Blank ERD & Data Flow PDFAnish YadavNo ratings yet
- Challenges and Applications of Large Language Models: Desi GN BehaviorDocument72 pagesChallenges and Applications of Large Language Models: Desi GN BehaviorAlex DiermeierNo ratings yet
- Lec 1 Part 2 XmindDocument1 pageLec 1 Part 2 XmindAhmad AbuelgasimNo ratings yet
- Information Related Specialistsv 8Document1 pageInformation Related Specialistsv 8Bob WigginsNo ratings yet
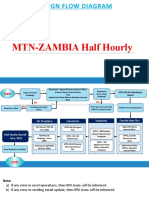
- Design Flow Diagram: MTN-ZAMBIA Half HourlyDocument3 pagesDesign Flow Diagram: MTN-ZAMBIA Half HourlyDhruvNo ratings yet
- Backup and Recovery Basics PresentationDocument15 pagesBackup and Recovery Basics PresentationyejrNo ratings yet
- Techlog Interactive Suite 2008.modulesDocument15 pagesTechlog Interactive Suite 2008.modulesari_si100% (5)
- BigStreamer CNEDocument2 pagesBigStreamer CNEPaulNo ratings yet
- 1 - Oracle Solution Intro BlackbeltDocument61 pages1 - Oracle Solution Intro BlackbeltWallace BandecoNo ratings yet
- Artificial Intelligence in Digital Marketing - Mind MapDocument1 pageArtificial Intelligence in Digital Marketing - Mind MapMilton Julián PulidoNo ratings yet
- Elec EstimatingDocument1 pageElec Estimatingrajesh0001No ratings yet
- Underpinning Methods, Procedure and ApplicationsDocument10 pagesUnderpinning Methods, Procedure and ApplicationsShivaun Seecharan0% (1)
- Data ScienceDocument20 pagesData Sciencemoshiul129No ratings yet
- Sap MM Interview 1673727260Document11 pagesSap MM Interview 1673727260kiadeNo ratings yet
- Person Just SW Alised Infor M IpeDocument1 pagePerson Just SW Alised Infor M Ipeapi-23629577No ratings yet
- Embedded - CO1Document124 pagesEmbedded - CO123mz02No ratings yet
- Data Centre ArchitectureDocument16 pagesData Centre Architecture23mz02No ratings yet
- 3.testing PrinciplesDocument20 pages3.testing Principles23mz02No ratings yet
- FUTURE - OF - MACHINE - LEARNING - IN - HEALTHCARE MeeDocument1 pageFUTURE - OF - MACHINE - LEARNING - IN - HEALTHCARE Mee23mz02No ratings yet
- Embedded System DesignDocument4 pagesEmbedded System Design23mz02No ratings yet
- 4th AIDocument12 pages4th AIPriyaNo ratings yet
- Almanca Dil Bilgisi Kılavuzu BaşlangıçtanDocument504 pagesAlmanca Dil Bilgisi Kılavuzu Başlangıçtanertan2002100% (2)
- Java ProgrammingDocument177 pagesJava ProgrammingVijayakumar SindhuNo ratings yet
- This Study Resource Was: Database Programming With PL/SQL 8-1: Practice ActivitiesDocument4 pagesThis Study Resource Was: Database Programming With PL/SQL 8-1: Practice ActivitiesGilang SaputraNo ratings yet
- Excel Data TableDocument4 pagesExcel Data TableClark DomingoNo ratings yet
- DBA Project L4Document3 pagesDBA Project L4SelamNo ratings yet
- Microsoft Software Assurance BenefitsDocument6 pagesMicrosoft Software Assurance BenefitsbrookptNo ratings yet
- Literature Review On Online Bus TicketingDocument4 pagesLiterature Review On Online Bus Ticketingfeiaozukg100% (1)
- Archmodels v003 PDFDocument5 pagesArchmodels v003 PDFMiguel PicoNo ratings yet
- User Experience Design Internship: Sahil KundalDocument15 pagesUser Experience Design Internship: Sahil KundalSahil KundalNo ratings yet
- 6GK72425DX300XE0 Datasheet enDocument2 pages6GK72425DX300XE0 Datasheet enxabsNo ratings yet
- SAF-T (RO) : Creation of Packages: SymptomDocument6 pagesSAF-T (RO) : Creation of Packages: SymptomLiviuNo ratings yet
- Class Vii Computer Annual Set II 2023 24Document3 pagesClass Vii Computer Annual Set II 2023 2471989No ratings yet
- Object Oriented MetricsDocument8 pagesObject Oriented Metricskamna1604No ratings yet
- Manuel - Zortrax M300Document50 pagesManuel - Zortrax M300Cédric SahiNo ratings yet
- Implementation of DDL CommandsDocument6 pagesImplementation of DDL Commandslaalan jiNo ratings yet
- 1337x.orgDocument10 pages1337x.orgsheetal2689100% (1)
- ET Quarter 3 Weeks 1 3Document11 pagesET Quarter 3 Weeks 1 3Steven Vic AlforqueNo ratings yet
- RUBRICS - Video EditingDocument1 pageRUBRICS - Video EditingMcheaven NojramNo ratings yet
- III Inserting Tiles: Important DataDocument4 pagesIII Inserting Tiles: Important DataJoshua IbrahimNo ratings yet
- Script To Gather OCFS2 Diagnostic InformationDocument3 pagesScript To Gather OCFS2 Diagnostic Informationelcaso34No ratings yet
- Class X 6-4-20Document3 pagesClass X 6-4-20AtanuBhandaryNo ratings yet
- Gujarat Technological UniversityDocument1 pageGujarat Technological UniversitybhavishwarikoooNo ratings yet
- Acx6160-Roadm Yang ModelDocument114 pagesAcx6160-Roadm Yang Modelhas samNo ratings yet
- POC Audit System - WalkthroughDocument45 pagesPOC Audit System - Walkthroughkeith tanuecoNo ratings yet
- 994-T012 REV A WS2000 E2A wTABSDocument141 pages994-T012 REV A WS2000 E2A wTABSblanoswa11No ratings yet
- Real Time Eeg Signal Processing Based On Ti S tms320c6713 DSKDocument9 pagesReal Time Eeg Signal Processing Based On Ti S tms320c6713 DSKkaoutarNo ratings yet
- Object Oriented Programming MCQsDocument33 pagesObject Oriented Programming MCQscute_12271% (7)
- Random NumbersDocument341 pagesRandom NumberskatovNo ratings yet
- AndroidRIL-SourceCode AppNote (UBX-13002041)Document46 pagesAndroidRIL-SourceCode AppNote (UBX-13002041)far.rhm2021No ratings yet



























































































Download as pptx, pdf, or txt
You might also like
- Modern JavaScript Learning Path 2020Document1 pageModern JavaScript Learning Path 2020Java ManNo ratings yet
- Customer Base Management NTCDocument12 pagesCustomer Base Management NTChanaaNo ratings yet
- CDSS Day-3Document207 pagesCDSS Day-3junitasariNo ratings yet
- POSTER - Laboratory Software That Connects To Your Labs EcosystemDocument1 pagePOSTER - Laboratory Software That Connects To Your Labs Ecosystemmicrobehunter007No ratings yet
- Invest IndiaDocument1 pageInvest IndiaKhushi BerryNo ratings yet
- 2018 KOREA PAVILION in TEXWORLD USADocument30 pages2018 KOREA PAVILION in TEXWORLD USAHelen Oh100% (1)
- Ashk Lawal - LinkedInDocument4 pagesAshk Lawal - LinkedInsrivatsaNo ratings yet
- Visit More Resumes at WWW Pages/resumes/resum Es - HTMLDocument7 pagesVisit More Resumes at WWW Pages/resumes/resum Es - HTMLAbde VilliersNo ratings yet
- Kmbit 04 Dbms Unit 5Document7 pagesKmbit 04 Dbms Unit 5Shruti NigamNo ratings yet
- ABC Rapid Prototyping Implementation Method Model No 0Document4 pagesABC Rapid Prototyping Implementation Method Model No 0Sağlık YönetimiNo ratings yet
- Vishnu CompressedDocument1 pageVishnu CompressedVichu DummyNo ratings yet
- Advanced Fixed Asset ReportingDocument28 pagesAdvanced Fixed Asset ReportingreymranNo ratings yet
- IS ModelDocument17 pagesIS Modelsoumys19No ratings yet
- Total Content Map SQLDocument1 pageTotal Content Map SQLGaurav SalunkheNo ratings yet
- The Difference Between Structured, Unstructured and Semi-Structured DataDocument2 pagesThe Difference Between Structured, Unstructured and Semi-Structured DataDivy PatelNo ratings yet
- CC Unit 4Document16 pagesCC Unit 4anishNo ratings yet
- DWM Unit 1Document20 pagesDWM Unit 1Mohan ganesh MothukuriNo ratings yet
- Taming Big DataDocument268 pagesTaming Big DatascottavedaNo ratings yet
- Chapter11 - Database ManagementDocument39 pagesChapter11 - Database ManagementXaronAngelNo ratings yet
- Principles of Data Management and Mining: CS 504 Spring 2020Document28 pagesPrinciples of Data Management and Mining: CS 504 Spring 2020bijaysubediNo ratings yet
- Taobao Case Study PDFDocument33 pagesTaobao Case Study PDFklarascomNo ratings yet
- Taobao Case Study PDFDocument33 pagesTaobao Case Study PDFAnonymous zpitrB80oNo ratings yet
- Hostel Management SystemDocument18 pagesHostel Management SystemNamrita Sundarraj50% (6)
- 2024 Meeting 1 - Data Warehouse FundamentalsDocument47 pages2024 Meeting 1 - Data Warehouse Fundamentalsu19236931No ratings yet
- Virtuoso Characterization Suite PDFDocument8 pagesVirtuoso Characterization Suite PDFtestNo ratings yet
- Welcome To IST 380 !: Data Science ProgrammingDocument73 pagesWelcome To IST 380 !: Data Science Programmingshabir AhmadNo ratings yet
- SImA 1.3 Customer Facing (HCS) DraftDocument17 pagesSImA 1.3 Customer Facing (HCS) DraftcloudsforestNo ratings yet
- Data Structures & Algorithms: Learn To Code Interactively Using Only Your Browser. Practice Labs and ProjectsDocument1 pageData Structures & Algorithms: Learn To Code Interactively Using Only Your Browser. Practice Labs and ProjectsAshish CharlesNo ratings yet
- TH Et Ea M: Ta Ba SeDocument24 pagesTH Et Ea M: Ta Ba SeSuchitraNo ratings yet
- Data WarehousingDocument48 pagesData WarehousingPravah ShuklaNo ratings yet
- LoC (Letter of Credit) EnhancementsDocument21 pagesLoC (Letter of Credit) EnhancementssomusatishNo ratings yet
- EIP Flashcards PDFDocument6 pagesEIP Flashcards PDFjimbeam2No ratings yet
- DBMS (Unit - 1)Document17 pagesDBMS (Unit - 1)divyanshi kansalNo ratings yet
- Lab3 Data EngineeringDocument12 pagesLab3 Data EngineeringTiagoNo ratings yet
- Dsbda Unit 1Document25 pagesDsbda Unit 1403 Chaudhari Sanika SagarNo ratings yet
- Data Structure PDFDocument1 pageData Structure PDFTHULASINo ratings yet
- BigStreamer For BankingDocument2 pagesBigStreamer For BankingPaulNo ratings yet
- MDG For Finance DeckDocument9 pagesMDG For Finance Deckrahul_agrawal165No ratings yet
- Status WFH / Wfo Process About Process Job Title Office LoctnDocument27 pagesStatus WFH / Wfo Process About Process Job Title Office LoctnNaik PremoNo ratings yet
- DBMS NotesDocument11 pagesDBMS NotesNikhilNo ratings yet
- Gadchiroli 5Document290 pagesGadchiroli 5Nilesh PathakNo ratings yet
- Toad Data Point Datasheet 68635 PDFDocument2 pagesToad Data Point Datasheet 68635 PDFAshrafulNo ratings yet
- Copy of DFD Diagram - Blank ERD & Data Flow PDFDocument1 pageCopy of DFD Diagram - Blank ERD & Data Flow PDFAnish YadavNo ratings yet
- Challenges and Applications of Large Language Models: Desi GN BehaviorDocument72 pagesChallenges and Applications of Large Language Models: Desi GN BehaviorAlex DiermeierNo ratings yet
- Lec 1 Part 2 XmindDocument1 pageLec 1 Part 2 XmindAhmad AbuelgasimNo ratings yet
- Information Related Specialistsv 8Document1 pageInformation Related Specialistsv 8Bob WigginsNo ratings yet
- Design Flow Diagram: MTN-ZAMBIA Half HourlyDocument3 pagesDesign Flow Diagram: MTN-ZAMBIA Half HourlyDhruvNo ratings yet
- Backup and Recovery Basics PresentationDocument15 pagesBackup and Recovery Basics PresentationyejrNo ratings yet
- Techlog Interactive Suite 2008.modulesDocument15 pagesTechlog Interactive Suite 2008.modulesari_si100% (5)
- BigStreamer CNEDocument2 pagesBigStreamer CNEPaulNo ratings yet
- 1 - Oracle Solution Intro BlackbeltDocument61 pages1 - Oracle Solution Intro BlackbeltWallace BandecoNo ratings yet
- Artificial Intelligence in Digital Marketing - Mind MapDocument1 pageArtificial Intelligence in Digital Marketing - Mind MapMilton Julián PulidoNo ratings yet
- Elec EstimatingDocument1 pageElec Estimatingrajesh0001No ratings yet
- Underpinning Methods, Procedure and ApplicationsDocument10 pagesUnderpinning Methods, Procedure and ApplicationsShivaun Seecharan0% (1)
- Data ScienceDocument20 pagesData Sciencemoshiul129No ratings yet
- Sap MM Interview 1673727260Document11 pagesSap MM Interview 1673727260kiadeNo ratings yet
- Person Just SW Alised Infor M IpeDocument1 pagePerson Just SW Alised Infor M Ipeapi-23629577No ratings yet
- Embedded - CO1Document124 pagesEmbedded - CO123mz02No ratings yet
- Data Centre ArchitectureDocument16 pagesData Centre Architecture23mz02No ratings yet
- 3.testing PrinciplesDocument20 pages3.testing Principles23mz02No ratings yet
- FUTURE - OF - MACHINE - LEARNING - IN - HEALTHCARE MeeDocument1 pageFUTURE - OF - MACHINE - LEARNING - IN - HEALTHCARE Mee23mz02No ratings yet
- Embedded System DesignDocument4 pagesEmbedded System Design23mz02No ratings yet
- 4th AIDocument12 pages4th AIPriyaNo ratings yet
- Almanca Dil Bilgisi Kılavuzu BaşlangıçtanDocument504 pagesAlmanca Dil Bilgisi Kılavuzu Başlangıçtanertan2002100% (2)
- Java ProgrammingDocument177 pagesJava ProgrammingVijayakumar SindhuNo ratings yet
- This Study Resource Was: Database Programming With PL/SQL 8-1: Practice ActivitiesDocument4 pagesThis Study Resource Was: Database Programming With PL/SQL 8-1: Practice ActivitiesGilang SaputraNo ratings yet
- Excel Data TableDocument4 pagesExcel Data TableClark DomingoNo ratings yet
- DBA Project L4Document3 pagesDBA Project L4SelamNo ratings yet
- Microsoft Software Assurance BenefitsDocument6 pagesMicrosoft Software Assurance BenefitsbrookptNo ratings yet
- Literature Review On Online Bus TicketingDocument4 pagesLiterature Review On Online Bus Ticketingfeiaozukg100% (1)
- Archmodels v003 PDFDocument5 pagesArchmodels v003 PDFMiguel PicoNo ratings yet
- User Experience Design Internship: Sahil KundalDocument15 pagesUser Experience Design Internship: Sahil KundalSahil KundalNo ratings yet
- 6GK72425DX300XE0 Datasheet enDocument2 pages6GK72425DX300XE0 Datasheet enxabsNo ratings yet
- SAF-T (RO) : Creation of Packages: SymptomDocument6 pagesSAF-T (RO) : Creation of Packages: SymptomLiviuNo ratings yet
- Class Vii Computer Annual Set II 2023 24Document3 pagesClass Vii Computer Annual Set II 2023 2471989No ratings yet
- Object Oriented MetricsDocument8 pagesObject Oriented Metricskamna1604No ratings yet
- Manuel - Zortrax M300Document50 pagesManuel - Zortrax M300Cédric SahiNo ratings yet
- Implementation of DDL CommandsDocument6 pagesImplementation of DDL Commandslaalan jiNo ratings yet
- 1337x.orgDocument10 pages1337x.orgsheetal2689100% (1)
- ET Quarter 3 Weeks 1 3Document11 pagesET Quarter 3 Weeks 1 3Steven Vic AlforqueNo ratings yet
- RUBRICS - Video EditingDocument1 pageRUBRICS - Video EditingMcheaven NojramNo ratings yet
- III Inserting Tiles: Important DataDocument4 pagesIII Inserting Tiles: Important DataJoshua IbrahimNo ratings yet
- Script To Gather OCFS2 Diagnostic InformationDocument3 pagesScript To Gather OCFS2 Diagnostic Informationelcaso34No ratings yet
- Class X 6-4-20Document3 pagesClass X 6-4-20AtanuBhandaryNo ratings yet
- Gujarat Technological UniversityDocument1 pageGujarat Technological UniversitybhavishwarikoooNo ratings yet
- Acx6160-Roadm Yang ModelDocument114 pagesAcx6160-Roadm Yang Modelhas samNo ratings yet
- POC Audit System - WalkthroughDocument45 pagesPOC Audit System - Walkthroughkeith tanuecoNo ratings yet
- 994-T012 REV A WS2000 E2A wTABSDocument141 pages994-T012 REV A WS2000 E2A wTABSblanoswa11No ratings yet
- Real Time Eeg Signal Processing Based On Ti S tms320c6713 DSKDocument9 pagesReal Time Eeg Signal Processing Based On Ti S tms320c6713 DSKkaoutarNo ratings yet
- Object Oriented Programming MCQsDocument33 pagesObject Oriented Programming MCQscute_12271% (7)
- Random NumbersDocument341 pagesRandom NumberskatovNo ratings yet
- AndroidRIL-SourceCode AppNote (UBX-13002041)Document46 pagesAndroidRIL-SourceCode AppNote (UBX-13002041)far.rhm2021No ratings yet