Download as pptx, pdf, or txt
You might also like
- This is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...From EverandThis is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...Rating: 4.5 out of 5 stars4.5/5 (6)
- Organizing Analyzing and Interpreting Test ResultsDocument43 pagesOrganizing Analyzing and Interpreting Test ResultsAhlan Marciano Emmanuel De SilvaNo ratings yet
- Lesson2 1450Document43 pagesLesson2 1450gm hashNo ratings yet
- Nordis FinalDocument6 pagesNordis FinalSamuel GoyoNo ratings yet
- Lecture 4Document38 pagesLecture 4addis zewdNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- Ambo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)Document121 pagesAmbo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)keransotadeseNo ratings yet
- Summary of Midterm Lessons (20231106134417)Document9 pagesSummary of Midterm Lessons (20231106134417)Antonette LaurioNo ratings yet
- Probability and SamplingDistributionsDocument59 pagesProbability and SamplingDistributionsRmro Chefo LuigiNo ratings yet
- Business Statistics: Module 2. Descriptive Statistics Page 1 of 6Document6 pagesBusiness Statistics: Module 2. Descriptive Statistics Page 1 of 6CARL JAMESNo ratings yet
- Training Material For 06th Sem Engineering Students of MCE - Seventh SenseDocument280 pagesTraining Material For 06th Sem Engineering Students of MCE - Seventh Sensemanu manoharNo ratings yet
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttilieNo ratings yet
- Chapter 2 - Lesson 4 Random VariablesDocument19 pagesChapter 2 - Lesson 4 Random VariablesChi VirayNo ratings yet
- Stat I Chapter 3Document48 pagesStat I Chapter 3Natnael TesfayeNo ratings yet
- The Normal DistributionDocument9 pagesThe Normal DistributionDog VenturesNo ratings yet
- Statistics Presentation by AamnaDocument48 pagesStatistics Presentation by AamnaAnujNo ratings yet
- Chi Square 2 - 2Document13 pagesChi Square 2 - 2Fruelan SaritaNo ratings yet
- Chapter 13 OrganizerDocument15 pagesChapter 13 OrganizerBrettNo ratings yet
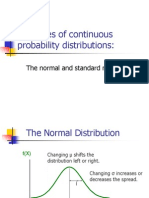
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- PSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionDocument44 pagesPSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionSatish NamjoshiNo ratings yet
- PC 2 Statistics by Praveen MathurDocument44 pagesPC 2 Statistics by Praveen MathurjyotiNo ratings yet
- T-Distribution and Estimation of Parameters Using T-DistributionDocument22 pagesT-Distribution and Estimation of Parameters Using T-DistributionClemence Marie FuentesNo ratings yet
- Standard Deviation Made EasyDocument8 pagesStandard Deviation Made EasyShe LagundinoNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNo ratings yet
- Part 6 - Week 07 Students TDocument13 pagesPart 6 - Week 07 Students TJane DoeNo ratings yet
- TRISEM14-2021-22 BMT5113 TH VL2021220200049 Reference Material I 04-Aug-2021 Measures of DispersionDocument59 pagesTRISEM14-2021-22 BMT5113 TH VL2021220200049 Reference Material I 04-Aug-2021 Measures of DispersionVickyNo ratings yet
- Central TendencyDocument17 pagesCentral TendencyShruti AgrawalNo ratings yet
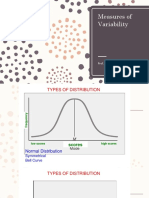
- Measures of Variability: Prof. Michelle M. Mag-IsaDocument46 pagesMeasures of Variability: Prof. Michelle M. Mag-IsaMichelle MalabananNo ratings yet
- Basics of StatisticsDocument16 pagesBasics of StatisticsSolaiman Sikder 2125149690No ratings yet
- Normal Distribution OverviewDocument3 pagesNormal Distribution OverviewDarshan MDNo ratings yet
- Mathematical Methods: Dr. Asim KhwajaDocument37 pagesMathematical Methods: Dr. Asim KhwajahammadNo ratings yet
- Measures of Dispersion MG EditDocument61 pagesMeasures of Dispersion MG EditAnnRubyAlcaideBlandoNo ratings yet
- Lecture 3Document36 pagesLecture 3addis zewdNo ratings yet
- Ken Black QA ch03Document61 pagesKen Black QA ch03Rushabh Vora0% (1)
- Standard ScoresDocument2 pagesStandard ScoresDr. Nisanth.P.MNo ratings yet
- Business Statistics: Assignment - Bb108Document9 pagesBusiness Statistics: Assignment - Bb108ShehbazShoukatNo ratings yet
- Elementary StatisticsDocument73 pagesElementary StatisticsDeepak GoyalNo ratings yet
- Business MathematicsDocument61 pagesBusiness MathematicsVishal BhadraNo ratings yet
- Normal Distribution StanfordDocument43 pagesNormal Distribution Stanfordapi-204699162100% (1)
- Normal Distribution: It Can Be Spread Out More On The Left or More On The RightDocument10 pagesNormal Distribution: It Can Be Spread Out More On The Left or More On The Righteinz82No ratings yet
- 5 Z&NormalDocument33 pages5 Z&NormalRosemarie GasparNo ratings yet
- Grade 8 Maths Semester 2 Endterm ContentDocument31 pagesGrade 8 Maths Semester 2 Endterm ContentFile LuuNo ratings yet
- Mean Median ModeDocument32 pagesMean Median ModeShiella Mae Baltazar BulauitanNo ratings yet
- Statical Data 1Document32 pagesStatical Data 1Irma Estela Marie EstebanNo ratings yet
- Introducing Statistical Terms: Sachin Chauhan Pillai's Institue of Management Studies and ResearchDocument39 pagesIntroducing Statistical Terms: Sachin Chauhan Pillai's Institue of Management Studies and ResearchKavita PrakashNo ratings yet
- Standard Scores and The Normal Curve: Report Presentation byDocument38 pagesStandard Scores and The Normal Curve: Report Presentation byEmmanuel AbadNo ratings yet
- Basic StatsDocument23 pagesBasic StatsAldine-Jhun AJ CruizNo ratings yet
- Revcards DataDocument8 pagesRevcards Dataapi-200177496No ratings yet
- Measures of Relative StandingDocument59 pagesMeasures of Relative StandingGracean MaslogNo ratings yet
- Significant Figures: Dr. Ma. Victoria Delis-NaboyaDocument45 pagesSignificant Figures: Dr. Ma. Victoria Delis-NaboyaRochen Shaira DargantesNo ratings yet
- Statistic Sample Question IiswbmDocument15 pagesStatistic Sample Question IiswbmMudasarSNo ratings yet
- 13 ZscoresDocument13 pages13 ZscoresMhelvyn RamiscalNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: Soumendra RoyDocument34 pagesMeasures of Central Tendency: Mean, Mode, Median: Soumendra Roybapparoy100% (1)
- Lecture 6 Measures of Central Tendency VariationDocument27 pagesLecture 6 Measures of Central Tendency Variationvincentchavenia1No ratings yet
- Describing Individual PerformanceDocument30 pagesDescribing Individual PerformanceRomz Quintos100% (4)
- F, T TestDocument21 pagesF, T TestKamini Satish SinghNo ratings yet
- Continuous Probability Distribution PDFDocument47 pagesContinuous Probability Distribution PDFDipika PandaNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Two Way AnovaDocument16 pagesTwo Way AnovaJane Beatriz ConsolacionNo ratings yet
- AUsing R For Power Analysis PDFDocument6 pagesAUsing R For Power Analysis PDFReFrancesNo ratings yet
- Measures of DispersionDocument6 pagesMeasures of DispersionAri GaryanNo ratings yet
- Meaning of Correlation: Correlation: If The Change in One Variable Affects A Change inDocument11 pagesMeaning of Correlation: Correlation: If The Change in One Variable Affects A Change inKunal DasNo ratings yet
- Analisis Perbandingan Kinerja Keuangan Perusahaan Farmasi Milik BUMN Dan SwastaDocument12 pagesAnalisis Perbandingan Kinerja Keuangan Perusahaan Farmasi Milik BUMN Dan SwastaNindi CaturNo ratings yet
- Pengaruh Kepemimpinan, Lingkungan Kerja Dan Disiplin Kerja Terhadap Kinerja Pegawai Kelurahan Di Wilayah Kecamatan Ampana Kota Kabupaten Tojo Una-UnaDocument9 pagesPengaruh Kepemimpinan, Lingkungan Kerja Dan Disiplin Kerja Terhadap Kinerja Pegawai Kelurahan Di Wilayah Kecamatan Ampana Kota Kabupaten Tojo Una-UnaNely Noer SofwatiNo ratings yet
- By David Roodman: How To Do Xtabond2: An Introduction To "Difference" and "System" GMM in StataDocument48 pagesBy David Roodman: How To Do Xtabond2: An Introduction To "Difference" and "System" GMM in StataRui Cardoso PedroNo ratings yet
- Week 1 - QM1Document64 pagesWeek 1 - QM1UjjawalNo ratings yet
- 8 CSC446 546 InputModelingDocument44 pages8 CSC446 546 InputModelingAshrafur RahmanNo ratings yet
- Ebook Statistics The Art and Science of Learning From Data PDF Full Chapter PDFDocument67 pagesEbook Statistics The Art and Science of Learning From Data PDF Full Chapter PDFshirley.greig403100% (35)
- Probability and Statistics - Problem Set 5Document2 pagesProbability and Statistics - Problem Set 5Manuel John SorianoNo ratings yet
- Business Statistics by Gupta 365 379Document15 pagesBusiness Statistics by Gupta 365 379KowsalyaNo ratings yet
- DSE-2 PDocument4 pagesDSE-2 PsamuleNo ratings yet
- Probability and Stochastic Processes: A Friendly IntroductionDocument5 pagesProbability and Stochastic Processes: A Friendly IntroductionqscvbqscvbNo ratings yet
- Advanced Regression PDFDocument160 pagesAdvanced Regression PDFfenriz666No ratings yet
- Forecasting: Statistics 2 ITESM Campus Guadalajara Prof: Ing. Maria Luisa OlascoagaDocument110 pagesForecasting: Statistics 2 ITESM Campus Guadalajara Prof: Ing. Maria Luisa Olascoagajacks ocNo ratings yet
- Permodelan Dan Evaluasi CadanganDocument19 pagesPermodelan Dan Evaluasi CadanganElgi Zacky ZachryNo ratings yet
- Stat 122Document22 pagesStat 122Dexter RubionNo ratings yet
- Linear Regression and Correlation: Y Y N X X N Y X XY N RDocument3 pagesLinear Regression and Correlation: Y Y N X X N Y X XY N RMahabubullahi Nur 1925313060No ratings yet
- Sample Problems of X-Bar, Sigma, and R Charts (ME-361) - Batch 15 (ME)Document1 pageSample Problems of X-Bar, Sigma, and R Charts (ME-361) - Batch 15 (ME)MUKABBIR AHAMED RAFAT 1703119No ratings yet
- Biostatistics: A Refresher: Kevin M. Sowinski, Pharm.D., FCCPDocument20 pagesBiostatistics: A Refresher: Kevin M. Sowinski, Pharm.D., FCCPNaji Mohamed Alfatih100% (1)
- Parametric and Nonparametric Test: By: Sai Prakash MBA Insurance Management Pondicherry UniversityDocument10 pagesParametric and Nonparametric Test: By: Sai Prakash MBA Insurance Management Pondicherry UniversitysureshexecutiveNo ratings yet
- Sampling Theory and MethodDocument22 pagesSampling Theory and MethodMaryjean MalinaoNo ratings yet
- Hypothesis TestingDocument18 pagesHypothesis Testingprabhjot singh100% (1)
- SamplingDocument41 pagesSamplingShailendra DhakadNo ratings yet
- Analysis of Variance (ANOVA) : W&W, Chapter 10Document20 pagesAnalysis of Variance (ANOVA) : W&W, Chapter 10sarangpandeNo ratings yet
- Statistics (Unit-1)Document101 pagesStatistics (Unit-1)mannu02.manishNo ratings yet
- Chapter 1-2 LectureDocument16 pagesChapter 1-2 LectureDark BugNo ratings yet
- Quartiles in R PDFDocument4 pagesQuartiles in R PDFwichastaNo ratings yet
- PrelimDocument3 pagesPrelimJohn AlbertNo ratings yet