
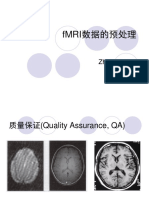
价值迭代求解MDP
价值迭代求解MDP
You might also like
- 价值迭代求解MDPDocument22 pages价值迭代求解MDPLeqing LiNo ratings yet
- 马尔科夫决策过程 录屏Document26 pages马尔科夫决策过程 录屏Leqing LiNo ratings yet
- 马尔科夫决策过程-录屏Document26 pages马尔科夫决策过程-录屏Leqing LiNo ratings yet
- 2 TopsisDocument17 pages2 TopsisAn-Sheng JhangNo ratings yet
- INFO AI Ch3Document99 pagesINFO AI Ch3rojen003No ratings yet
- INFO AI Ch2-1Document81 pagesINFO AI Ch2-1rojen003No ratings yet
- 强化学习基础 张伟楠Document109 pages强化学习基础 张伟楠Yang zaihuiNo ratings yet
- Chap 1 Black-Scholes定價理論Document25 pagesChap 1 Black-Scholes定價理論Micius LiuNo ratings yet
- 2 模糊综合评价Document30 pages2 模糊综合评价An-Sheng JhangNo ratings yet
- 2 全连接神经网络Document39 pages2 全连接神经网络shuhuifang2023No ratings yet
- Original Class Notes1 6-Linear-Function-With-Parabolic-Blends-1 - Lecture-6Document17 pagesOriginal Class Notes1 6-Linear-Function-With-Parabolic-Blends-1 - Lecture-6yihao11223366No ratings yet
- Slides 2-5 Multinomial Response ModelDocument34 pagesSlides 2-5 Multinomial Response Modelcao xiuzhenNo ratings yet
- Section 4 Calculation of Matrix Function ValuesDocument4 pagesSection 4 Calculation of Matrix Function Values2315606389No ratings yet
- 2 熵权法Document12 pages2 熵权法An-Sheng JhangNo ratings yet
- Game Theory Lecture 3 NE and Best Response 2 - 2020Document18 pagesGame Theory Lecture 3 NE and Best Response 2 - 2020s20dqimel38No ratings yet
- ch4 伍6版 多元分析-推断Document28 pagesch4 伍6版 多元分析-推断官露No ratings yet
- CH 23Document1 pageCH 23澪式ZeroNo ratings yet
- 重点打印Document24 pages重点打印rojen003No ratings yet
- 6 神经网络Document28 pages6 神经网络应河No ratings yet
- 超松弛迭代法中松弛因子ω的选取方法Document4 pages超松弛迭代法中松弛因子ω的选取方法nemobe1756No ratings yet
- 20230519_FrugalGPT-v2_穷人怎么用省钱的方法来使用ChatGPTDocument13 pages20230519_FrugalGPT-v2_穷人怎么用省钱的方法来使用ChatGPTMiles ChenNo ratings yet
- Section 3: Using Gail's Circle Theorem To Isolate EigenvaluesDocument3 pagesSection 3: Using Gail's Circle Theorem To Isolate Eigenvalues2315606389No ratings yet
- tg day1 数学专题Document39 pagestg day1 数学专题王淙润No ratings yet
- Probabilistic Principal Component Analysis - SlideDocument14 pagesProbabilistic Principal Component Analysis - Slide??No ratings yet
- 计 算 物 理 Com仞Putati O埋NalDocument8 pages计 算 物 理 Com仞Putati O埋Nal蔡蓁羚No ratings yet
- 现代控制理论 Qinghua UniversityDocument654 pages现代控制理论 Qinghua UniversityLeqing LiNo ratings yet
- 计算机辅助的动画中间画面生成技术Document43 pages计算机辅助的动画中间画面生成技术1355446596No ratings yet
- 博弈论5Document16 pages博弈论5973821045No ratings yet
- 作业题解答Document14 pages作业题解答biriv77958No ratings yet
- 2 3-朴素贝叶斯分类Document50 pages2 3-朴素贝叶斯分类chengkai yuNo ratings yet
- ESKF Attitude AlgorithmDocument4 pagesESKF Attitude Algorithm张毅No ratings yet
- INFO AI Ch2Document77 pagesINFO AI Ch2rojen003No ratings yet
- 密码学系列 第8课:ZkSnark Groth16证明系统Document23 pages密码学系列 第8课:ZkSnark Groth16证明系统hanlong yeNo ratings yet
- UCAS AI模式识别2021 4 参数估计Document40 pagesUCAS AI模式识别2021 4 参数估计jzuozhouNo ratings yet
- 01 Opt DZWDocument53 pages01 Opt DZWRyujouNo ratings yet
- 第6章 Logistic回归Document75 pages第6章 Logistic回归Yancy YinNo ratings yet
- Preprocessing of Fmri Data - 2023 - MoDocument94 pagesPreprocessing of Fmri Data - 2023 - MoSerena LeeNo ratings yet
- 飞行器气动设计实践报告Document26 pages飞行器气动设计实践报告杨跃波No ratings yet
- 4 1 决策智能:任务与技术概览Document35 pages4 1 决策智能:任务与技术概览刘向阳No ratings yet
- Game Theory Lecture 4 NE Applications - 2020Document26 pagesGame Theory Lecture 4 NE Applications - 2020s20dqimel38No ratings yet
- If and ForDocument36 pagesIf and Fortr24561482No ratings yet
- 第六讲 指数与指数函数Document4 pages第六讲 指数与指数函数StefabrinaNo ratings yet
- Section 1 Using Householder Transform For QR DecompositionDocument4 pagesSection 1 Using Householder Transform For QR Decomposition2315606389No ratings yet
- 934 e 66 F 591 F 925 EcefecDocument9 pages934 e 66 F 591 F 925 Ecefecapi-413547048No ratings yet
- Slides 2-3 Binary Response ModelDocument41 pagesSlides 2-3 Binary Response Modelcao xiuzhenNo ratings yet
- 经典卷积神经网络C8Document66 pages经典卷积神经网络C8wd3198097124No ratings yet
- 置信传播算法在LDPC码中的应用Document24 pages置信传播算法在LDPC码中的应用rogger golNo ratings yet
- 6 支持向量机Document23 pages6 支持向量机wem7wangNo ratings yet
- 3选择与循环Document98 pages3选择与循环Riley LeoNo ratings yet
- Fonction LNDocument1 pageFonction LNviperisusefulNo ratings yet
- 複擺預報Document3 pages複擺預報林家凱No ratings yet
- 1 机器学习基础Document43 pages1 机器学习基础shuhuifang2023No ratings yet
- Nasri Et GatelDocument8 pagesNasri Et GatelIkram RaissiNo ratings yet
- 机器学习材料Document62 pages机器学习材料yiqingli698No ratings yet
- Ch9 Nonp CodeDocument25 pagesCh9 Nonp Codesarah20021022No ratings yet
- 工程數學作業 (3) 第2-8與第十一章 (截止日期1121218)Document6 pages工程數學作業 (3) 第2-8與第十一章 (截止日期1121218)劉威辰No ratings yet
- 第四讲 有限单元法IDocument12 pages第四讲 有限单元法IwangxiaosongtongjiNo ratings yet
- 曲线运动Document6 pages曲线运动JR3A Grace Low Shing WeiNo ratings yet
- 實驗13Document23 pages實驗13KayleeNo ratings yet
- 1.5.1 电功率与能量Document11 pages1.5.1 电功率与能量Leqing LiNo ratings yet
- 我所理解的流体力学 第四次印刷Document298 pages我所理解的流体力学 第四次印刷Leqing LiNo ratings yet
- 2.7.1 电阻的Δ形Y形连接等效Document7 pages2.7.1 电阻的Δ形Y形连接等效Leqing LiNo ratings yet
- 079 金兹堡朗道方程Document617 pages079 金兹堡朗道方程Leqing LiNo ratings yet
- 015 傅里叶积分算子理论及其应用Document247 pages015 傅里叶积分算子理论及其应用Leqing LiNo ratings yet
- [控制论].[最优控制计算方法]Document225 pages[控制论].[最优控制计算方法]Leqing LiNo ratings yet
- 021 微分动力系统原理Document355 pages021 微分动力系统原理Leqing LiNo ratings yet
- 035 仿微分算子引论Document216 pages035 仿微分算子引论Leqing LiNo ratings yet
- 国际象棋中局妙手:国际象棋智商测验 good oneDocument152 pages国际象棋中局妙手:国际象棋智商测验 good oneLeqing LiNo ratings yet
- 034 反应扩散方程引论Document507 pages034 反应扩散方程引论Leqing LiNo ratings yet
- 057 半群的S系理论Document321 pages057 半群的S系理论Leqing LiNo ratings yet
- 033 非线性发展方程Document238 pages033 非线性发展方程Leqing LiNo ratings yet
- 体积上张量场场论 01 曲线坐标系Document17 pages体积上张量场场论 01 曲线坐标系Leqing LiNo ratings yet
- 014 微分方程定性理论Document556 pages014 微分方程定性理论Leqing LiNo ratings yet
- 032 代数拓扑与示性类Document134 pages032 代数拓扑与示性类Leqing LiNo ratings yet
- 023 模型论基础Document248 pages023 模型论基础Leqing LiNo ratings yet
- 008 有限群构造 上册Document436 pages008 有限群构造 上册Leqing LiNo ratings yet
- 005 多元统计分析引论Document590 pages005 多元统计分析引论Leqing LiNo ratings yet
- 009 有限群构造 下册Document301 pages009 有限群构造 下册Leqing LiNo ratings yet
- 024 递归论Document315 pages024 递归论Leqing LiNo ratings yet
- 029 同调代数Document379 pages029 同调代数Leqing LiNo ratings yet
- 【课件】数字电子技术基础 - 华中科技Document2,614 pages【课件】数字电子技术基础 - 华中科技Leqing LiNo ratings yet
- 【课件】信号与系统课堂讲义Document199 pages【课件】信号与系统课堂讲义Leqing LiNo ratings yet
- 马尔科夫决策过程 录屏Document26 pages马尔科夫决策过程 录屏Leqing LiNo ratings yet
- 【课件】信号与系统PPTDocument301 pages【课件】信号与系统PPTLeqing LiNo ratings yet
- AlphaZero实践 中国象棋(附论文翻译)Document40 pagesAlphaZero实践 中国象棋(附论文翻译)Leqing LiNo ratings yet
- 【课件】模拟电子技术 - 北京交通大学Document1,457 pages【课件】模拟电子技术 - 北京交通大学Leqing LiNo ratings yet
- Tcp Ip详解卷iDocument433 pagesTcp Ip详解卷iLeqing LiNo ratings yet
- Tcp Ip详解卷iiDocument887 pagesTcp Ip详解卷iiLeqing LiNo ratings yet
- 阿里巴巴管理三板斧Document252 pages阿里巴巴管理三板斧motoxt889No ratings yet
- 結構分析 Structural AnalysisDocument48 pages結構分析 Structural AnalysisSTM WorksNo ratings yet
- 14 教案Document6 pages14 教案siawNo ratings yet
- GD&T详解Document98 pagesGD&T详解jamesliouNo ratings yet






























































![[控制论].[最优控制计算方法]](https://imgv2-1-f.scribdassets.com/img/document/749397061/149x198/0dafc2e9af/1720620345?v=1)


























Download as pptx, pdf, or txt
You might also like
- 价值迭代求解MDPDocument22 pages价值迭代求解MDPLeqing LiNo ratings yet
- 马尔科夫决策过程 录屏Document26 pages马尔科夫决策过程 录屏Leqing LiNo ratings yet
- 马尔科夫决策过程-录屏Document26 pages马尔科夫决策过程-录屏Leqing LiNo ratings yet
- 2 TopsisDocument17 pages2 TopsisAn-Sheng JhangNo ratings yet
- INFO AI Ch3Document99 pagesINFO AI Ch3rojen003No ratings yet
- INFO AI Ch2-1Document81 pagesINFO AI Ch2-1rojen003No ratings yet
- 强化学习基础 张伟楠Document109 pages强化学习基础 张伟楠Yang zaihuiNo ratings yet
- Chap 1 Black-Scholes定價理論Document25 pagesChap 1 Black-Scholes定價理論Micius LiuNo ratings yet
- 2 模糊综合评价Document30 pages2 模糊综合评价An-Sheng JhangNo ratings yet
- 2 全连接神经网络Document39 pages2 全连接神经网络shuhuifang2023No ratings yet
- Original Class Notes1 6-Linear-Function-With-Parabolic-Blends-1 - Lecture-6Document17 pagesOriginal Class Notes1 6-Linear-Function-With-Parabolic-Blends-1 - Lecture-6yihao11223366No ratings yet
- Slides 2-5 Multinomial Response ModelDocument34 pagesSlides 2-5 Multinomial Response Modelcao xiuzhenNo ratings yet
- Section 4 Calculation of Matrix Function ValuesDocument4 pagesSection 4 Calculation of Matrix Function Values2315606389No ratings yet
- 2 熵权法Document12 pages2 熵权法An-Sheng JhangNo ratings yet
- Game Theory Lecture 3 NE and Best Response 2 - 2020Document18 pagesGame Theory Lecture 3 NE and Best Response 2 - 2020s20dqimel38No ratings yet
- ch4 伍6版 多元分析-推断Document28 pagesch4 伍6版 多元分析-推断官露No ratings yet
- CH 23Document1 pageCH 23澪式ZeroNo ratings yet
- 重点打印Document24 pages重点打印rojen003No ratings yet
- 6 神经网络Document28 pages6 神经网络应河No ratings yet
- 超松弛迭代法中松弛因子ω的选取方法Document4 pages超松弛迭代法中松弛因子ω的选取方法nemobe1756No ratings yet
- 20230519_FrugalGPT-v2_穷人怎么用省钱的方法来使用ChatGPTDocument13 pages20230519_FrugalGPT-v2_穷人怎么用省钱的方法来使用ChatGPTMiles ChenNo ratings yet
- Section 3: Using Gail's Circle Theorem To Isolate EigenvaluesDocument3 pagesSection 3: Using Gail's Circle Theorem To Isolate Eigenvalues2315606389No ratings yet
- tg day1 数学专题Document39 pagestg day1 数学专题王淙润No ratings yet
- Probabilistic Principal Component Analysis - SlideDocument14 pagesProbabilistic Principal Component Analysis - Slide??No ratings yet
- 计 算 物 理 Com仞Putati O埋NalDocument8 pages计 算 物 理 Com仞Putati O埋Nal蔡蓁羚No ratings yet
- 现代控制理论 Qinghua UniversityDocument654 pages现代控制理论 Qinghua UniversityLeqing LiNo ratings yet
- 计算机辅助的动画中间画面生成技术Document43 pages计算机辅助的动画中间画面生成技术1355446596No ratings yet
- 博弈论5Document16 pages博弈论5973821045No ratings yet
- 作业题解答Document14 pages作业题解答biriv77958No ratings yet
- 2 3-朴素贝叶斯分类Document50 pages2 3-朴素贝叶斯分类chengkai yuNo ratings yet
- ESKF Attitude AlgorithmDocument4 pagesESKF Attitude Algorithm张毅No ratings yet
- INFO AI Ch2Document77 pagesINFO AI Ch2rojen003No ratings yet
- 密码学系列 第8课:ZkSnark Groth16证明系统Document23 pages密码学系列 第8课:ZkSnark Groth16证明系统hanlong yeNo ratings yet
- UCAS AI模式识别2021 4 参数估计Document40 pagesUCAS AI模式识别2021 4 参数估计jzuozhouNo ratings yet
- 01 Opt DZWDocument53 pages01 Opt DZWRyujouNo ratings yet
- 第6章 Logistic回归Document75 pages第6章 Logistic回归Yancy YinNo ratings yet
- Preprocessing of Fmri Data - 2023 - MoDocument94 pagesPreprocessing of Fmri Data - 2023 - MoSerena LeeNo ratings yet
- 飞行器气动设计实践报告Document26 pages飞行器气动设计实践报告杨跃波No ratings yet
- 4 1 决策智能:任务与技术概览Document35 pages4 1 决策智能:任务与技术概览刘向阳No ratings yet
- Game Theory Lecture 4 NE Applications - 2020Document26 pagesGame Theory Lecture 4 NE Applications - 2020s20dqimel38No ratings yet
- If and ForDocument36 pagesIf and Fortr24561482No ratings yet
- 第六讲 指数与指数函数Document4 pages第六讲 指数与指数函数StefabrinaNo ratings yet
- Section 1 Using Householder Transform For QR DecompositionDocument4 pagesSection 1 Using Householder Transform For QR Decomposition2315606389No ratings yet
- 934 e 66 F 591 F 925 EcefecDocument9 pages934 e 66 F 591 F 925 Ecefecapi-413547048No ratings yet
- Slides 2-3 Binary Response ModelDocument41 pagesSlides 2-3 Binary Response Modelcao xiuzhenNo ratings yet
- 经典卷积神经网络C8Document66 pages经典卷积神经网络C8wd3198097124No ratings yet
- 置信传播算法在LDPC码中的应用Document24 pages置信传播算法在LDPC码中的应用rogger golNo ratings yet
- 6 支持向量机Document23 pages6 支持向量机wem7wangNo ratings yet
- 3选择与循环Document98 pages3选择与循环Riley LeoNo ratings yet
- Fonction LNDocument1 pageFonction LNviperisusefulNo ratings yet
- 複擺預報Document3 pages複擺預報林家凱No ratings yet
- 1 机器学习基础Document43 pages1 机器学习基础shuhuifang2023No ratings yet
- Nasri Et GatelDocument8 pagesNasri Et GatelIkram RaissiNo ratings yet
- 机器学习材料Document62 pages机器学习材料yiqingli698No ratings yet
- Ch9 Nonp CodeDocument25 pagesCh9 Nonp Codesarah20021022No ratings yet
- 工程數學作業 (3) 第2-8與第十一章 (截止日期1121218)Document6 pages工程數學作業 (3) 第2-8與第十一章 (截止日期1121218)劉威辰No ratings yet
- 第四讲 有限单元法IDocument12 pages第四讲 有限单元法IwangxiaosongtongjiNo ratings yet
- 曲线运动Document6 pages曲线运动JR3A Grace Low Shing WeiNo ratings yet
- 實驗13Document23 pages實驗13KayleeNo ratings yet
- 1.5.1 电功率与能量Document11 pages1.5.1 电功率与能量Leqing LiNo ratings yet
- 我所理解的流体力学 第四次印刷Document298 pages我所理解的流体力学 第四次印刷Leqing LiNo ratings yet
- 2.7.1 电阻的Δ形Y形连接等效Document7 pages2.7.1 电阻的Δ形Y形连接等效Leqing LiNo ratings yet
- 079 金兹堡朗道方程Document617 pages079 金兹堡朗道方程Leqing LiNo ratings yet
- 015 傅里叶积分算子理论及其应用Document247 pages015 傅里叶积分算子理论及其应用Leqing LiNo ratings yet
- [控制论].[最优控制计算方法]Document225 pages[控制论].[最优控制计算方法]Leqing LiNo ratings yet
- 021 微分动力系统原理Document355 pages021 微分动力系统原理Leqing LiNo ratings yet
- 035 仿微分算子引论Document216 pages035 仿微分算子引论Leqing LiNo ratings yet
- 国际象棋中局妙手:国际象棋智商测验 good oneDocument152 pages国际象棋中局妙手:国际象棋智商测验 good oneLeqing LiNo ratings yet
- 034 反应扩散方程引论Document507 pages034 反应扩散方程引论Leqing LiNo ratings yet
- 057 半群的S系理论Document321 pages057 半群的S系理论Leqing LiNo ratings yet
- 033 非线性发展方程Document238 pages033 非线性发展方程Leqing LiNo ratings yet
- 体积上张量场场论 01 曲线坐标系Document17 pages体积上张量场场论 01 曲线坐标系Leqing LiNo ratings yet
- 014 微分方程定性理论Document556 pages014 微分方程定性理论Leqing LiNo ratings yet
- 032 代数拓扑与示性类Document134 pages032 代数拓扑与示性类Leqing LiNo ratings yet
- 023 模型论基础Document248 pages023 模型论基础Leqing LiNo ratings yet
- 008 有限群构造 上册Document436 pages008 有限群构造 上册Leqing LiNo ratings yet
- 005 多元统计分析引论Document590 pages005 多元统计分析引论Leqing LiNo ratings yet
- 009 有限群构造 下册Document301 pages009 有限群构造 下册Leqing LiNo ratings yet
- 024 递归论Document315 pages024 递归论Leqing LiNo ratings yet
- 029 同调代数Document379 pages029 同调代数Leqing LiNo ratings yet
- 【课件】数字电子技术基础 - 华中科技Document2,614 pages【课件】数字电子技术基础 - 华中科技Leqing LiNo ratings yet
- 【课件】信号与系统课堂讲义Document199 pages【课件】信号与系统课堂讲义Leqing LiNo ratings yet
- 马尔科夫决策过程 录屏Document26 pages马尔科夫决策过程 录屏Leqing LiNo ratings yet
- 【课件】信号与系统PPTDocument301 pages【课件】信号与系统PPTLeqing LiNo ratings yet
- AlphaZero实践 中国象棋(附论文翻译)Document40 pagesAlphaZero实践 中国象棋(附论文翻译)Leqing LiNo ratings yet
- 【课件】模拟电子技术 - 北京交通大学Document1,457 pages【课件】模拟电子技术 - 北京交通大学Leqing LiNo ratings yet
- Tcp Ip详解卷iDocument433 pagesTcp Ip详解卷iLeqing LiNo ratings yet
- Tcp Ip详解卷iiDocument887 pagesTcp Ip详解卷iiLeqing LiNo ratings yet
- 阿里巴巴管理三板斧Document252 pages阿里巴巴管理三板斧motoxt889No ratings yet
- 結構分析 Structural AnalysisDocument48 pages結構分析 Structural AnalysisSTM WorksNo ratings yet
- 14 教案Document6 pages14 教案siawNo ratings yet
- GD&T详解Document98 pagesGD&T详解jamesliouNo ratings yet