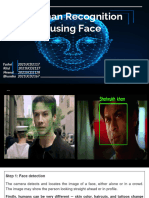
Download as pptx, pdf, or txt
You might also like
- Data Sheet: SpecificationsDocument3 pagesData Sheet: Specificationshashmisahib48No ratings yet
- Facial Recognitioin Literature Report of Swaran SinghDocument5 pagesFacial Recognitioin Literature Report of Swaran Singhgarg23201No ratings yet
- Emotion Based Music PlayerDocument3 pagesEmotion Based Music Playerpratiksha jadhavNo ratings yet
- Face Detection Using Open CV Machine Learning: Software Engineering ProjectDocument14 pagesFace Detection Using Open CV Machine Learning: Software Engineering ProjectAbdulmajid NiazaiNo ratings yet
- Facial Recognition Using Deep LearningDocument6 pagesFacial Recognition Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Illumination Invariant Face Detection Using Viola Jones AlgorithmDocument4 pagesIllumination Invariant Face Detection Using Viola Jones AlgorithmkvinothscetNo ratings yet
- 19-ENC-41 INN ProjectDocument8 pages19-ENC-41 INN ProjectMaLik AtifNo ratings yet
- 011-Digital Image ProcessingDocument11 pages011-Digital Image ProcessingRaja sekhar polisettiNo ratings yet
- Enhanced Face Recognition Using Euclidean Distance Classification and PCADocument5 pagesEnhanced Face Recognition Using Euclidean Distance Classification and PCA『ẨBŃ』 YEMENNo ratings yet
- Face Recognition Using PCA Based Algorithm and Neural NetworkDocument4 pagesFace Recognition Using PCA Based Algorithm and Neural NetworkBhavya SahayNo ratings yet
- Face RecognitionDocument23 pagesFace RecognitionAbdelfattah Al ZaqqaNo ratings yet
- Facial Detection Using Deep Learning, 1Document7 pagesFacial Detection Using Deep Learning, 1NAVEEN R KPRCAS-B.Sc.(CS&DA)No ratings yet
- Review and Comparison of Face Detection Algorithms: Kirti Dang Shanu SharmaDocument5 pagesReview and Comparison of Face Detection Algorithms: Kirti Dang Shanu SharmaKevin EnriquezNo ratings yet
- Emotion Classification of Facial Images Using Machine Learning ModelsDocument6 pagesEmotion Classification of Facial Images Using Machine Learning ModelsIJRASETPublicationsNo ratings yet
- CS312 Module 4Document21 pagesCS312 Module 4Erica Mae CañeteNo ratings yet
- Face Detection Algorithm ReportDocument9 pagesFace Detection Algorithm Reportdevilr796No ratings yet
- Face RecognitionDocument27 pagesFace RecognitionManendra PatwaNo ratings yet
- Computer Vision MidDocument2 pagesComputer Vision MidHuzair NadeemNo ratings yet
- Abstract:: Case Study of Real Time Based Facial Recognition System For Criminal IdentificationDocument5 pagesAbstract:: Case Study of Real Time Based Facial Recognition System For Criminal IdentificationSachinNo ratings yet
- Opencv: Object Classification - in The Object Classification, We Train A Model On A Dataset ofDocument9 pagesOpencv: Object Classification - in The Object Classification, We Train A Model On A Dataset ofSrinadh ShaikNo ratings yet
- Deep LearningDocument9 pagesDeep LearningAnonymous xMYE0TiNBcNo ratings yet
- Report - EC390Document7 pagesReport - EC390Shivam PrajapatiNo ratings yet
- Cross Pose Facial Recognition Method For Tracking Any Person's Location An ApproachDocument5 pagesCross Pose Facial Recognition Method For Tracking Any Person's Location An ApproachEditor IJTSRDNo ratings yet
- Face Recognition Technology: Abstract-Face Is An Important Part of WhoDocument5 pagesFace Recognition Technology: Abstract-Face Is An Important Part of WhoVinod ArumugamNo ratings yet
- Image Segmentation in Deep LearningDocument12 pagesImage Segmentation in Deep LearningHema maliniNo ratings yet
- CV 4Document8 pagesCV 4normal4formalNo ratings yet
- Pattern RecognitionDocument12 pagesPattern RecognitionHarvinraj MohanapiragashNo ratings yet
- Face Recognition PaperDocument7 pagesFace Recognition PaperPuja RoyNo ratings yet
- Face Recognition Using Haar Cascade Classifier: Varun Garg Kritika GargDocument3 pagesFace Recognition Using Haar Cascade Classifier: Varun Garg Kritika GargVarunNo ratings yet
- Smart Attendance System Usign CNN: Abstract-The Research On The Attendance System Has BeenDocument4 pagesSmart Attendance System Usign CNN: Abstract-The Research On The Attendance System Has BeenSatyanarayan GuptaNo ratings yet
- Face Detection and Recognition TechnologyDocument17 pagesFace Detection and Recognition TechnologyDinesh KumarNo ratings yet
- Intro Face Detect RecognitionDocument43 pagesIntro Face Detect RecognitionHao YuNo ratings yet
- Welcome: Computer EngineeringDocument13 pagesWelcome: Computer EngineeringParikshit SharmaNo ratings yet
- Report On Face Recognition SystemDocument44 pagesReport On Face Recognition Systemnihal100% (1)
- Deepak Result PaperDocument7 pagesDeepak Result Papervikas chawlaNo ratings yet
- Face DetectionDocument91 pagesFace DetectionManisha Ratre MSC3rdNo ratings yet
- Techniques and Applications of Face RecoDocument4 pagesTechniques and Applications of Face Recominthwayhan53No ratings yet
- VA Lecture 23Document42 pagesVA Lecture 23akshittayal24No ratings yet
- Pattern Lec 1Document15 pagesPattern Lec 1armia.ramzy.13No ratings yet
- Face Detection in Python Using OpenCVDocument17 pagesFace Detection in Python Using OpenCVKaruna SriNo ratings yet
- Facial Expression Recognition System Using Haar Cascades ClassifierDocument9 pagesFacial Expression Recognition System Using Haar Cascades ClassifierIJRASETPublicationsNo ratings yet
- Real-Time Face Pose Estimation: Jamaldonado12@espe - Edu.ec Agoaq@espe - Edu.ec Msramrezc@espe - Edu.ecDocument13 pagesReal-Time Face Pose Estimation: Jamaldonado12@espe - Edu.ec Agoaq@espe - Edu.ec Msramrezc@espe - Edu.ecJandres MaldonadoNo ratings yet
- Pca For Image RecognitionDocument5 pagesPca For Image Recognitionnedal altitiNo ratings yet
- Image Recognition and Melody CreationDocument28 pagesImage Recognition and Melody CreationAdarsh SinghNo ratings yet
- Facial Login SystemDocument15 pagesFacial Login Systemrajeevs54785No ratings yet
- Blur and Motion Blur Influence On Face Recognition PerformanceDocument5 pagesBlur and Motion Blur Influence On Face Recognition PerformanceDhanya BNo ratings yet
- NNDL Unit 5Document21 pagesNNDL Unit 5T. S kesavNo ratings yet
- Literature Survey On Criminal Identification System Using Facial Detection and IdentificationDocument7 pagesLiterature Survey On Criminal Identification System Using Facial Detection and IdentificationAdministerNo ratings yet
- An Efficient Real Time Product Recommendation Using Facial Sentiment Analysis PDFDocument6 pagesAn Efficient Real Time Product Recommendation Using Facial Sentiment Analysis PDFManju Ancy John ImmanuelNo ratings yet
- CAD Phase5Document10 pagesCAD Phase5tepemap409No ratings yet
- Document 24Document23 pagesDocument 24snehawish2No ratings yet
- Correlation Method Based PCA Subspace Using Accelerated Binary Particle Swarm Optimization For Enhanced Face RecognitionDocument4 pagesCorrelation Method Based PCA Subspace Using Accelerated Binary Particle Swarm Optimization For Enhanced Face RecognitionEditor IJRITCCNo ratings yet
- Designing of Face Recognition SystemDocument3 pagesDesigning of Face Recognition SystemMuzammil NaeemNo ratings yet
- Image-Based Face Recognition Using Global FeaturesDocument25 pagesImage-Based Face Recognition Using Global FeaturesPrabhakar SinghNo ratings yet
- Computer Vision Module 5Document22 pagesComputer Vision Module 5lukerichman29100% (1)
- Face RecognitionDocument8 pagesFace RecognitionRishikaa RamNo ratings yet
- Facial Recognition Using Machine LearningDocument21 pagesFacial Recognition Using Machine LearningNithishNo ratings yet
- BT4390 Research PaperDocument4 pagesBT4390 Research PaperLucky SharmaNo ratings yet
- Research Paper Version 0Document9 pagesResearch Paper Version 0NidhiNo ratings yet
- AIDocument26 pagesAIsonudinesh2003No ratings yet
- Geometric Feature Learning: Unlocking Visual Insights through Geometric Feature LearningFrom EverandGeometric Feature Learning: Unlocking Visual Insights through Geometric Feature LearningNo ratings yet
- An Approach For Three-Dimensional Visualization Using High-Resolution MRI of The Temporomandibular JointDocument7 pagesAn Approach For Three-Dimensional Visualization Using High-Resolution MRI of The Temporomandibular JointПавло БурлаковNo ratings yet
- PHOTOSHOP QUESTIONS With AnswerDocument10 pagesPHOTOSHOP QUESTIONS With AnswerPrakash GiramkarNo ratings yet
- Nasa's 2Document5 pagesNasa's 2DIEGO IGNACIONo ratings yet
- Colorcode: Color 1 Color 2 Color 3 Color 4 Color 5Document4 pagesColorcode: Color 1 Color 2 Color 3 Color 4 Color 5throwawayyyyyNo ratings yet
- Nombre Del Color Código RGB: AliceblueDocument4 pagesNombre Del Color Código RGB: AliceblueJose Eduardo Vega EstradaNo ratings yet
- Cub 3 DDocument3 pagesCub 3 DvvxNo ratings yet
- AP5 - AA12-EV11 Video Product Review VideosDocument4 pagesAP5 - AA12-EV11 Video Product Review VideosJeffrey GomezNo ratings yet
- Print or Printing DesignDocument38 pagesPrint or Printing Designangel reyes jr.No ratings yet
- Dacolors2v2019bom: Color 1 Color 2 Color 3 Color 4 Color 5Document4 pagesDacolors2v2019bom: Color 1 Color 2 Color 3 Color 4 Color 5srfreezaNo ratings yet
- Edge Enhancement Based Transformer For Medical Image Denoising PDFDocument8 pagesEdge Enhancement Based Transformer For Medical Image Denoising PDFMohammed KharbatliNo ratings yet
- WatercolorDocument8 pagesWatercolorJaviera Villarroel Pérez67% (6)
- 99 Color Combinations by RHR PDFDocument138 pages99 Color Combinations by RHR PDFRH Rumy67% (3)
- Enhancement of Cotton Leaves Images Using Various Filtering TechniquesDocument3 pagesEnhancement of Cotton Leaves Images Using Various Filtering TechniquestresaNo ratings yet
- MAKAUT QP Image ProcessingDocument10 pagesMAKAUT QP Image ProcessingSiddhartha SikderNo ratings yet
- Jahanshahi 2011 - Adaptive Vision-Based Crack DetectionDocument10 pagesJahanshahi 2011 - Adaptive Vision-Based Crack DetectionAntonNo ratings yet
- Computer 8 1st and 2ndDocument79 pagesComputer 8 1st and 2ndAnnatrisha SantiagoNo ratings yet
- Spectral Imaging Revised RemovedDocument6 pagesSpectral Imaging Revised RemovedSilence is BetterNo ratings yet
- Color TheoryDocument8 pagesColor TheoryKrishna Chivukula0% (1)
- 505 Live Photo Editing and Raw Processing With Core ImageDocument310 pages505 Live Photo Editing and Raw Processing With Core ImageBrad KeyesNo ratings yet
- Bab7Document18 pagesBab7Meilinda Eka SuryaniNo ratings yet
- Choropleth Map World Color ScalesDocument7 pagesChoropleth Map World Color ScalesEhli HibreNo ratings yet
- Emtech Group 3Document16 pagesEmtech Group 3Marychiles GlinogaNo ratings yet
- Image Processing Codes For Different AlgorithmsDocument17 pagesImage Processing Codes For Different AlgorithmsSirajus SalekinNo ratings yet
- Introduction To Hitechnic Color Sensor: by Sanjay and Arvind SeshanDocument12 pagesIntroduction To Hitechnic Color Sensor: by Sanjay and Arvind SeshanCyber GloryNo ratings yet
- Rockchip Color Optimization Guide ISP2x en v1.2.1Document54 pagesRockchip Color Optimization Guide ISP2x en v1.2.1cvetaevvitaliyNo ratings yet
- Theory of Images and Digital ProcessingDocument12 pagesTheory of Images and Digital ProcessingBasheq TarifiNo ratings yet
- A Short History of Color Theory: Rune MadsenDocument34 pagesA Short History of Color Theory: Rune MadsenAlberto Adrián SchianoNo ratings yet
- 2018 Brand Guide UpdatedDocument30 pages2018 Brand Guide Updatedapi-95653109No ratings yet
- ArcGIS To R Spatial CheatSheet PDFDocument1 pageArcGIS To R Spatial CheatSheet PDFVicca KarolinoeritaNo ratings yet