Download as pptx, pdf, or txt
You might also like
- Convolutional Neural Networks (CNN) - QA & HandsOnDocument5 pagesConvolutional Neural Networks (CNN) - QA & HandsOnजोशी अंकित60% (5)
- Unit3 2023 NNDLDocument69 pagesUnit3 2023 NNDLSONY P J 2248440No ratings yet
- Machine Learning Unit 3Document40 pagesMachine Learning Unit 3read4freeNo ratings yet
- Typical CNN (Convolutional Neural Network) Architecture: CHARAN S (1VE20CA005) Cse-Ai, SvceDocument13 pagesTypical CNN (Convolutional Neural Network) Architecture: CHARAN S (1VE20CA005) Cse-Ai, Svcecharan.s2702No ratings yet
- Convolutional Neural Network (CNN)Document38 pagesConvolutional Neural Network (CNN)Mohammad Hashim JaffriNo ratings yet
- Convolutional Neural Networks & ZapierDocument75 pagesConvolutional Neural Networks & ZapierTimer InsightNo ratings yet
- DL Unit 3 2019PATDocument66 pagesDL Unit 3 2019PATNilesh NagraleNo ratings yet
- Classify Webcam Images Using Deep LearningDocument17 pagesClassify Webcam Images Using Deep LearninggauravNo ratings yet
- Identify Web Cam Images Using Neural NetworksDocument17 pagesIdentify Web Cam Images Using Neural NetworksgauravNo ratings yet
- DCGAN (Deep Convolution Generative Adversarial Networks)Document27 pagesDCGAN (Deep Convolution Generative Adversarial Networks)lakpa tamangNo ratings yet
- UNIT 3 Self NotesDocument5 pagesUNIT 3 Self NotesjainayushtechNo ratings yet
- Deep LearningUNIT-IVDocument16 pagesDeep LearningUNIT-IVnikhilsinha0099No ratings yet
- Artificial IntelligenceDocument11 pagesArtificial Intelligence2BL20CS022Anjana HiroliNo ratings yet
- CC511 Week 7 - Deep - LearningDocument33 pagesCC511 Week 7 - Deep - Learningmohamed sherifNo ratings yet
- Convolutional Neural NetworkDocument78 pagesConvolutional Neural NetworkAaqib InamNo ratings yet
- Person Re-Identification Via Structural Deep Metric LearningDocument31 pagesPerson Re-Identification Via Structural Deep Metric LearningsankarideviNo ratings yet
- Selected Algorithm: Mse N y yDocument2 pagesSelected Algorithm: Mse N y yRokn ZamanNo ratings yet
- Unit 3 - Machine Learning - WWW - Rgpvnotes.inDocument29 pagesUnit 3 - Machine Learning - WWW - Rgpvnotes.inASHOKA KUMARNo ratings yet
- DL Unit3Document8 pagesDL Unit3Anonymous xMYE0TiNBcNo ratings yet
- 20 Questions To Test Your Skills On CNN Convolutional Neural NetworksDocument11 pages20 Questions To Test Your Skills On CNN Convolutional Neural NetworksKumkumo Kussia KossaNo ratings yet
- Deep Learning For Computer VisionDocument55 pagesDeep Learning For Computer VisionakramNo ratings yet
- CS 611 Slides 5Document28 pagesCS 611 Slides 5Ahmad AbubakarNo ratings yet
- Assignment #1: Afzal Ali (11282) Muhammad Hammad (11293) Muhammad Bilal (11291) Mehran Ahmed (11287) Date 20/03/2019Document7 pagesAssignment #1: Afzal Ali (11282) Muhammad Hammad (11293) Muhammad Bilal (11291) Mehran Ahmed (11287) Date 20/03/2019Muhammad BilalNo ratings yet
- Cnnbasics 171028092801Document43 pagesCnnbasics 171028092801jayasanthiNo ratings yet
- CNN Part 1Document38 pagesCNN Part 1pragathisai0912No ratings yet
- Convolutional Neural Network: by Gagandeep KaurDocument107 pagesConvolutional Neural Network: by Gagandeep Kaurjamiesonlara100% (1)
- Object Detection and IdentificationDocument20 pagesObject Detection and Identificationrohith mukkamala67% (3)
- CNN Course-Notes 365Document29 pagesCNN Course-Notes 365aherfNo ratings yet
- Image Processing Through Machine Learning: By:-Akansh Kumar (En-1)Document22 pagesImage Processing Through Machine Learning: By:-Akansh Kumar (En-1)Chitranshu SrivastavNo ratings yet
- Deep LearningDocument17 pagesDeep LearningkhillarevarunNo ratings yet
- Convolutional Neural NetworkDocument61 pagesConvolutional Neural NetworkAnkit MahapatraNo ratings yet
- UNIT 2 Self NotesDocument10 pagesUNIT 2 Self NotesjainayushtechNo ratings yet
- What Is Convolutional Neural NetworkDocument16 pagesWhat Is Convolutional Neural Networkahmedliet143No ratings yet
- Deep Learning PDFDocument55 pagesDeep Learning PDFNitesh Kumar SharmaNo ratings yet
- Appiled AIDocument9 pagesAppiled AIchude okeruluNo ratings yet
- Basic Introduction To Convolutional Neural Network in Deep LearningDocument9 pagesBasic Introduction To Convolutional Neural Network in Deep LearningNarsini AKSHARANo ratings yet
- Convolution Neural NetworkDocument66 pagesConvolution Neural NetworkmohithNo ratings yet
- Computer Vision NN ArchitectureDocument19 pagesComputer Vision NN ArchitecturePrasu MuthyalapatiNo ratings yet
- Convolutional Neural Networks (CNN)Document7 pagesConvolutional Neural Networks (CNN)Towsif SalauddinNo ratings yet
- PPTDocument20 pagesPPTHarshNo ratings yet
- Principles of Convolutional Neural NetworksDocument9 pagesPrinciples of Convolutional Neural NetworksAsma AliNo ratings yet
- CSED Final ExamDocument13 pagesCSED Final ExamVishal SinghNo ratings yet
- Bee4333 Intelligent Control: Artificial Neural Network (ANN)Document120 pagesBee4333 Intelligent Control: Artificial Neural Network (ANN)Arron YewNo ratings yet
- IBM Question & AnswersDocument3 pagesIBM Question & AnswersMr SKammerNo ratings yet
- Unit 3 - Machine LearningDocument16 pagesUnit 3 - Machine LearningGauri BansalNo ratings yet
- Generatives Neural NetworksDocument31 pagesGeneratives Neural NetworksDevyansh GuptaNo ratings yet
- Slides CNNDocument17 pagesSlides CNNandres alfonso varelo silgadoNo ratings yet
- Brain Cancer DetectionDocument26 pagesBrain Cancer Detectionstarktechtony.1111No ratings yet
- Deep Learning Unit-IIIDocument9 pagesDeep Learning Unit-IIIAnonymous xMYE0TiNBcNo ratings yet
- Deep Learning NotesDocument14 pagesDeep Learning NotesbadalrkcocNo ratings yet
- Convolutional Neural NetworkDocument3 pagesConvolutional Neural NetworkShankul ShuklaNo ratings yet
- Sommaire CNN PresentationDocument10 pagesSommaire CNN Presentationmario DjawouNo ratings yet
- CV MotDocument69 pagesCV Mothuo siNo ratings yet
- KJ Mohamed Dhanish MIP 2Document36 pagesKJ Mohamed Dhanish MIP 2180051601033 ecea2018No ratings yet
- Module1 ECO-598 AI & ML Aug 21Document45 pagesModule1 ECO-598 AI & ML Aug 21Soujanya NerlekarNo ratings yet
- CNN (Convolution Neural Networks)Document28 pagesCNN (Convolution Neural Networks)Ahsan IsmailNo ratings yet
- CNN 1Document23 pagesCNN 1pcjoshi02No ratings yet
- Neural Networks Unit 3Document93 pagesNeural Networks Unit 3svkarthik83No ratings yet
- CNN and AutoencoderDocument56 pagesCNN and AutoencoderShubham BhaleraoNo ratings yet
- New Microsoft Word DocumentDocument6 pagesNew Microsoft Word DocumentLikith SRNo ratings yet
- Module 2 NotesDocument71 pagesModule 2 NotesLikith SRNo ratings yet
- Module 4 NotesDocument41 pagesModule 4 NotesLikith SRNo ratings yet
- Module 5 NotesDocument22 pagesModule 5 NotesLikith SRNo ratings yet
- Module 1 NotesDocument60 pagesModule 1 NotesLikith SRNo ratings yet
- On The Origin of Deep Learning: Haohan Wang Bhiksha RajDocument72 pagesOn The Origin of Deep Learning: Haohan Wang Bhiksha RajDingNo ratings yet
- Programme DetailsDocument2 pagesProgramme DetailsShubhangi GuptaNo ratings yet
- Artificial Neural NetworksDocument43 pagesArtificial Neural NetworksanqrwpoborewNo ratings yet
- Adaline and Delta Learning RuleDocument18 pagesAdaline and Delta Learning Ruleأمير نصيف محسنNo ratings yet
- Introduction To Neural Networks: Training Learn GeneralizationDocument46 pagesIntroduction To Neural Networks: Training Learn GeneralizationjaneThomasNo ratings yet
- CERN Deep Learning and VisionDocument72 pagesCERN Deep Learning and VisionNarendra SinghNo ratings yet
- Recurrent Neural NetworksDocument20 pagesRecurrent Neural NetworksSharvari GundawarNo ratings yet
- 9-Mc - Cullah Pits Neural Network and Hebb Algorithm-17-Jul-2019Material - I - 17-Jul-2019 - Unit - I - Mc-Culloh - PitsDocument13 pages9-Mc - Cullah Pits Neural Network and Hebb Algorithm-17-Jul-2019Material - I - 17-Jul-2019 - Unit - I - Mc-Culloh - Pitssahale sheraNo ratings yet
- Unit 4 NotesDocument45 pagesUnit 4 Notesvamsi kiran100% (1)
- Neural Network Project Report.Document12 pagesNeural Network Project Report.Ashutosh LembheNo ratings yet
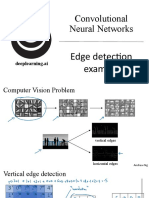
- Convolutional Neural Networks: Edge Detection ExampleDocument4 pagesConvolutional Neural Networks: Edge Detection Exampleh_shatNo ratings yet
- Research ArticleDocument10 pagesResearch Articlerikaseo rikaNo ratings yet
- Deep Learning Lab ManualDocument19 pagesDeep Learning Lab Manualdoreamon2619100% (1)
- DeepLearning Practice Question AnswersDocument43 pagesDeepLearning Practice Question AnswersPaul GeorgeNo ratings yet
- Soft Computing and OptimizationDocument1 pageSoft Computing and Optimizationsindhu-aravinda9No ratings yet
- 2.neural NetworkDocument19 pages2.neural Networkrajthakre81No ratings yet
- Lecture Notes To Neural Networks in Electrical EngineeringDocument11 pagesLecture Notes To Neural Networks in Electrical EngineeringNaeem Ali SajadNo ratings yet
- Algorithms 15 00129 v2Document25 pagesAlgorithms 15 00129 v2Austin Abhishek KispottaNo ratings yet
- Understanding Deep Learning Chitta RanjanDocument13 pagesUnderstanding Deep Learning Chitta RanjanJeferson BonfanteNo ratings yet
- Klasifikasi Image Processing Pada Citra Warna Daun Padi Menggunakan Metode Convolutional Neural NetworkDocument12 pagesKlasifikasi Image Processing Pada Citra Warna Daun Padi Menggunakan Metode Convolutional Neural Networkbismillahta123No ratings yet
- Deep Learning in Science Theory, Algorithms, and ApplicationsDocument8 pagesDeep Learning in Science Theory, Algorithms, and ApplicationsUsman AliNo ratings yet
- ReferenceDocument5 pagesReferenceNguyễnXuânAnhQuânNo ratings yet
- Project Report - Front Page - SampleDocument11 pagesProject Report - Front Page - SampleShivank YadavNo ratings yet
- Actual4Test: Actual4test - Actual Test Exam Dumps-Pass For IT ExamsDocument4 pagesActual4Test: Actual4test - Actual Test Exam Dumps-Pass For IT ExamsBryan OrdoñezNo ratings yet
- Lecture 12 - Supervised Learning - Hopfield Networks - (Part 5)Document3 pagesLecture 12 - Supervised Learning - Hopfield Networks - (Part 5)Ammar AlkindyNo ratings yet
- Image Segmentation Using Deep Learning A SurveyDocument20 pagesImage Segmentation Using Deep Learning A SurveySujan MNo ratings yet
- Fundamentals of Deep Learning: Part 2: How A Neural Network TrainsDocument54 pagesFundamentals of Deep Learning: Part 2: How A Neural Network TrainsPraveen SinghNo ratings yet
- An F Is Assignment 1 ReportDocument9 pagesAn F Is Assignment 1 ReportMahedi RajNo ratings yet
- Neural SyllabusDocument1 pageNeural SyllabuskamalshrishNo ratings yet