Download as pptx, pdf, or txt
You might also like
- Summer Training DSA Self-Paced ReportDocument22 pagesSummer Training DSA Self-Paced ReportAfzal Talukdar67% (12)
- w5 ClassificationDocument34 pagesw5 ClassificationSwastik SindhaniNo ratings yet
- Simulation Theory ReviewDocument75 pagesSimulation Theory Reviewtuongphan063No ratings yet
- 2.parameter EstimationDocument59 pages2.parameter EstimationLEE LEE LAUNo ratings yet
- w2 - Fundamentals of LearningDocument37 pagesw2 - Fundamentals of LearningSwastik SindhaniNo ratings yet
- Lecture 13Document43 pagesLecture 13GobiNo ratings yet
- K Nearest Neighbors: Probably A Duck."Document14 pagesK Nearest Neighbors: Probably A Duck."Daneil RadcliffeNo ratings yet
- 15 dm2 Imbalanced Learning 2022 23Document35 pages15 dm2 Imbalanced Learning 2022 23nimraNo ratings yet
- GEC 410 DR Agarana M.C.: Hypothesis TestingDocument75 pagesGEC 410 DR Agarana M.C.: Hypothesis TestingJohn DavidNo ratings yet
- 6 ProbabilitiesDocument52 pages6 Probabilitiesdamasodra33No ratings yet
- Nearest NeighbourDocument25 pagesNearest Neighbourbobe1500No ratings yet
- Instructor's Presentation - Introduction To Statistical InferenceDocument20 pagesInstructor's Presentation - Introduction To Statistical InferenceMar LagmayNo ratings yet
- DR Khan RM@UGC HRDC 21.11.20Document37 pagesDR Khan RM@UGC HRDC 21.11.20shahmkhan2No ratings yet
- 03 Random - Variables - SLIDEDocument20 pages03 Random - Variables - SLIDEari rahadyanNo ratings yet
- Quantitative AnalysisDocument84 pagesQuantitative AnalysisManoj Kumar0% (1)
- Stats BasicsDocument58 pagesStats BasicsRavi goelNo ratings yet
- The Median TestDocument12 pagesThe Median TestLukman Nul HakimNo ratings yet
- Statistics Part1 2013Document17 pagesStatistics Part1 2013Victor De Paula VilaNo ratings yet
- Factor AnalysisDocument31 pagesFactor AnalysisRachmat HidayatNo ratings yet
- Dr. S. Vairachilai Department of CSE CVR College of Engineering Mangalpalli TelanganaDocument18 pagesDr. S. Vairachilai Department of CSE CVR College of Engineering Mangalpalli TelanganaSavitha ElluruNo ratings yet
- BES - Lecture 8 - Nonparametric Test 2Document10 pagesBES - Lecture 8 - Nonparametric Test 2Diễm Quỳnh TrịnhNo ratings yet
- K-Nearest Neighbour (KNN)Document14 pagesK-Nearest Neighbour (KNN)Muhammad HaroonNo ratings yet
- Combining Classifiers: OutlineDocument15 pagesCombining Classifiers: Outlinejawad_shahNo ratings yet
- Week 04 Lecture MaterialDocument52 pagesWeek 04 Lecture MaterialMeer HassanNo ratings yet
- DADM S15 K-NN ClassificationDocument13 pagesDADM S15 K-NN ClassificationAnisha SapraNo ratings yet
- Lecture 22 - K-Nearnest NeighboursDocument11 pagesLecture 22 - K-Nearnest Neighboursbscs-20f-0009No ratings yet
- Chapter-Summary of BacalDocument11 pagesChapter-Summary of BacalTammy OgoyNo ratings yet
- Gea CheatsheetDocument4 pagesGea Cheatsheeta spelluNo ratings yet
- BES - Lecture 7Document14 pagesBES - Lecture 7TACN-1M-19ACN Nguyen Hai VuNo ratings yet
- StatisticsDocument37 pagesStatisticsDishank UpadhyayNo ratings yet
- LECTURE 02-Probability IE 3373 - ALDocument44 pagesLECTURE 02-Probability IE 3373 - ALMahmoud AbdelazizNo ratings yet
- Chap1randomvariables ShortDocument40 pagesChap1randomvariables ShortLove your LifeNo ratings yet
- Lecture 7 Random Variable Confidence IntervalDocument52 pagesLecture 7 Random Variable Confidence Intervalmariloh6102No ratings yet
- PO2508 Topic 3Document39 pagesPO2508 Topic 3Blake AskewNo ratings yet
- Lazy Learners Unit 2Document26 pagesLazy Learners Unit 2ManshiNo ratings yet
- Hypothesis TestingDocument20 pagesHypothesis TestingJanet GNo ratings yet
- OCR S1 Revision SheetsDocument12 pagesOCR S1 Revision SheetsGaneshNo ratings yet
- Architectures of Artificial Neural Networks: Deepak D, Asst. Prof., Dept. of CSE, Canara Engg. College 1Document61 pagesArchitectures of Artificial Neural Networks: Deepak D, Asst. Prof., Dept. of CSE, Canara Engg. College 1Smriti SharmaNo ratings yet
- CSE291D 10aDocument55 pagesCSE291D 10aballechaseNo ratings yet
- Aiml M3 C2Document56 pagesAiml M3 C2Vivek TgNo ratings yet
- Stats101A - Chapter 1Document25 pagesStats101A - Chapter 1Zhen WangNo ratings yet
- Introduction To Sampling Distributions Unit 2D: SECTION K: Chapter 64 of John Bird TextbookDocument31 pagesIntroduction To Sampling Distributions Unit 2D: SECTION K: Chapter 64 of John Bird TextbookMatone MafologelaNo ratings yet
- Cambridge International As A Level Mathematics Probability Statistics 2 Practice Book Cambridge International Z LibDocument85 pagesCambridge International As A Level Mathematics Probability Statistics 2 Practice Book Cambridge International Z LibSukanya DattaNo ratings yet
- DSS07 CLS Rule Induction, K NN, Naive Bayesian en Đã G PDocument507 pagesDSS07 CLS Rule Induction, K NN, Naive Bayesian en Đã G PHoàng Ngọc AnhNo ratings yet
- Module0 IntroductionDocument27 pagesModule0 Introductionrohan kalidindiNo ratings yet
- Machine Learning Unit-3.1Document20 pagesMachine Learning Unit-3.1sahil.utube2003No ratings yet
- Model EvaluationDocument80 pagesModel EvaluationDeva Hema DNo ratings yet
- Supervised Learning 1 PDFDocument162 pagesSupervised Learning 1 PDFAlexanderNo ratings yet
- Correlational ResearchDocument34 pagesCorrelational ResearchTừ Quỳnh NhưNo ratings yet
- Accelerated Data Science Introduction To Machine Learning AlgorithmsDocument37 pagesAccelerated Data Science Introduction To Machine Learning AlgorithmssanketjaiswalNo ratings yet
- Parametric & Nonparametric Models For Within-Groups ComparisonsDocument8 pagesParametric & Nonparametric Models For Within-Groups ComparisonsHamdy AhmadNo ratings yet
- Foundations of Machine Learning: Module 3: Instance Based Learning and Feature ReductionDocument40 pagesFoundations of Machine Learning: Module 3: Instance Based Learning and Feature ReductionNishant TiwariNo ratings yet
- Economic Dispatch LectureDocument45 pagesEconomic Dispatch LectureGaurav GargNo ratings yet
- CS 464 Introduction To Machine Learning: Feature SelectionDocument36 pagesCS 464 Introduction To Machine Learning: Feature SelectionMathias BuenoNo ratings yet
- Ch. 9 Lecture Slides Fall 2018Document77 pagesCh. 9 Lecture Slides Fall 2018Gajan NagarajNo ratings yet
- Ch08 - Large-Sample EstimationDocument28 pagesCh08 - Large-Sample EstimationislamNo ratings yet
- ORF 544 Week 2 Adaptive LearningDocument145 pagesORF 544 Week 2 Adaptive LearningBruno BritoNo ratings yet
- 11paired TDocument49 pages11paired Tbszool006No ratings yet
- Chapter 8Document42 pagesChapter 8beshahashenafe20No ratings yet
- 2022 CSN373 Lec 6Document35 pages2022 CSN373 Lec 6Very UselessNo ratings yet
- APU CSLLT 10 - Bit Manipulation CommandsDocument22 pagesAPU CSLLT 10 - Bit Manipulation CommandsAli AtifNo ratings yet
- Traveling Salesman ProblemDocument24 pagesTraveling Salesman ProblemK.R.Raguram0% (1)
- 2018-19 A CC4002NI N2 CW Report NP01NT4A180135 Saphal ShresthaDocument17 pages2018-19 A CC4002NI N2 CW Report NP01NT4A180135 Saphal ShresthaNaseeb GartaulaNo ratings yet
- Full Download Building Java Programs 3rd Edition Reges Test BankDocument35 pagesFull Download Building Java Programs 3rd Edition Reges Test Bankjaydencot1100% (39)
- Answer 56855Document1 pageAnswer 56855Roshan SainiNo ratings yet
- Bca 1 Sem C Programming Winter 2016Document2 pagesBca 1 Sem C Programming Winter 2016Saurabh RautNo ratings yet
- Lecture 10: Introduction To Algebraic Graph Theory: Example 1.1 (The Spectrum of The Complete Graph)Document11 pagesLecture 10: Introduction To Algebraic Graph Theory: Example 1.1 (The Spectrum of The Complete Graph)kientrungle2001No ratings yet
- Part 1: Use Notebook: (1 Mark)Document9 pagesPart 1: Use Notebook: (1 Mark)Nguyen Tien Dat (K16 DN)No ratings yet
- Block Dig Vs Signal Flow Graph PDFDocument6 pagesBlock Dig Vs Signal Flow Graph PDFAwais Anwar100% (1)
- FeedforwardDocument34 pagesFeedforwardkiranNo ratings yet
- Computer Science: at HarvardDocument12 pagesComputer Science: at HarvardYsabela LaureanoNo ratings yet
- Super Egg Drop - LeetCode ArticlesDocument11 pagesSuper Egg Drop - LeetCode ArticlesFrankie LiuNo ratings yet
- Rand and Srand in C - C++ - GeeksforGeeks PDFDocument5 pagesRand and Srand in C - C++ - GeeksforGeeks PDFMilind ChakrabortyNo ratings yet
- 6.2 Sum-Of-Subsets, Hamiltonian CyclesDocument8 pages6.2 Sum-Of-Subsets, Hamiltonian CyclesKomal YadavNo ratings yet
- Major 2020Document2 pagesMajor 2020Ajay KumarNo ratings yet
- Unit 2-FlatDocument23 pagesUnit 2-FlatPhani KumarNo ratings yet
- Week 13 APSVaibhav SharmaDocument3 pagesWeek 13 APSVaibhav SharmaVaibhav SharmaNo ratings yet
- Integer Representations and Algorithms: 1. Finally, We Will Describe An e Cient Algorithm For Modular ExponentiationDocument5 pagesInteger Representations and Algorithms: 1. Finally, We Will Describe An e Cient Algorithm For Modular Exponentiationg driveNo ratings yet
- KLDocument30 pagesKLrockeysuseelanNo ratings yet
- Learning: Perceptrons & Neural Networks: Artificial Intelligence CMSC 25000 February 8, 2007Document31 pagesLearning: Perceptrons & Neural Networks: Artificial Intelligence CMSC 25000 February 8, 2007paku deyNo ratings yet
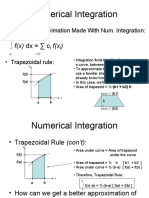
- Numerical Integration: F (X) DX C F (XDocument6 pagesNumerical Integration: F (X) DX C F (Xkate1129No ratings yet
- Formal Languages and Automata TheoryDocument24 pagesFormal Languages and Automata TheoryAyele MitkuNo ratings yet
- Program 7-EM Algorithm-K Means AlgorithmDocument3 pagesProgram 7-EM Algorithm-K Means AlgorithmVijay Sathvika BNo ratings yet
- Amrita School of Engineering, Bengaluru Campus: End Semester Exam-August 2021Document1 pageAmrita School of Engineering, Bengaluru Campus: End Semester Exam-August 2021TejaNo ratings yet
- Digital Photography and Video EditingDocument8 pagesDigital Photography and Video EditingEdwin MugoNo ratings yet
- Functions - Mark Anthony BulaonDocument6 pagesFunctions - Mark Anthony Bulaonfriendlyfriend7No ratings yet
- Quiz 1Document16 pagesQuiz 1Khatia IvanovaNo ratings yet
- Chapter 4 - CGRDocument50 pagesChapter 4 - CGRsam sayedNo ratings yet
- AaDocument10 pagesAaPeter HanssonNo ratings yet